Перехресне затверджування
Перехре́сне затве́рджування (англ. cross-validation),[1][2][3] іноді зване ротаці́йним оці́нюванням (англ. rotation estimation)[4][5][6] або позави́бірковим випро́буванням (англ. out-of-sample testing), — це будь-яка з подібних методик затверджування моделі для оцінювання того, наскільки результати статистичного аналізу узагальнюватимуться на незалежний набір даних. Його переважно використовують в постановках, де метою є передбачування, й потрібно оцінювати те, наскільки точно передбачувальна модель працюватиме на практиці. В задачі передбачування, моделі зазвичай дають набір відомих даних, на яких виконують тренування (тренувальний набір даних), та набір невідомих даних (або вперше бачених даних), на яких модель випробовують (званий затверджувальним або випробувальним набором даних).[7][8] Метою перехресного затверджування є випробувати здатність моделі передбачувати нові дані, які не використовувалися при її визначенні, щоби просигналізувати про такі проблеми як перенавчання та ви́біркове упередження,[9] і щоби дати уявлення про те, як ця модель узагальнюватиметься на незалежний набір даних (тобто, невідомий набір даних, наприклад, з реальної задачі).
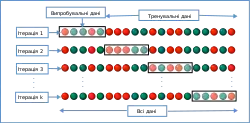
Один раунд перехресного затверджування включає розбивання вибірки даних на взаємодоповнювальні піднабори, виконання аналізу на одному з піднаборів (званому тренувальним набором) та затверджування результатів на іншому піднаборі (званому затверджувальним або випробувальним набором). З метою зниження мінливості, в більшості методів виконують декілька раундів перехресного затверджування з використанням різних розбиттів, і, щоби дати оцінку передбачувальної продуктивності моделі, результати затверджування поєднують (наприклад, усереднюють) над раундами.
Коротко, перехресне затверджування поєднує (усереднює) міри допасованості в передбачуванні, щоби вивести точнішу оцінку передбачувальної продуктивності моделі.[10]
Обґрунтування
Припустімо, що в нас є модель з одним чи більше невідомими параметрами, та набір даних, до якого цю модель можливо допасувати (тренувальний набір даних). Процес допасовування оптимізує ці параметри моделі, щоби зробити модель якнайкраще допасованою до цих тренувальних даних. Якщо ми потім візьмемо незалежну вибірку затверджувальних даних з тої ж сукупності, з якої було взято й тренувальні дані, то, як правило, виявиться, що ця модель не допасовується до затверджувальних даних так же добре, як вона допасовується до даних тренувальних. Розмір цієї різниці може бути великим, особливо коли розмір тренувального набору даних є малим, або коли число параметрів моделі є великим. Перехресне затверджування є одним зі способів оцінити розмір цього ефекту.
В лінійній регресії ми маємо дійсні значення відгуку y1, ..., yn, та n p-вимірних векторних коваріат x1, ..., xn. Компоненти вектора xi позначують через xi1, ..., xip. Якщо ми використовуємо найменші квадрати, щоби допасувати функцію в вигляді гіперплощини ŷ = a + βTx до даних (xi, yi) 1 ≤ i ≤ n, то ми можемо оцінювати допасованість, застосовуючи середньоквадратичну похибку (СКП, англ. mean squared error, MSE). СКП для заданих оцінюваних значень параметрів a та β на тренувальному наборі (xi, yi) 1 ≤ i ≤ n визначено як

Якщо модель вказано правильно, то за м'яких припущень може бути показано, що математичне сподівання СКП для тренувального набору становить (n − p − 1)/(n + p + 1) < 1 на математичне сподівання СКП для затверджувального набору[11] (математичне сподівання береться над розподілом тренувальних наборів). Таким чином, якщо ми допасуємо модель й обчислимо СКП на тренувальному наборі, то ми отримаємо оптимістично упереджену оцінку того, наскільки добре ця модель допасовуватиметься на незалежному наборі даних. Цю упереджену оцінку називають внутрішньовибірковою (англ. in-sample) оцінкою допасованості, тоді як оцінку перехресного затверджування називають позавибірковою (англ. out-of-sample) оцінкою.
Оскільки в лінійній регресії можливо безпосередньо обчислювати коефіцієнт (n − p − 1)/(n + p + 1), на який тренувальна СКП недооцінює затверджувальну СКП за припущення, що модель вказано правильно, то перехресне затверджування можливо застосовувати, щоби перевіряти, чи не було модель перенавчено, в разі чого СКП у затверджувальному наборі значно перевищуватиме її очікуване значення. (Перехресне затверджування в контексті лінійної регресії також корисне тим, що його можливо використовувати, щоби обирати оптимально регуляризовану функцію витрат.) В більшості інших регресійних процедур (наприклад, в логістичній регресії) простої формули для обчислення очікуваної позавибіркової допасованості не існує. Перехресне затверджування, відтак, є загально застосовним способом передбачувати продуктивність моделі на недоступних даних із застосуванням чисельних обчислень замість теоретичного аналізу.
Типи
Може бути вирізнено два типи перехресного затверджування: вичерпне (англ. exhaustive) та невичерпне (англ. non-exhaustive).
Вичерпне перехресне затверджування
Вичерпні методи перехресного затверджування — це такі методи перехресного затверджування, які навчаються та випробовуються на всіх можливих способах поділу первинної вибірки на тренувальний та затверджувальний набори.
Перехресне затверджування з виключенням по p
Перехресне затверджування з виключенням по p (ПЗ ВПp, англ. leave-p-out cross-validation, LpO CV) передбачає використання p спостережень як затверджувального набору, й решти спостережень як набору тренувального. Це повторюють всіма способами розрізування первинної вибірки на затверджувальний набір із p спостережень, та тренувальний набір.[12]
Перехресне затверджування ВПp вимагає тренування та затверджування моделі разів, де n є числом спостережень у первинній вибірці, й де є біноміальним коефіцієнтом. Для p > 1 й для навіть помірно великого n ПЗ ВПp може стати обчислювально нездійсненним. Наприклад, за n = 100 та p = 30, .


Варіант перехресного затверджування ВПp із p = 2, відомий як перехресне затверджування з виключенням парами, було рекомендовано як майже неупереджений метод оцінювання площі під кривою РХП бінарних класифікаторів.[13]
Перехресне затверджування з виключенням по одному

Перехресне затверджування з виключенням по одному (ПЗВПО, англ. leave-one-out cross-validation, LOOCV) — це окремий випадок перехресного затверджування з виключенням по p із p = 1. Цей процес виглядає подібним до складаного ножа, проте при перехресному затверджуванні обчислюють статистику на виключених зразках, тоді як при складаноножуванні обчислюють статистику лише для залишених зразків.
Перехресне затверджування ВПО вимагає меншого обчислювального часу, ніж ВПp, оскільки має лише проходів замість . Проте проходів все одно можуть вимагати вельми великого обчислювального часу, в разі чого доречнішими можуть бути інші підходи, такі як k-кратне перехресне затверджування.[14]


Псевдокодовий алгоритм:
Вхід:
x, {вектор довжини N зі значеннями x точок входу}
y, {вектор довжини N зі значеннями y очікуваного результату}
interpolate(x_in, y_in, x_out), { повертає оцінку для точки x_out після того, як модель було натреновано на парах x_in—y_in}
Вихід:
err, {оцінка похибки передбачування}
Кроки:
err ← 0 for i ← 1, ..., N do // визначити піднабори перехресного затверджування x_in ← (x[1], ..., x[i − 1], x[i + 1], ..., x[N]) y_in ← (y[1], ..., y[i − 1], y[i + 1], ..., y[N]) x_out ← x[i] y_out ← interpolate(x_in, y_in, x_out) err ← err + (y[i] − y_out)^2 end for err ← err/N
Невичерпне перехресне затверджування
Невичерпні методи перехресного затверджування не обчислюють всі способи поділу первинної вибірки. Ці методи є наближенням перехресного затверджування з виключенням по p.
k-кратне перехресне затверджування

В k-кратнім перехреснім затверджуванні (англ. k-fold cross-validation) первинну вибірку випадково розбивають на k підвибірок однакового розміру. З цих k підвибірок одну підвибірку притримують як затверджувальні дані для випробування моделі, а решту k − 1 вибірок використовують як тренувальні дані. Потім процес перехресного затверджування повторюють k разів, використовуючи кожну з k підвибірок як затверджувальні дані рівно один раз. Відтак ці k результатів може бути усереднено, щоби отримати єдину оцінку. Перевагою цього методу перед повторюваним випадковим взяттям підвибірок (див. нижче) є те, що як для тренування, так і для затверджування використовують всі спостереження, й кожне спостереження використовують для затверджування рівно один раз. Зазвичай використовують 10-кратне затверджування,[15] але загалом k залишається вільним параметром.
Наприклад, встановлення k = 2 призводить до 2-кратного перехресного затверджування. У 2-кратнім перехреснім затверджуванні ми випадково розкида́ємо набір даних на два набори d0 та d1 таким чином, що обидва мають однакові розміри (це зазвичай втілюють через перетасовування масиву даних та поділ його навпіл). Потім ми тренуємо на d0 й затверджуємо на d1, після чого тренуємо на d1 й затверджуємо на d0.
Коли k = n (числу спостережень), k-кратне перехресне затверджування є рівнозначним перехресному затверджуванню з виключенням по одному.[16]
В стратифікованім (англ. stratified) k-кратнім перехреснім затверджуванні частини обирають таким чином, щоби середнє значення відгуку було приблизно рівним в усіх частинах. У випадку бінарної класифікації це означає, що кожна частина містить приблизно однакову пропорцію двох типів міток класу.
У повторюванім (англ. repeated) перехреснім затверджуванні дані випадково ділять на k частин декілька разів. Продуктивність моделі відтак може бути усереднено над декількома проходами, але на практиці це рідко є бажаним.[17]
Метод притримування
В методі притримування (англ. holdout method) ми випадково призначуємо точки даних двом наборами d0 та d1, зазвичай званим тренувальним та випробувальним наборами відповідно. Розмір кожного з наборів є довільним, хоча зазвичай випробувальний набір є меншим за тренувальний. Потім ми тренуємо (будуємо модель) на d0, та випробуємо (оцінюємо її продуктивність) на d1.
В типовім перехреснім затверджуванні усереднюють результати декількох пробігань моделювання-випробування. На противагу цьому, метод притримування, наодшибі, містить лише одне пробігання. Його слід застосовувати обережно, оскільки без такого усереднювання декількох пробігань можна досягти дуже оманливих результатів. Показник передбачувальної точності (F*) матиме схильність бути нестійким, оскільки його не буде згладжено декількома ітераціями (див. нижче). Аналогічно, схильність бути нестійкими матимуть показники конкретної ролі, яку відіграю́ть ті чи інші передбачувальні змінні (наприклад, значення регресійних коефіцієнтів).
І хоча метод притримування може бути охарактеризовано як «найпростіший тип перехресного затверджування»,[18] багато джерел натомість класифікують притримування як один з типів простого затверджування, а не як просту або вироджену форму затверджування перехресного.[5][19]
Повторюване випадкове підвибіркове затверджування
Цей метод (англ. repeated random sub-sampling validation), відомий також як перехресне затверджування Монте-Карло,[20] створює декілька випадкових поділів набору даних на тренувальні та затверджувальні дані.[21] Для кожного такого поділу модель допасовують до тренувальних даних, й оцінюють її передбачувальну точність, застосовуючи затверджувальні дані. Результати відтак усереднюють над цими поділами. Перевагою цього методу (перед k-кратним перехресним затверджуванням) є те, що пропорція тренувального/затверджувального поділу не залежить від числа ітерацій (тобто, числа розбиттів). Недоліком цього методу є те, що деякі спостереження може ніколи не бути обрано до затверджувальної підвибірки, тоді як інші може бути обрано понад один раз. Іншими словами, затверджувальні піднабори можуть перекриватися. Цей метод також зазнає́ мінливості Монте-Карло, що означає, що результати варіюватимуться, якщо аналіз повторюватимуть з відмінними випадковими поділами.
З наближенням числа випадкових поділів до нескінченності результат повторюваного випадкового підвибіркового затверджування має схильність прямувати до результату перехресного затверджування з виключенням по p.
У стратифікованім варіанті цього підходу випадкові вибірки породжують таким чином, щоби середнє значення відгуку (тобто, залежної змінної в регресії) було рівним у тренувальному та випробувальному наборах. Це є особливо корисним, якщо відгуки є дихотомними з незбалансованим представленням двох значень відгуку в даних.
Вкладене перехресне затверджування
Коли перехресне затверджування використовують одночасно для обирання найкращого набору гіперпараметрів та для оцінювання похибки (та здатності до узагальнювання), необхідним є вкладене перехресне затверджування (англ. nested cross-validation). Варіантів існує багато. Можливо виділити щонайменше два варіанти:
k×l-кратне перехресне затверджування
Це є істинно вкладеним варіантом (наприклад, вживаним у cross_val_score в scikit-learn[22]), що містить зовнішній k-кратний цикл, та внутрішній l-кратний цикл. Загальний набір даних ділять на k наборів. Один по одному, обирають набір як (зовнішній) випробувальний набір, а решту k - 1 наборів поєднують у відповідний зовнішній тренувальний набір. Це повторюють для кожного з k наборів. Кожен зовнішній тренувальний набір ділять далі на l наборів. Один по одному, обирають набір як внутрішній випробувальний (затверджувальний) набір, а решту l - 1 наборів поєднують у відповідний внутрішній тренувальний набір. Це повторюють для кожного з l наборів. Внутрішні тренувальні набори використовують для допасовування параметрів моделі, тоді як зовнішній випробувальний набір використовують як затверджувальний набір, щоби забезпечити неупереджену оцінку допасованості моделі. Зазвичай, це повторюють для багатьох різних гіперпараметрів (або навіть різних типів моделей), і затверджувальний набір використовують для визначення найкращого набору гіперпараметрів (та типу моделі) для цього внутрішнього тренувального набору. Після цього нову модель допасовують до всього зовнішнього тренувального набору, використовуючи найкращий набір гіперпараметрів з внутрішнього перехресного затверджування. Продуктивність цієї моделі потім оцінюють, використовуючи зовнішній випробувальний набір.
k-кратне перехресне затверджування із затверджувальним та випробувальним наборами
Воно є одним з типів k×l-кратного перехресного затверджування, в якому l = k - 1. Одне k-кратне перехресне затверджування використовують як із затверджувальним, так і з випробувальним набором. Загальний набір даних ділять на k наборів. Один по одному, набір обирають як випробувальний. Потім, один по одному, один з наборів, що лишилися, використовують як затверджувальний набір, а решту k - 2 наборів використовують як тренувальні, поки не буде оцінено всі можливі комбінації. Подібно до k×l-кратного перехресного затверджування, тренувальний набір використовують для допасовування моделі, а затверджувальний набір використовують для оцінки моделі для кожного з наборів гіперпараметрів. Нарешті, для обраного набору параметрів використовують випробувальний набір, щоби оцінити модель із найкращим набором параметрів. Тут є можливими два варіанти: або оцінювання моделі, що було натреновано на тренувальному наборі, або оцінювання нової моделі, що було допасовано до поєднання тренувального та затверджувального наборів.
Міри допасованості
Метою перехресного затверджування є оцінити очікуваний рівень допасованості моделі до набору даних, що є незалежним від даних, які було використано для тренування моделі. Його можливо використовувати для оцінювання кількісної міри допасованості, що є властивою цим даним та моделі. Наприклад, для задач бінарної класифікації кожен випадок у затверджувальному наборі є передбаченим або правильно, або неправильно. В такій ситуації для підбивання підсумку допасованості можливо використовувати рівень похибки неправильної класифікації, хоча також можливо використовувати й інші міри, такі як прогностична значущість позитивного результату. Коли передбачуване значення є розподіленим неперервно, для підсумовування похибок можливо використовувати середньоквадратичну похибку, кореневе середньоквадратичне відхилення чи медіану абсолютних відхилень.
Використання апріорної інформації
Коли користувачі застосовують перехресне затверджування для обирання доброї конфігурації , то вони можуть хотіти збалансовувати вибір перехресного затверджування з їхньою власною оцінкою конфігурації. Таким чином, вони можуть намагатися протистояти мінливості перехресного затверджування, коли розмір вибірки є малим, й включати доречну інформацію з попередніх досліджень. Наприклад, у вправі поєднування прогнозів, перехресне затверджування можливо застосовувати для оцінювання ваг, призначуваних кожному з прогнозів. Оскільки простий рівнозважений прогноз важко перемогти, на відхилення від рівних ваг може бути запроваджено штраф.[23] Або, якщо перехресне затверджування застосовують для призначування індивідуальних ваг спостереженням, то можливо штрафувати відхилення від рівних ваг, щоб уникати марнування потенційно доречної інформації.[23] Гурнвеґ (2018) показує, як можливо визначити параметр налаштування таким чином, щоби користувач міг інтуїтивно балансувати між точністю перехресного затверджування та просторою дотримування еталонного параметру , визначеного користувачем.



Якщо позначує -ту конфігурацію-кандидата, яку могло би бути обрано, то функцію втрат для мінімізування може бути визначено як



Відносну точність (англ. relative accuracy) може бути виражено кількісно як , так що середньоквадратичну похибку кандидата роблять відносною до визначеної користувачем . Член відносної простоти (англ. relative simplicity) вимірює величину, на яку відхиляється від , по відношенню до максимальної величини відхилення від . Відповідно, відносну простоту може бути вказано як , де відповідає значенню з найбільшим допустимим відхиленням від . За допомогою користувач встановлює, наскільки сильним є вплив еталонного параметру по відношенню до перехресного затверджування.




Можливо додавати члени відносної простоти для декількох конфігурації , вказавши функцію втрат як


Гурнвеґ (2018) показує, що функцію втрат з таким компромісом точності-простоти також можливо використовувати, щоби інтуїтивно визначати стискальну оцінку на кшталт (адаптивного) LASSO та баєсової / хребтової регресії.[23] Див. приклад у LASSO.
Статистичні властивості
Припустімо, що ми обираємо міру допасованості F, й використовуємо перехресне затверджування, щоби виробити оцінку F* математичного сподівання допасованості (англ. expected fit) EF моделі до незалежного набору даних, вибраного з тієї ж генеральної сукупності, що й тренувальні дані. Якщо ми уявимо вибирання декількох незалежних тренувальних наборів, що слідують одному й тому ж розподілові, то значення результату F* будуть мінливими. Статистичні властивості F* випливають із цієї мінливості.
Перехресно-затверджувальний оцінювач F* є майже-майже незміщеним для EF.[24][джерело?] Причиною того, що він є злегка зміщеним, є те, що тренувальний набір у перехреснім затверджуванні є дещо меншим за справжній набір даних (наприклад, для ПЗВПО розмір тренувального набору становить n − 1 за кількості спостережених випадків n). Майже в усіх випадках вплив цього зміщення буде консервативним, в тому сенсі, що оцінена допасованість буде злегка зміщеною в напрямку підказування гіршої допасованості. На практиці це зміщення рідко стає предметом занепокоєння.
Дисперсія F* може бути великою.[25][26] З цієї причини, якщо дві статистичні процедури порівнюють на основі перехресного затверджування, процедура з кращою оцінюваною продуктивність може насправді не бути кращою з цих двох (тобто, вона може не мати кращого значення EF). Було досягнуто певного прогресу в побудові довірчих проміжків навколо оцінок перехресного затверджування,[25] але це вважають складною проблемою.
Обчислювальні питання
Більшість форм перехресного затверджування є прямолінійними для втілення, доки є доступним втілення досліджуваного методу передбачування. Зокрема, метод передбачування може бути «чорною скринькою», — немає потреби мати доступ до нутрощів його втілення. Якщо метод передбачування є витратним для тренування, то перехресне затверджування може бути повільним, оскільки тренування мусить здійснюватися багаторазово. В деяких випадках, таких як найменші квадрати та ядрова регресія, перехресне затверджування можливо значно прискорити, обчислюючи попередньо деякі значення, що є потрібними в тренуванні багаторазово, або використовуючи швидкі «правила уточнення», такі як формула Шермана — Моррісона. Проте, слід бути обережними, щоби зберегти «повне засліплення» затверджувального набору від тренувальної процедури, бо інакше може виникнути зміщення. Крайній випадок прискорення перехресного затверджування трапляється в лінійній регресії, де результати перехресного затверджування є виразом замкненого вигляду, відомим як сума квадратів похибок передбачуваних залишків (англ. prediction residual error sum of squares, PRESS).
Обмеження та неправильне використання
Перехресне затверджування видає змістовні результати лише якщо затверджувальний та тренувальний набори вибирають з однієї й тієї ж генеральної сукупності, й лише якщо людське упередження перебуває під контролем.
В багатьох застосуваннях передбачувального моделювання структура досліджуваної системи еволюціює з часом (тобто, є «нестаціонарною»). І те, й друге може привносити систематичні відмінності між тренувальним та затверджувальним наборами. Наприклад, якщо модель для передбачування вартості акцій тренують на даних за певний п'ятирічний період, то буде нереалістичним розглядати наступний п'ятирічний період як вибраний з тієї ж генеральної сукупності. Як інший приклад, розгляньмо модель, що розробляють для передбачування ризику особи отримати діагноз певної хвороби протягом наступного року. Якщо модель тренують, використовуючи дані дослідження, що охоплює лише специфічну групу населення (наприклад, молодих людей, або чоловіків), але потім застосовують до населення в цілому, то результати перехресного затверджування з тренувального набору можуть відрізнятися від дійсної передбачувальної продуктивності дуже сильно.
В багатьох застосування також може бути неправильно вказано моделі, або вони можуть змінюватися залежно від упередженості моделювальника та/або випадкового вибору. Коли таке трапляється, може виникати ілюзія, що система змінюється в зовнішніх вибірках, тоді як причиною є те, що модель пропустила критичний передбачувач, та/або включила передбачувач, збитий з пантелику. Нові дані свідчать, що перехресне затверджування саме по собі є не дуже передбачувальним для зовнішньої застосовності, тоді як один з видів експериментального затверджування, відомий як обмінне вибирання (англ. swap sampling), що контролює людське упередження, може мати щодо неї значно кращу передбачувальну здатність.[27] Як визначено цим великим дослідженням MAQC-II для 30 000 моделей, обмінне вибирання містить в собі перехресне затверджування в тому сенсі, що передбачування випробовують на незалежних тренувальній та затверджувальній вибірках. До того ж, моделі також і розробляють на цих незалежних вибірках, і моделювальниками, що не знають одні про одних. Коли між цими моделями, розробленими на цих обмінюваних тренувальному та затверджувальному наборах, є невідповідність, що трапляється доволі часто, MAQC-II показує, що це значно краще передбачуватиме погану зовнішню продуктивність, ніж традиційне перехресне затверджування.
Причиною успішності обмінного вибирання є вбудований контроль людських упереджень в побудові моделей. На додачу до занадто великої віри у передбачування, яка може варіюватися між моделювальниками, і вести до поганої зовнішньої застосовності через ці сплутані впливи моделювальників, ось іще деякі неправильні способи використання перехресного затверджування:
- Виконання початкового аналізу для виявляння найінформативніших ознак із застосуванням всього набору даних, якщо обирання ознак або налаштування моделі вимагає процедура моделювання: це мусить бути повторювано на кожному тренувальному наборі. Інакше передбачування безумовно будуть зміщеними вгору.[28] Якщо для вирішування, яку ознаку використовувати, застосовувати перехресне затверджування, то для виконання обирання ознак на кожному тренувальному наборі мусить виконуватися внутрішнє перехресне затверджування (англ. inner cross-validation).[29]
- Дозволяння деяким з тренувальних даних входити й до випробувального набору: це може ставатися через «двійникування» в наборі даних, за якого в ньому міститься якась кількість повністю або майже ідентичних зразків. Двійникування до деякої міри завжди має місце навіть в ідеально незалежних тренувальних та затверджувальних вибірках. Це відбувається через те, що деякі зі спостережень тренувальної вибірки матимуть значення передбачувальних змінних, майже ідентичні до спостережень затверджувальної вибірки. І деякі з них корелюватимуть з ціллю на рівні, кращому за випадковий, в одному й тому ж напрямку як у тренуванні, так і в затверджуванні, будучи насправді керованими збуреними передбачувачами з поганою зовнішньою застосовністю. Якщо таку перехресно затверджену модель буде обрано з k-кратного набору, то спрацює людське підтверджувальне упередження, визначивши цю модель затвердженою. Ось чому традиційне перехресне затверджування потребує доповнення контролем людського упередження та збитого з пантелику визначення моделі, такого як обмінне вибирання, та перспективне дослідження.
Перехресне затверджування для моделей часових рядів
Оскільки порядок даних є важливим, для моделей часових рядів перехресне затверджування може бути проблематичним. Доречнішим підходом може бути застосування ковзного перехресного затверджування (англ. rolling cross-validation).
Проте, якщо продуктивність описано єдиною зведеною статистикою, то, можливо, працюватиме підхід, що було описано Політісом та Романо як стаціонарну натяжку.[30] Статистиці натяжки потрібно приймати проміжок часового ряду й повертати зведену статистику на ньому. Виклик стаціонарної натяжки потребує вказування доречної середньої довжини проміжку.
Застосування
Перехресне затверджування можливо використовувати для порівнювання продуктивності різних процедур передбачувального моделювання. Наприклад, припустімо, що нас цікавить оптичне розпізнавання символів, і для розпізнавання справжнього символу з зображення рукописного символу ми розглядаємо використання опорно-векторних машин (ОВМ) та k-найближчих сусідів (kНС). Застосовуючи перехресне затверджування, ми можемо об'єктивно порівняти ці два методи в термінах їхніх відповідних часток неправильно класифікованих символів. Якби ми просто порівняли ці методи на основі їхніх внутрішньовибіркових рівнів похибки, то, швидше за все, продуктивність методу kНС виглядала би кращою, оскільки від є гнучкішим, і відтак стійкішим до перенавчання[джерело?] в порівнянні з методом ОВМ.
Перехресне затверджування також можливо застосовувати в обиранні змінних.[31] Припустімо, що ми використовуємо рівні експресії 20 білків, щоби передбачувати, чи відреагує пацієнт з раком на певні ліки. Однією з практичних цілей буде визначити, яку підмножину з 20 ознак слід використовувати для вироблення найкращої передбачувальної моделі. Для більшості процедур моделювання, якщо ми порівнюємо підмножини ознак, використовуючи внутрішньовибіркові рівні похибки, найкраща продуктивність досягатиметься при використанні всіх 20 ознак. Проте за перехресного затверджування модель із найкращою допасованістю в загальному випадку включатиме лише підмножину ознак, які вважаються справді інформативними.
Нещодавнім розширенням медичної статистики стало її застосування в метааналізі. Вона формує основу статистики обґрунтованості (англ. validation statistic), Vn, яку використовують, щоби випробовувати статистичну обґрунтованість підсумкових оцінок метааналізу.[32] Її також використовували в метааналізі у звичнішому сенсі, для оцінювання правдоподібної похибки передбачування результатів метааналізу.[33]
Див. також
- Підсилювання (машинне навчання)
- Натяжкове агрегування (англ. bagging)
- Статистична натяжка
- Витік (машинне навчання)
- Обирання моделі
- Перевибірка (статистика)
- Стійкість (теорія навчання)
- Обґрунтованість
Зауваження та примітки
- Allen, David M (1974). The Relationship between Variable Selection and Data Agumentation and a Method for Prediction. Technometrics 16 (1): 125–127. JSTOR 1267500. doi:10.2307/1267500. (англ.)
- Stone, M (1974). Cross-Validatory Choice and Assessment of Statistical Predictions. Journal of the Royal Statistical Society: Series B (Methodological) 36 (2): 111–147. doi:10.1111/j.2517-6161.1974.tb00994.x. (англ.)
- Stone, M (1977). An Asymptotic Equivalence of Choice of Model by Cross-Validation and Akaike's Criterion. Journal of the Royal Statistical Society: Series B (Methodological) 39 (1): 44–47. JSTOR 2984877.} (англ.)
- Geisser, Seymour (1993). Predictive Inference. New York, NY: Chapman and Hall. ISBN 978-0-412-03471-8. (англ.)
- Kohavi, Ron (1995). A study of cross-validation and bootstrap for accuracy estimation and model selection. Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence (San Mateo, CA: Morgan Kaufmann) 2 (12): 1137–1143. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Devijver, Pierre A.; Kittler, Josef (1982). Pattern Recognition: A Statistical Approach. London, GB: Prentice-Hall. ISBN 0-13-654236-0. (англ.)
- Galkin, Alexander (28 листопада 2011). What is the difference between test set and validation set?. Процитовано 10 жовтня 2018. (англ.)
- Помилка Lua у Модуль:Citation/CS1 у рядку 1385: attempt to concatenate global 'arch_text' (a nil value). (англ.)
- Cawley, Gavin C.; Talbot, Nicola L. C. (2010). On Over-fitting in Model Selection and Subsequent Selection Bias in Performance Evaluation 11. Journal of Machine Learning Research. с. 2079–2107. (англ.)
- Grossman, Robert; Seni, Giovanni; Elder, John; Agarwal, Nitin; Liu, Huan (2010). Ensemble Methods in Data Mining: Improving Accuracy Through Combining Predictions. Synthesis Lectures on Data Mining and Knowledge Discovery (Morgan & Claypool) 2: 1–126. doi:10.2200/S00240ED1V01Y200912DMK002. (англ.)
- Trippa, Lorenzo; Waldron, Levi; Huttenhower, Curtis; Parmigiani, Giovanni (March 2015). Bayesian nonparametric cross-study validation of prediction methods. The Annals of Applied Statistics (EN) 9 (1): 402–428. Bibcode:2015arXiv150600474T. ISSN 1932-6157. arXiv:1506.00474. doi:10.1214/14-AOAS798. (англ.)
- Celisse, Alain (1 жовтня 2014). Optimal cross-validation in density estimation with the $L^{2}$-loss. The Annals of Statistics (англ.) 42 (5): 1879–1910. ISSN 0090-5364. arXiv:0811.0802. doi:10.1214/14-AOS1240. (англ.)
- Airola, A.; Pahikkala, T.; Waegeman, W.; De Baets, Bernard; Salakoski, T. (1 квітня 2011). An experimental comparison of cross-validation techniques for estimating the area under the ROC curve. Computational Statistics & Data Analysis (англ.) 55 (4): 1828–1844. doi:10.1016/j.csda.2010.11.018. (англ.)
- Molinaro, A. M.; Simon, R.; Pfeiffer, R. M. (1 серпня 2005). Prediction error estimation: a comparison of resampling methods. Bioinformatics (англ.) 21 (15): 3301–3307. ISSN 1367-4803. PMID 15905277. doi:10.1093/bioinformatics/bti499. Проігноровано невідомий параметр
|doi-access=(довідка) (англ.) - McLachlan, Geoffrey J.; Do, Kim-Anh; Ambroise, Christophe (2004). Analyzing microarray gene expression data. Wiley. (англ.)
- Elements of Statistical Learning: data mining, inference, and prediction. 2nd Edition.. web.stanford.edu. Процитовано 4 квітня 2019. (англ.)
- Vanwinckelen, Gitte (2 жовтня 2019). On Estimating Model Accuracy with Repeated Cross-Validation.. lirias.kuleuven. с. 39–44. ISBN 9789461970442. (англ.)
- Cross Validation. Процитовано 11 листопада 2012. (англ.)
- Arlot, Sylvain; Celisse, Alain (2010). A survey of cross-validation procedures for model selection. Statistics Surveys 4: 40–79. arXiv:0907.4728. doi:10.1214/09-SS054. «In brief, CV consists in averaging several hold-out estimators of the risk corresponding to different data splits.» (англ.)
- Dubitzky, Werner; Granzow, Martin; Berrar, Daniel (2007). Fundamentals of data mining in genomics and proteomics. Springer Science & Business Media. с. 178. (англ.)
- Kuhn, Max; Johnson, Kjell (2013). Applied Predictive Modeling (англ.). New York, NY: Springer New York. ISBN 9781461468486. doi:10.1007/978-1-4614-6849-3. (англ.)
- Nested versus non-nested cross-validation. Процитовано 19 лютого 2019. (англ.)
- Hoornweg, Victor (2018). Science: Under Submission. Hoornweg Press. ISBN 978-90-829188-0-9. (англ.)
- Christensen, Ronald (21 травня 2015). Thoughts on prediction and cross-validation. Department of Mathematics and Statistics University of New Mexico. Процитовано 31 травня 2017. (англ.)
- Efron, Bradley; Tibshirani, Robert (1997). Improvements on cross-validation: The .632 + Bootstrap Method. Journal of the American Statistical Association 92 (438): 548–560. JSTOR 2965703. MR 1467848. doi:10.2307/2965703. (англ.)
- Stone, Mervyn (1977). Asymptotics for and against cross-validation. Biometrika 64 (1): 29–35. JSTOR 2335766. MR 0474601. doi:10.1093/biomet/64.1.29. (англ.)
- Consortium, MAQC (2010). The Microarray Quality Control (MAQC)-II study of common practices for the development and validation of microarray-based predictive models. Nature Biotechnology (London: Nature Publishing Group) 28 (8): 827–838. PMC 3315840. PMID 20676074. doi:10.1038/nbt.1665. (англ.)
- Bermingham, Mairead L.; Pong-Wong, Ricardo; Spiliopoulou, Athina; Hayward, Caroline; Rudan, Igor; Campbell, Harry; Wright, Alan F.; Wilson, James F.; Agakov, Felix; Navarro, Pau; Haley, Chris S. (2015). Application of high-dimensional feature selection: evaluation for genomic prediction in man. Sci. Rep. 5: 10312. Bibcode:2015NatSR...510312B. PMC 4437376. PMID 25988841. doi:10.1038/srep10312. (англ.)
- Varma, Sudhir; Simon, Richard (2006). Bias in error estimation when using cross-validation for model selection. BMC Bioinformatics 7: 91. PMC 1397873. PMID 16504092. doi:10.1186/1471-2105-7-91. (англ.)
- Politis, Dimitris N.; Romano, Joseph P. (1994). The Stationary Bootstrap. Journal of the American Statistical Association 89 (428): 1303–1313. doi:10.1080/01621459.1994.10476870. (англ.)
- Picard, Richard; Cook, Dennis (1984). Cross-Validation of Regression Models. Journal of the American Statistical Association 79 (387): 575–583. JSTOR 2288403. doi:10.2307/2288403. (англ.)
- Measuring the statistical validity of summary meta-analysis and meta-regression results for use in clinical practice. Statistics in Medicine 36 (21): 3283–3301. 2017. PMC 5575530. PMID 28620945. doi:10.1002/sim.7372. Проігноровано невідомий параметр
|vauthors=(довідка) (англ.) - Summarising and validating test accuracy results across multiple studies for use in clinical practice.. Statistics in Medicine 34 (13): 2081–2103. 2015. PMC 4973708. PMID 25800943. doi:10.1002/sim.6471. Проігноровано невідомий параметр
|vauthors=(довідка) (англ.)