Дискретний рівномірний розподіл
В теорії ймовірностей і статистиці випадкова величина має дискретний рівномірний розподіл, якщо вона приймає скінченне число значень з однаковими ймовірностями.
| Дискретний рівномірний розподіл | |
|---|---|
 Масова функція розподілу імовірностей для рівномірного розподілу із параметром n = 5 n = 5 де n = b − a + 1 | |
|
Функція розподілу ймовірностей 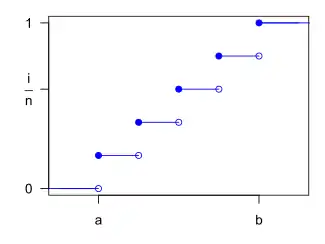 Кумулятивна функція дискретного рівномірного розподілу для n = 5 | |
| Параметри |
|
| Носій функції | |
| Розподіл імовірностей | |
| Функція розподілу ймовірностей (cdf) | |
| Середнє | |
| Медіана | |
| Мода | N/A |
| Дисперсія | |
| Коефіцієнт асиметрії | |
| Коефіцієнт ексцесу | |
| Ентропія | |
| Твірна функція моментів (mgf) | |
| Характеристична функція | |













Якщо випадкова величина може приймати будь-яке з n значень k1,k2,…,kn, тоді це є дискретним рівномірним розподілом. Ймовірність випадання kj дорівнює 1/n. Простим прикладом дискретного рівномірного розподілу є випадання гральної кості. k набуває значень 1, 2, 3, 4, 5, 6 і кожен раз випадає з імовірністю 1/6. У випадку, коли випадкова величина є дійсним числом, то функцію розподілу можна виразити у термінах виродженого розподілу таким чином:


Визначення максимуму
Вибірка із k спостережень отримана із рівномірного розподілу цілих чисел , для якої існує задача оцінити невідомий максимум N. Цю задачу іноді називають задачею про німецький танк, після того як цей метод оцінки максимуму було застосовано для оцінки темпів виробництва німецьких танків під час Другої світової війни.

Незміщена оцінка з мінімальною дисперсією для рівномірного розподілу, яка визначає максимум задається наступним чином

де m є вибірковим максимумом, а k - розмір вибірки, для вибірки без повторного заміщення.[1] Цей приклад можна розглядати як спрощений випадок оцінки максимального інтервалу.
При цьому матимемо дисперсію[1]

тож стандартне відхилення приблизно становить , середній розмір (для сукупності) проміжку між елементами; порівняємо із вищевказаним .


Максимум вибірки є оцінкою максимальної правдоподібності для максимуму сукупності, але, як зазначалося вище, він є зміщеним.
Якщо вибірка не представлена числами, але її можна промаркувати або розрізнити, розмір популяції можливо визначити методом "Зловити/повторити".
Виведення
Для будь-якого цілого числа m такого що k ≤ m ≤ N, імовірність того, що вибірковий максимум буде дорівнювати m можна розрахувати наступним чином. Кількість різних груп із k танків, які можуть бути утворені із загальної кількості з N танків визначається через біноміальний коефіцієнт . Оскільки при такому способі підрахунку, перестановки танків розраховуються лише раз, ми можемо впорядкувати серійні номери і відмітити максимальний з них в кожній вибірці. Аби розрахувати імовірність ми повинні полічити кількість впорядкованих вибірок, які можуть містити останній елемент, який буде дорівнювати m а всі інші k-1 танків мають номери менші або такий що дорівнює m-1. Кількість таких вибірок з k-1 танків які можна отримати із загальної кількості m-1 танків задається біноміальним коефіцієнтом , тож імовірність отримати максимум m становить .



Дано загальну кількість N і розмір вибірки k, математичне сподівання максимуму вибірки визначається як:

де було використано рівняння із трикутником Паскаля .

Із цього рівняння, невідому кількість N можна розрахувати через сподівання і розмір вибірки, наступним чином

Відповідно до лінійності математичного сподівання, отримаємо

і таким чином незміщена оцінка для N отримується за допомогою заміни сподівання на спостереження,

Крім того, що ця оцінка є незміщеною вона також досягає мінімальної дисперсії. Аби показати це, відмітимо спершу, що максимум вибірки є достатньою статистикою для визначення максимуму сукупності, оскільки імовірність P(m;N) задається як функція лише від однієї m. Далі необхідно довести, що статистика m також є повною статистикою, особливим видом достатньої статистики (demonstration pending). Тоді Теорема Лемана-Шеффе передбачає, що є незміщеною оцінкою для N із найменшою дисперсією.[2]

Дисперсія оцінки розраховується як дисперсія вибіркового максимуму

Дисперсія максимуму в свою чергу розраховується із математичних сподівань і . Розрахунок математичного сподівання для є наступним,



де другий терм є математичним сподіванням для . Перший терм можна виразити через k і N,

де була використана заміна і використане рівняння із трикутником Паскаля. Підставлення цього результату і математичного сподівання в рівняння для дає



Тоді можна отримати дисперсію для ,

Зрештою можна розрахувати дисперсію для оцінки ,

Примітки
- Johnson, Roger (1994). Estimating the Size of a Population. Teaching Statistics 16 (2 (Summer)). doi:10.1111/j.1467-9639.1994.tb00688.x. Архів оригіналу за 26 травня 2009. Процитовано 18 березня 2019.
- G. A. Young and R. L Smith (2005) Essentials of Statistical Inference, Cambridge University Press, Cambridge, UK, p. 95
