ID3 (алгоритм)
ID3 (Iterative Dichotomiser 3) — це алгоритм, розроблений Росом Куінланом, який використовується для генерації дерев рішень у машинному навчанні з деякого набору даних.[1] ID3 є попередником алгоритму C4.5 та зазвичай використовується в областях машинного навчання і обробки природної мови.
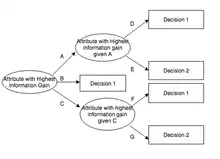
Алгоритм
На початку роботи алгоритму будується дерево з початковою множиною у кореневому вузлі. На кожній ітерації алгоритму, він перебирає усі невикористані атрибути множини та обчислює ентропію (або інформаційний приріст ) цих атрибутів. Потім він вибирає атрибут з найменшим значенням ентропії (або найбільшим інформаційним виграшем). Потім проводиться розбиття множини за вибраним атрибутом для отримання підмножин даних. (Наприклад, вузол може бути розбитий на дочірні вузли на підставі підмножин населення, вік яких менше 50, від 50 до 100 і більше 100.) Алгоритм продовжує рекурсивно виконуватись на кожній підмножині, враховуючи лише ті атрибути, які раніше не були вибрані.



Рекурсія на підмножині може зупинитися в одному з таких випадків:
- Кожен елемент у підмножині належить до одного класу; в цьому випадку вузол перетворюється в листовий вузол і позначається класом прикладів.
- Більше немає атрибутів для вибору, але приклади ще не належать до одного класу. У цьому випадку вузол стає листовим вузлом і позначається найпоширенішим класом прикладів у підмножині.
- У підмножині немає прикладів: це трапляється, коли жодного прикладу у батьківській множині не знайдено, щоб відповідати певному значенню вибраного атрибута. Прикладом може бути відсутність особи серед населення віком понад 100 років. Потім створюється листовий вузол, який позначається найпоширенішим класом прикладів у множині батьківського вузла.
Алгоритм будує дерево рішень, де нетермінальні вузли (внутрішні вузли) представляють вибраний атрибут, на якому дані були розділені, а термінальні вузли (листові вузли) — мітку класу кінцевої підмножини цього вузла розгалуження.
Опис
- Обчислити ентропію кожного атрибута набору даних .
- Розділити множину на підмножини, використовуючи атрибут, для якого вислідна ентропія після розбиття зведена до мінімуму; або, що еквівалентно, інформаційний приріст є максимальним.
- Створити вузол дерева рішень, що містить цей атрибут.
- Повторити алгоритм на підмножинах, використовуючи атрибути, що залишилися.

Псевдокод
ID3 (Приклади, Цільові_Атрибути, Атрибути)
Створити кореневий вузол для дерева.
Якщо всі приклади додатні, повернути дерево з міткою = «+».
Якщо всі приклади від'ємні, повернути дерево з міткою = «-».
Якщо множина атрибутів порожня, повернути дерево з міткою = найбільш поширене значення цільового атрибута в прикладах.
Інакше
← Атрибут, який найкраще класифікує приклади.
Встановити значення кореня = .
Для кожного можливого значення множини
Додати нову гілку під коренем, що відповідає перевірці .
Нехай буде підмножиною прикладів зі значенням .
Якщо множина порожня, тоді
Додати під новою гілкою листовий вузол з міткою = найбільш поширене значення цільового атрибута в прикладах.
Інакше
Додати під новою гілкою піддерево ID3 (, Цільові_Атрибути, Атрибути )
Повернути корінь






Властивості
ID3 не гарантує оптимального рішення. Він може сходитися до локального оптимуму. Він використовує жадібну стратегію, вибираючи локальний кращий атрибут для розбиття множини даних на кожній ітерації. Оптимальність алгоритму може бути покращена шляхом використання пошуку з вертанням під час пошуку оптимального дерева рішень, але це може призвести до погіршення швидкості роботи.
ID3 може перенавчитися. Для уникнення перенавчання варто надавати перевагу меншим деревам рішень замість великих. Цей алгоритм зазвичай будує невеликі дерева, але він не завжди дає найменше дерево рішень.
ID3 важче використовувати на неперервних даних. Якщо значення будь-якого атрибута неперервні, то існує багато місць для розбиття даних за цим атрибутом і пошук найкращого значення для розбиття може зайняти багато часу.
Використання
Алгоритм ID3 навчається на наборі даних для створення дерева рішень, яке зберігається в пам'яті. Під час виконання, це дерево рішень використовується для класифікації нових тестових даних (векторів ознак) шляхом обходу дерева рішень, використовуючи ознаки початкових даних, щоб прийти до листового вузла. Тестові дані класифікуються класом термінального вузла.
Метрики
Ентропія
Ентропія — це міра невизначеності в наборі даних (тобто ентропія характеризує набір даних ).

Де
- — набір даних, для якого розраховується ентропія.
- — множина класів у .
- — відношення числа елементів у класі до числа елементів у множині .



Коли , множина відмінно класифікована (тобто всі елементи належать до одного класу).

У алгоритмі ID3 ентропія обчислюється для кожного атрибута. На кожній ітерації атрибут з найменшою ентропією використовується для розбиття множини . У теорії інформації ентропія вимірює кількість інформації, яку очікують отримати при вимірюванні випадкової величини. Постійна величина має нульову ентропію, оскільки її розподіл відомий. Навпаки, рівномірно розподілена випадкова величина (дискретно або неперервно рівномірна) має максимальну ентропію. Тому, чим більше ентропія у вузлі, тим менше ми маємо відомої інформації про класифікацію даних та більший потенціал для поліпшення класифікації на даному етапі дерева.
ID3 — це жадібний евристичний алгоритм, що виконує пошук за першим найкращим збігом для локально оптимальних значень ентропії. Його точність можна поліпшити шляхом попередньої обробки даних.
Інформаційний приріст
Інформаційний приріст — це міра різниці ентропії початкової множини та ентропії множини після розбиття за атрибутом .


Де
- – підмножини, створені після розбиття множини за атрибутом такі, що .
- – ентропія множини .
- – ентропія підмножини .
- – відношення числа елементів у до числа елементів у множині .






У ID3 для кожного атрибута замість ентропії може бути обчислений інформаційний приріст. Атрибут з найбільшим інформаційним приростом використовується для розбиття множини .
Примітки
- Quinlan, J. R. 1986. Induction of Decision Trees. Mach. Learn. 1, 1 (Mar. 1986), 81–106
- Taggart, Allison J; DeSimone, Alec M; Shih, Janice S; Filloux, Madeleine E; Fairbrother, William G (17 червня 2012). Large-scale mapping of branchpoints in human pre-mRNA transcripts in vivo. Nature Structural & Molecular Biology 19 (7): 719–721. ISSN 1545-9993. PMC 3465671. PMID 22705790. doi:10.1038/nsmb.2327.
Література
- Mitchell, Tom Michael (1997). Machine Learning. New York, NY: McGraw-Hill. с. 55–58. ISBN 0070428077. OCLC 36417892.
- Grzymala-Busse, Jerzy W. (February 1993). Selected Algorithms of Machine Learning from Examples. Fundamenta Informaticae. 18(2): 193–207 — через ResearchGate.
Посилання
- Семінари — http://www2.cs.uregina.ca/
- Опис та приклади — http://www.cise.ufl.edu/
- Опис та приклади — http://www.cis.temple.edu/
- Дерева рішень та класифікація політичних партій
- Реалізація ID3 на Python
- Реалізація ID3 на Ruby
- Реалізація ID3 на Common Lisp
- Реалізація ID3 на C#
- Реалізація ID3 на Perl
- Реалізація ID3 на Prolog
- Реалізація ID3 на C (Коментарі на італійській мові)
- Реалізація ID3 на R
- Реалізація ID3 на JavaScript