Інтелектуальний аналіз тексту
Інтелектуальний аналіз тексту (ІАТ, англ. text mining) — напрям інтелектуального аналізу даних (англ. Data Mining) та штучного інтелекту, метою якого є отримання інформації з колекцій текстових документів, ґрунтуючись на застосуванні ефективних, у практичному плані, методів машинного навчання та обробки природної мови. Інтелектуальний аналіз тексту використовує всі ті ж підходи до перероблювання інформації, що й інтелектуальний аналіз даних, однак різниця між цими напрямками проявляється лише в кінцевих методах, а також у тому, що інтелектуальний аналіз даних має справу зі сховищами та базами даних, а не електронними бібліотеками та корпусами текстів.
Завдання інтелектуального аналізу тексту
Ключовими завданнями ІАТ є: категоризація текстів, пошук інформації, обробка змін у колекціях текстів, а також розробка засобів представлення інформації для користувача[1].
Категоризація документів полягає у зіставленні документів з колекції з однією або декількома групами (класами, кластерами) схожих між собою текстів (наприклад, по темі або стилем). Категоризація може відбуватися як за участю людини, так і без неї.
У першому випадку (класифікація документів), система ІАТ повинна віднести тексти до вже визначених (зручних для неї) класів. Для цього необхідно провести навчання з учителем, для чого користувач повинен надати системі ІАТ як перелік класів, так і зразки документів, що належать цим класам.
Другий випадок категоризації називається кластеризацією документів. При цьому система ІАТ повинна сама визначити множину кластерів, за якими можуть бути розподілені тексти, — в машинному навчанні відповідне завдання називається навчанням без вчителя. У цьому випадку користувач повинен повідомити системі ІАТ кількість кластерів, на яке йому хотілося б розбити оброблювану колекцію (передбачається, що в алгоритм програми вже закладена процедура вибору ознак).
Текстова аналітика
Термін текстова аналітика описує набір методів лінгвістики, статистики та машинного навчання, які моделюють і структурують інформаційний зміст текстових джерел для бізнес-аналітики (англ. Business intelligence), розвідувального аналізу даних, дослідження, або розслідування.[2] Цей термін приблизно є синонімом інтелектуального аналізу тексту; насправді, у 2004 році Ронен Фельдман змінив термін 2000 року «інтелектуального аналізу тексту»[3] для опису «текстової аналітики».[4] В даний час термін текстової аналітики частіше застосовується в бізнес-середовищі, тоді як «інтелектуальний аналіз тексту», починаючи з 1980-х років, використовується в деяких з найбільш ранніх областей застосування[5], а саме в дослідженнях у галузі природничих наук та державної розвідки.
Термін «текстова аналітика» також описує застосування текстової аналітики для вирішення бізнес-проблем, незалежно чи в поєднанні з запитом і аналізом впорядкованих, числових даних. Загально відомо, що 80 % інформації, що стосується бізнесу, походить з неструктурованої форми, в першу чергу, з тексту.[6] Ці методи й процеси виявляють і представляють знання — факти, ділові правила і відносини — які в іншому випадку закодовані в текстовій формі та не піддаються автоматизованій обробці.
Процес текстової аналітики
Підзадачі, що становлять більшу частину аналізу тексту, зазвичай охоплюють:
- Інформаційний пошук, або ідентифікація корпусу є підготовчим етапом: збір, або ідентифікація набору текстових матеріалів для аналізу в Інтернеті, або у вигляді файлової системи, бази даних, або вмісту менеджера корпуса (англ. Corpus manager).
- Хоча деякі системи для аналізу текстів застосовують виключно передові статистичні методи, багато інших застосовують більш широку обробку природної мови, таку як розмічування частин мови (англ. Part-of-speech tagging), синтаксичний аналіз та інші типи лінгвістичного аналізу.
- Розпізнавання іменованих сутностей — це використання географічних довідників або статистичних методів для визначення властивостей названих у тексті: людей, організацій, топонімів, біржових символів, певних скорочень, тощо.
- Усунення неоднозначності — використання контекстних підказок — може знадобитися, щоб вирішити, де, наприклад, слово «Форд» може посилатися на колишнього президента США, виробника транспортного засобу, кінозірку, переправу через річку, або інший об'єкт.
- Розпізнавання ідентифікованих об'єктів: такі функції, як телефонні номери, адреси електронної пошти, кількості (з одиницями) можна розрізняти за допомогою регулярних виразів, або інших збігів шаблонів.
- Кластеризація документів: ідентифікація наборів аналогічних текстових документів.[7]
- Кореферентність (англ. Coreference): ідентифікація іменників і інших термінів, що відносяться до одного і того ж об'єкта.
- Зв'язок, факт і подія Видобутку: ідентифікація асоціацій між сутностями та інша інформація в тексті.
- Аналіз тональності тексту передбачає розрізнення суб'єктивного (на відміну від фактичного) матеріалу і вилучення різних форм інформаційної поведінки: почуттів, думок, настроїв і емоцій. Методи аналізу текстів є корисними для аналізу, настрою на рівні суб'єкта, а також для розрізнення власника думки та об'єкта думки.[8]
- Кількісний аналіз тексту — це сукупність методів, що випливають з соціальних наук, де або людина, або комп'ютер витягують семантичні, або граматичні відносини між словами, щоб з'ясувати значення, або стилістичні закономірності, зазвичай, випадкового особистого тексту з метою психологічного профілювання (англ. psychological profiling), тощо.[9]
Застосування
Технологія інтелектуального аналізу тексту в даний час широко застосовується до широкого кола урядових, дослідницьких та бізнес-потреб. Всі три групи можуть використовувати інтелектуальний аналіз тексту для управління документами та пошуку документів, що стосуються їх повсякденної діяльності. Професіонали з правових питань можуть використовувати інтелектуальний аналіз тексту для електронного відкриття. Уряди і військові групи використовують інтелектуальний аналіз тексту для цілей національної безпеки та розвідки. Наукові дослідники об'єднують підходи інтелектуального аналізу тексту в зусиллях для організації великих наборів текстових даних (тобто, розв'язання проблеми неструктурованих даних), для визначення ідей, переданих через текст (наприклад, аналіз тональності тексту у соціальних мережах[10][11][12]) і підтримувати наукові відкриття в галузі природничих наук та в галузібіоінформатики. У бізнесі інтелектуальний аналіз тексту використовується для підтримки конкурентної розвідки та автоматичного розміщення оголошень серед багатьох інших заходів.
Безпека
Багато програмних пакетів інтелектуального аналізу тексту використовуються в системах безпеки, особливо для моніторингу та аналізу текстових джерел в Інтернеті, таких як інтернет-новини, блоги, тощо.[13] Інтелектуальний аналіз тексту також присутній у вивченні шифрування/дешифрування тексту.
Біомедицина
Було описано діапазон застосування інтелектуального аналізу тексту в біомедичній літературі[14], який містить в собі обчислювальні підходи для допомоги в дослідженнях з приєднання білків (англ. protein docking),[15] взаємодій білків,[16][17] та асоціацій білкових хвороб (англ. protein-disease associations)[18]. Крім того, за наявності великих наборів даних пацієнтів у клінічній сфері, наборів даних демографічної інформації в популяційних дослідженнях та в звітах про побічні ефекти, інтелектуальний аналіз тексту може полегшити проведення клінічних досліджень та якість лікування. Алгоритми інтелектуального аналізу тексту можуть полегшити стратифікацію та індексацію конкретних клінічних подій у великих текстових наборах даних пацієнтів з симптомами, побічними ефектами та супутніми захворюваннями з електронних медичних записів, звітів про події та звітів з конкретних діагностичних тестів.[19] Одним з онлайн застосування інтелектуального аналізу текстів у біомедичній літературі є PubGene, загальнодоступна пошукова система, яка поєднує в собі біомедичний інтелектуальний аналіз тексту з візуалізацією мережі.[20][21] GoPubMed — це пошукова система на основі знань для біомедичних текстів. Методи інтелектуального аналізу тексту також дозволяють витягувати невідомі знання з неструктурованих документів у клінічній сфері.[22]
Програмне забезпечення
Методи та програмне забезпечення для інтелектуального аналізу тексту досліджується та розробляється відомими компаніями, серед яких IBM та Microsoft, з метою подальшої автоматизації процесу аналізу, а також різними фірмами, що працюють у сфері пошуку та індексації в цілому, як спосіб поліпшення своїх результатів. У державному секторі великі зусилля були спрямовані на створення програмного забезпечення щодо відстеження та моніторингу терористичної діяльності.[23]
Засоби масової інформації
Інтелектуальний аналіз тексту використовується великими медіа-компаніями, такими як Tribune Company, для уточнення інформації та надання читачам більшого досвіду пошуку, що, у свою чергу, збільшує «липкість» сайту та дохід. Крім того, в серверній частині редактори отримують можливість використовувати, пов'язувати та поширювати новини через властивості, значно збільшуючи можливості для монетизації вмісту.
Бізнес і маркетинг
Інтелектуальний аналіз тексту починають використовувати в маркетингу, зокрема, в аналітичному управлінні відносинами з клієнтами.[24] Coussement і Van den Poel (2008)[25][26] застосовують його для поліпшення моделей прогностичної аналітики для збивання клієнтів.[25] Інтелектуальний аналіз тексту також застосовується в прогнозі дохідності акцій.[27]
Аналіз тональності тексту
Аналіз тональності тексту може включати аналіз огляду фільмів для оцінки того, наскільки сприятливим є огляд фільму.[28] Такий аналіз може потребувати маркованого набору даних, або маркування впливу слів. Для WordNet[29] і ConceptNet[30] були створені ресурси для оцінки афективності слів та концепцій, відповідно. Текст також використовується для виявлення емоцій у відповідній області афективних обчислень.[31] Текстові підходи до афективних обчислень використовувалися на кількох корпусах, таких як оцінки студентів, дитячі розповіді та новини.
Аналіз наукової літератури
Питання інтелектуального аналізу тексту має важливе значення для видавців, які мають великі бази даних інформації, які потребують індексації для пошуку. Особливо це стосується наукових дисциплін, у яких високоспецифічна інформація часто міститься в письмовому тексті. Таким чином, були вжиті ініціативи, такі як пропозиція Nature для відкритого інтерфейсу інтелектуального аналізу тексту (англ. Open Text Mining Interface (OTMI)) та Національний інститут охорони здоров'я в США Document Type Definition (DTD), які забезпечують семантичні сигнали машинам для відповіді на конкретні запити, що містяться в тексті без видалення перешкоди для публічного доступу.
Академічні установи також взяли участь в ініціативі з інтелектуального аналізу тексту:
- Національний центр інтелектуального аналізу тексту є першим у світі відкритим фондом інтелектуального аналізу тексту. Національний центр інтелектуального аналізу тексту управляється Манчестерським університетом[32], у тісній співпраці з Лабораторією Tsujii,[33] Токійським університетом.[34] Національний центр інтелектуального аналізу тексту надає індивідуальні інструменти, дослідницькі засоби та надає консультації академічній спільноті. Вони фінансуються Спільним комітетом з інформаційних систем (JISC) і двома дослідницькими радами Великої Британії (EPSRC & BBSRC). З початку інтелектуальний аналіз тексту фокусувався в біологічних і біомедичних науках, але дослідження з того часу розширилися в області суспільних наук.
- У Сполучених Штатах, Школа інформації в Університеті Каліфорнії в Берклі розробляє програму під назвою BioText, щоб допомогти дослідникам біології в інтелектуальному аналізі тексту.
- Портал аналізу тексту для досліджень (TAPoR), який зараз розміщений в Альбертському університеті, є науковим проектом для каталогізації додатків для аналізу тексту і створення шлюзу для нових дослідників.
Методи аналізу наукової літератури
Обчислювальні методи розроблені для пошуку інформації в науковій літературі. Опубліковані підходи включають методи пошуку,[35] визначення новизни[36] і уточнення омонімів[37] серед технічних звітів.
Цифрові гуманітарні науки та обчислювальна соціологія
Автоматичний аналіз великих текстових корпусів створив можливість для вчених проаналізувати мільйони документів на різних мовах з дуже обмеженим ручним втручанням. Основними технологіями, що надаються, є розбір, машинний переклад, категоризація тем і машинне навчання.
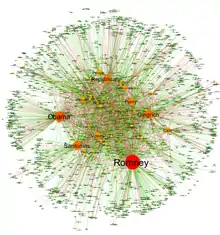
Автоматичний синтаксичний аналіз текстових корпусів дозволив у величезному масштабі витягти суб'єкти та їхні реляційні мережі, перетворивши текстові дані в мережеві дані. Отримані мережі, які можуть містити тисячі вузлів, потім аналізуються за допомогою інструментів з теорії мереж для визначення ключових суб'єктів, ключових спільнот, або сторін, а також загальних властивостей, таких як надійність чи структурна стійкість мережі в цілому, або центральність окремих вузлів.[39] Це автоматизує підхід, впроваджений кількісним описовим аналізом,[40] за допомогою якого об'єкти-дієслово-об'єктні трійні ідентифікуються з парами суб'єктів, пов'язаних дією, або парами, утвореними суб'єктом-об'єктом.[38]
Контент-аналіз вже давно є традиційною частиною соціальних наук та медіа-досліджень. Автоматизація контент-аналізу дозволила революції «великих даних» відбутися в цій галузі, з дослідженнями в соціальних медіа і зміст газет, які включають мільйони новин. Ґендерна упередженість, легкочитність, подібність змісту, переваги читача і навіть настрій були проаналізовані на основі методів інтелектуального аналізу тексту над мільйонами документів.[41][42][43][44][45] Аналіз легкочитності, гендерної упередженості та зміщення теми був продемонстрований у Flaounas et al[46] в якому показують, як різні теми мають різні гендерні упередження та рівні легкочитності; Також було продемонстровано можливість виявлення моделей настрою у великій кількості населення шляхом аналізу вмісту Twitter.[47][48]
Програмне забезпечення
Комп'ютерні програми для інтелектуального аналізу тексту доступні у багатьох комерційних та відкритих компаніях та джерелах. Див. Список програмного забезпечення для інтелектуального аналізу тексту.
Закон про інтелектуальну власність
Ситуація в Європі
Через відсутність гнучкості в європейському законодавстві про авторські права і бази даних, інтелектуальний аналіз авторських робіт (наприклад, інтелектуальний аналіз мережі) без дозволу власника авторських прав є незаконним. У Великій Британії у 2014 році за рекомендацією огляду Hargreaves уряд змінив закон про авторське право[49], щоб дозволити інтелектуальний аналіз тексту, як обмеження і виняток. Це була лише друга країна у світі після Японії, яка у 2009 році запровадила інтелектуальний аналіз, як виняток. Однак, через обмеження Директиви про авторське право, виняток Великої Британії дозволяє інтелектуальний аналіз контенту лише для некомерційних цілей. Закон Великої Британії про авторське право не дозволяє перекрити це положення договірними умовами.
Європейська комісія сприяла обговоренню зацікавлених сторін щодо інтелектуального аналізу тексту та даних у 2013 році під назвою «Ліцензії для Європи»[50]. Той факт, що акцент на розв'язанні цього юридичного питання полягав у видачі ліцензій, а не на обмеженнях та винятках із закону про авторське право, призвело до того, що представники університетів, дослідників, бібліотек, груп громадянського суспільства та видавців з відкритим доступом залишили діалог із зацікавленими сторонами у травні 2013 року.[51]
Ситуація в США
На відміну від Європи, через гнучкість американського закону про авторське право і, зокрема, сумлінного використання, інтелектуальний аналіз тексту в Америці, як і в інших країнах із сумлінним використанням, таких як Ізраїль, Тайвань і Південна Корея, вважається законним. Оскільки інтелектуальний аналіз тексту є перетворювальним — це означає, що він не витісняє оригінальну роботу, а вважається законним при сумлінному використанні. Наприклад, як частина дозволу книг в Google, головний суддя у справі постановив, що проект оцифрування книг з авторськими правами в Google був законним, частково через перетворення, яке показує проект оцифрування — одним із варіантів інтелектуального аналізу тексту та даних.[52]
Вплив
До недавнього часу вебсайти найчастіше використовували текстовий пошук, який знаходить лише документи, що містять конкретні визначені користувачем слова, або фрази. Тепер завдяки використанню семантичної павутини, інтелектуальний аналіз тексту може знайти вміст, заснований на сенсі та контексті (а не просто на конкретному слові). Крім того, програмне забезпечення інтелектуального аналізу тексту можна використовувати для створення великих досьє інформації про конкретних людей та події. Наприклад, великі набори даних на основі отриманих даних зі звітів новин, можуть бути побудовані для полегшення аналізу соціальних мереж, або контррозвідки. Фактично, програмне забезпечення інтелектуального аналізу тексту можна використовувати в якості, подібної до аналітичної розвідки, або дослідницької бібліотеки, хоча і з більш обмеженим аналізом. Інтелектуальний аналіз тексту також використовується в деяких фільтрах спаму для електронної пошти, як спосіб визначення характеристик повідомлень, які, ймовірно, будуть рекламою, або іншим небажаним матеріалом. Інтелектуальний аналіз тексту відіграє важливу роль у визначенні настроїв фінансового ринку.
Майбутнє
Зростає інтерес до багатомовного інтелектуального аналізу даних: здатність отримувати інформацію між мовами та групувати подібні об'єкти з різних мовних джерел відповідно до їхнього значення.
Протягом десятиліть відома проблема використання великої частини «неструктурованої» інформації, яка утворюється на підприємствах.[53] Її визнано ще в самому ранньому визначенні бізнес-аналітики (англ. Business intelligence), в жовтні 1958 р. в статті Ганса Пітера Луна «Система бізнес-аналітики» в журналі IBM, яка описує систему, що буде:
«… використовувати машини для обробки даних для автоматичного абстрагування та автоматичного кодування документів і для створення профілів інтересів для кожної 'точки дії' в організації. І вхідні, і внутрішні документи автоматично абстрагуються, характеризуються словом-шаблоном і відправляються автоматично до відповідних точок дії.»
Проте, оскільки інформаційні системи управління розвивалися з 1960-х років, і коли з'явилася бізнес-аналітика в 80-х і 90-х роках як категорія програмного забезпечення та сфера практичного застосування, акцент робився на числові дані, що зберігаються в реляційних базах даних. Це не дивно: текст у «неструктурованих» документах важко обробляти. Виникнення текстової аналітики в її нинішній формі випливає з перефокусування досліджень наприкінці 1990-х років від розробки алгоритмів до застосування, як описав професор Марті А. Херст у статті «Розпізнавання текстових даних»:[54]
Протягом майже десятиліття обчислювальне лінгвістичне товариство розглядало великі текстові колекції, як ресурс, який необхідно використовувати для створення кращих алгоритмів аналізу тексту. У цій роботі я спробував запровадити новий наголос: використання великих колекцій онлайн-тексту для виявлення нових фактів і тенденцій щодо самого світу. Я вважаю, що для досягнення прогресу, нам не потрібно повністю штучний інтелектуальний аналіз тексту; скоріше, поєднання комп'ютерного і призначеного для користувача аналізу може відкрити двері до нових цікавих результатів.
У заяві Херста 1999 року говориться про необхідність якісного опису стану технології та практики аналізу текстів.
Примітки
- Berry, 2003.
- Архівовано 29 листопада 2009 у Wayback Machine.
- KDD-2000 Workshop on Text Mining - Call for Papers. Cs.cmu.edu. Процитовано 23 лютого 2015.
- Архівовано 3 березня 2012 у Wayback Machine.
- Hobbs, Jerry R.; Walker, Donald E.; Amsler, Robert A. (1982). Natural language access to structured text. Proceedings of the 9th conference on Computational linguistics 1. с. 127–32. doi:10.3115/991813.991833.
- Unstructured Data and the 80 Percent Rule. Breakthrough Analysis. August 2008. Процитовано 23 лютого 2015.
- Chang, Wui Lee; Tay, Kai Meng; Lim, Chee Peng (6 лютого 2017). A New Evolving Tree-Based Model with Local Re-learning for Document Clustering and Visualization. Neural Processing Letters (англ.) 46 (2): 379–409. ISSN 1370-4621. doi:10.1007/s11063-017-9597-3.
- Full Circle Sentiment Analysis. Breakthrough Analysis. 14 червня 2010. Процитовано 23 лютого 2015.
- Mehl, Matthias R. (2006). Quantitative Text Analysis. Handbook of multimethod measurement in psychology. с. 141. ISBN 978-1-59147-318-3. doi:10.1037/11383-011.
- Pang, Bo; Lee, Lillian (2008). Opinion Mining and Sentiment Analysis. Foundations and Trends® in Information Retrieval 2 (1–2): 1–135. ISSN 1554-0669. doi:10.1561/1500000011. Проігноровано невідомий параметр
|citeseerx=(довідка) - Paltoglou, Georgios; Thelwall, Mike (1 вересня 2012). Twitter, MySpace, Digg: Unsupervised Sentiment Analysis in Social Media. ACM Transactions on Intelligent Systems and Technology (TIST) 3 (4): 66. ISSN 2157-6904. doi:10.1145/2337542.2337551.
- Sentiment Analysis in Twitter < SemEval-2017 Task 4. alt.qcri.org (амер.). Процитовано 2 жовтня 2018.
- Zanasi, Alessandro (2009). Virtual Weapons for Real Wars: Text Mining for National Security. Proceedings of the International Workshop on Computational Intelligence in Security for Information Systems CISIS'08. Advances in Soft Computing 53. с. 53. ISBN 978-3-540-88180-3. doi:10.1007/978-3-540-88181-0_7.
- Cohen, K. Bretonnel; Hunter, Lawrence (2008). Getting Started in Text Mining. PLoS Computational Biology 4 (1): e20. PMC 2217579. PMID 18225946. doi:10.1371/journal.pcbi.0040020.
- Badal, V. D; Kundrotas, P. J; Vakser, I. A (2015). Text mining for protein docking. PLoS Computational Biology 11 (12): e1004630. PMC 4674139. PMID 26650466. doi:10.1371/journal.pcbi.1004630.
- Papanikolaou, Nikolas; Pavlopoulos, Georgios A.; Theodosiou, Theodosios; Iliopoulos, Ioannis (2015). Protein–protein interaction predictions using text mining methods. Methods 74: 47–53. ISSN 1046-2023. PMID 25448298. doi:10.1016/j.ymeth.2014.10.026.
- Szklarczyk, Damian; Morris, John H; Cook, Helen; Kuhn, Michael; Wyder, Stefan; Simonovic, Milan; Santos, Alberto; Doncheva, Nadezhda T та ін. (18 жовтня 2016). The STRING database in 2017: quality-controlled protein–protein association networks, made broadly accessible. Nucleic Acids Research (англ.) 45 (D1): D362–D368. ISSN 0305-1048. PMC 5210637. PMID 27924014. doi:10.1093/nar/gkw937.
- Liem, David A.; Murali, Sanjana; Sigdel, Dibakar; Shi, Yu; Wang, Xuan; Shen, Jiaming; Choi, Howard; Caufield, John H.; Wang, Wei; Ping, Peipei; Han, Jiawei (1 жовтня 2018). Phrase mining of textual data to analyze extracellular matrix protein patterns across cardiovascular disease. American Journal of Physiology. Heart and Circulatory Physiology 315 (4): H910–H924. ISSN 1522-1539. PMC 6230912. PMID 29775406. doi:10.1152/ajpheart.00175.2018.
- Van Le, D; Montgomery, J; Kirkby, KC; Scanlan, J (10 серпня 2018). Risk Prediction using Natural Language Processing of Electronic Mental Health Records in an Inpatient Forensic Psychiatry Setting.. Journal of Biomedical Informatics 86: 49–58. PMID 30118855. doi:10.1016/j.jbi.2018.08.007.
- Jenssen, Tor-Kristian; Lægreid, Astrid; Komorowski, Jan; Hovig, Eivind (2001). A literature network of human genes for high-throughput analysis of gene expression. Nature Genetics 28 (1): 21–8. PMID 11326270. doi:10.1038/ng0501-21.
- Masys, Daniel R. (2001). Linking microarray data to the literature. Nature Genetics 28 (1): 9–10. PMID 11326264. doi:10.1038/ng0501-9.
- Renganathan, Vinaitheerthan (2017). Text Mining in Biomedical Domain with Emphasis on Document Clustering. Healthcare Informatics Research 23 (3): 141–146. ISSN 2093-3681. PMC 5572517. PMID 28875048. doi:10.4258/hir.2017.23.3.141.
- Архівовано 4 жовтня 2013 у Wayback Machine.
- Text Analytics. Medallia. Процитовано 23 лютого 2015.
- Coussement, Kristof; Van Den Poel, Dirk (2008). Integrating the voice of customers through call center emails into a decision support system for churn prediction. Information & Management 45 (3): 164–74. doi:10.1016/j.im.2008.01.005. Проігноровано невідомий параметр
|citeseerx=(довідка) - Coussement, Kristof; Van Den Poel, Dirk (2008). Improving customer complaint management by automatic email classification using linguistic style features as predictors. Decision Support Systems 44 (4): 870–82. doi:10.1016/j.dss.2007.10.010.
- Ramiro H. Gálvez; Agustín Gravano (2017). Assessing the usefulness of online message board mining in automatic stock prediction systems. Journal of Computational Science 19: 1877–7503. doi:10.1016/j.jocs.2017.01.001.
- Pang, Bo; Lee, Lillian; Vaithyanathan, Shivakumar (2002). Thumbs up?. Proceedings of the ACL-02 conference on Empirical methods in natural language processing 10. с. 79–86. doi:10.3115/1118693.1118704.
- Alessandro Valitutti; Carlo Strapparava; Oliviero Stock (2005). Developing Affective Lexical Resources. PsychNology Journal 2 (1): 61–83. Архів оригіналу за 20 вересня 2018. Процитовано 29 березня 2019.
- Erik Cambria; Robert Speer; Catherine Havasi; Amir Hussain (2010). SenticNet: a Publicly Available Semantic Resource for Opinion Mining. Proceedings of AAAI CSK. с. 14–18.
- Calvo, Rafael A; d'Mello, Sidney (2010). Affect Detection: An Interdisciplinary Review of Models, Methods, and Their Applications. IEEE Transactions on Affective Computing 1 (1): 18–37. doi:10.1109/T-AFFC.2010.1.
- The University of Manchester. Manchester.ac.uk. Процитовано 23 лютого 2015.
- Tsujii Laboratory. Tsujii.is.s.u-tokyo.ac.jp. Архів оригіналу за 7 березня 2012. Процитовано 23 лютого 2015.
- The University of Tokyo. UTokyo. Процитовано 23 лютого 2015.
- Shen, Jiaming; Xiao, Jinfeng; He, Xinwei; Shang, Jingbo; Sinha, Saurabh; Han, Jiawei (27 червня 2018). Entity Set Search of Scientific Literature: An Unsupervised Ranking Approach. ACM. с. 565–574. ISBN 9781450356572. doi:10.1145/3209978.3210055.
- Walter, Lothar; Radauer, Alfred; Moehrle, Martin G. (6 лютого 2017). The beauty of brimstone butterfly: novelty of patents identified by near environment analysis based on text mining. Scientometrics (англ.) 111 (1): 103–115. ISSN 0138-9130. doi:10.1007/s11192-017-2267-4.
- Roll, Uri; Correia, Ricardo A.; Berger-Tal, Oded (10 березня 2018). Using machine learning to disentangle homonyms in large text corpora. Conservation Biology (англ.) 32 (3): 716–724. ISSN 0888-8892. PMID 29086438. doi:10.1111/cobi.13044.
- Automated analysis of the US presidential elections using Big Data and network analysis; S Sudhahar, GA Veltri, N Cristianini; Big Data & Society 2 (1), 1-28, 2015
- Network analysis of narrative content in large corpora; S Sudhahar, G De Fazio, R Franzosi, N Cristianini; Natural Language Engineering, 1-32, 2013
- Quantitative Narrative Analysis; Roberto Franzosi; Emory University © 2010
- Lansdall-Welfare, Thomas; Sudhahar, Saatviga; Thompson, James; Lewis, Justin; Team, FindMyPast Newspaper; Cristianini, Nello (9 січня 2017). Content analysis of 150 years of British periodicals. Proceedings of the National Academy of Sciences (англ.) 114 (4): E457–E465. ISSN 0027-8424. PMC 5278459. PMID 28069962. doi:10.1073/pnas.1606380114.
- I. Flaounas, M. Turchi, O. Ali, N. Fyson, T. De Bie, N. Mosdell, J. Lewis, N. Cristianini, The Structure of EU Mediasphere, PLoS ONE, Vol. 5(12), pp. e14243, 2010.
- Nowcasting Events from the Social Web with Statistical Learning V Lampos, N Cristianini; ACM Transactions on Intelligent Systems and Technology (TIST) 3 (4), 72
- NOAM: news outlets analysis and monitoring system; I Flaounas, O Ali, M Turchi, T Snowsill, F Nicart, T De Bie, N Cristianini Proc. of the 2011 ACM SIGMOD international conference on Management of data
- Automatic discovery of patterns in media content, N Cristianini, Combinatorial Pattern Matching, 2-13, 2011
- I. Flaounas, O. Ali, T. Lansdall-Welfare, T. De Bie, N. Mosdell, J. Lewis, N. Cristianini, RESEARCH METHODS IN THE AGE OF DIGITAL JOURNALISM, Digital Journalism, Routledge, 2012
- Circadian Mood Variations in Twitter Content; Fabon Dzogang, Stafford Lightman, Nello Cristianini. Brain and Neuroscience Advances, 1, 2398212817744501.
- Effects of the Recession on Public Mood in the UK; T Lansdall-Welfare, V Lampos, N Cristianini; Mining Social Network Dynamics (MSND) session on Social Media Applications
- Архівовано 9 червня 2014 у Wayback Machine.
- Licences for Europe - Structured Stakeholder Dialogue 2013. European Commission. Процитовано 14 листопада 2014.
- Text and Data Mining:Its importance and the need for change in Europe. Association of European Research Libraries. 25 квітня 2013. Архів оригіналу за 29 листопада 2014. Процитовано 14 листопада 2014.
- Judge grants summary judgment in favor of Google Books — a fair use victory. Lexology.com. Antonelli Law Ltd. Процитовано 14 листопада 2014.
- A Brief History of Text Analytics by Seth Grimes. Beyenetwork. 30 жовтня 2007. Процитовано 23 лютого 2015.
- Hearst, Marti A. (1999). Untangling text data mining. Proceedings of the 37th annual meeting of the Association for Computational Linguistics on Computational Linguistics. с. 3–10. ISBN 978-1-55860-609-8. doi:10.3115/1034678.1034679.
Джерела
- Survey of Text Mining I: Clustering, Classification, and Retrieval / Ed. by M. W. Berry. — 2004. — Springer, 2003. — 261 с. — ISBN 0387955631.
- Aggarwal C. C., Zhai C. Mining Text Data. — Springer, 2012. — 527 с. — ISBN 9781461432234.
- Do Prado H. A. Emerging Technologies of Text Mining: Techniques and Applications / Ed. by H. A. Do Prado, E. Ferneda. — Idea Group Reference. — Springer, 2007. — 358 с. — ISBN 1599043734.