Обирання ознак
В машинному навчанні та статистиці обира́ння озна́к, відоме також як обира́ння змі́нних, обира́ння атрибу́тів та обира́ння підмножини́ змі́нних (англ. feature selection, variable selection, attribute selection, variable subset selection) — це процес обирання підмножини доречних ознак (змінних, провісників) для використання в побудові моделі. Методики обирання ознак застосовують із декількома цілями:
- спрощення моделей, щоби зробити їх легшими для інтерпретування дослідниками/користувачами,[1]
- скорочення тривалостей тренування,
- уникання прокляття розмірності,
- покращення узагальнення шляхом зниження перенавчання[2] (формально, зниження дисперсії[1]).
Центральною передумовою при застосуванні методики обирання ознак є те, що дані містять деякі ознаки, що є або надлишковими, або недоречними, і тому їх може бути усунено без спричинення значної втрати інформації.[2] «Надлишкові» та «недоречні» є двома різними поняттями, оскільки одна доречна ознака може бути надлишковою в присутності іншої доречної ознаки, з якою вона сильно корелює.[3]
Методики обирання ознак слід відрізняти від виділяння ознак. Виділяння ознак створює нові ознаки з функцій від первинних ознак, тоді як обирання ознак повертає підмножину ознак. Методики обирання ознак часто використовують у тих областях, де є багато ознак, і порівняно мало зразків (або точок даних). До споконвічних випадків застосування обирання ознак належать аналіз писаних текстів та даних ДНК-мікрочипів, де є багато тисяч ознак, і лише від декількох десятків до сотень зразків.
Введення
Алгоритм обирання ознак можливо розглядати як поєднання методики пошуку для пропонування нових підмножин ознак разом із мірою оцінки, яка встановлює бали різним підмножинам ознак. Найпростішим алгоритмом є перевіряти кожну можливу підмножину ознак, шукаючи таку, яка мінімізує рівень похибки. Це є вичерпним пошуком цим простором, і є обчислювально непіддатливим для будь-яких множин ознак, крім найменших. Вибір оцінювальної метрики сильно впливає на алгоритм, і саме ці оцінювальні метрики відрізняють три основні категорії алгоритмів пошуку ознак: обгорткові, фільтрові та вбудовані методи.[3]
- Обгорткові методи для встановлення балів підмножинам ознак використовують передбачувальну модель. Кожну нову підмножину використовують для тренування моделі, яку перевіряють на притриманій множині. Підрахунок кількості помилок, зроблених на цій притриманій множині (рівень похибки моделі) дає бал цієї підмножини. Оскільки обгорткові методи тренують нову модель для кожної підмножини, вони є дуже обчислювально напруженими, але зазвичай пропонують множину ознак із найкращою продуктивністю для того окремого типу моделі.
- Фільтрові методи для встановлення балів підмножинам ознак замість рівня похибки використовують міру-заступницю. Цю міру обирають такою, щоби вона була швидкою, але все ще схоплювала корисність множини ознак. До поширених мір належать взаємна інформація,[3] поточкова взаємна інформація,[4] коефіцієнт кореляції Пірсона, алгоритми на основі Relief[5] та внутрішньо/міжкласова відстань або бали критеріїв значущості для кожної комбінації клас/ознака.[4][6] Фільтри зазвичай є менш напруженими обчислювально за обгортки, але вони пропонують набір ознак, що не налаштовано на конкретний тип передбачувальної моделі.[7] Цей брак налаштування означає, що набір ознак від фільтра є загальнішим за набір від обгортки, зазвичай даючи нижчу передбачувальну продуктивність, ніж обгортка. Проте такий набір ознак не містить припущень передбачувальної моделі, і тому є кориснішим для розкриття взаємозв'язків між ознаками. Багато фільтрів пропонують ранжування ознак замість явної найкращої підмножини ознак, а точку відсікання в рангу обирають за допомогою перехресного затверджування. Фільтрові методи також застосовували як передобробний етап для обгорткових методів, роблячи можливим застосування обгорток до більших задач. Одним з інших популярних підходів є алгоритм рекурсивного усунення ознак (англ. Recursive Feature Elimination),[8] зазвичай застосовуваний з методом опорних векторів для повторної побудови моделі та усунення ознак з низькими ваговими коефіцієнтами.
- Вбудовані методи є всеосяжною групою методик, що виконують обирання ознак як частину процесу побудови моделі. Примірником цього підходу є метод побудови лінійних моделей LASSO, який штрафує коефіцієнти регресії штрафом L1, скорочуючи багато з них до нуля. Будь-які ознаки, що мають ненульові коефіцієнти регресії, є «обраними» алгоритмом LASSO. До покращень LASSO належать Bolasso, яке бутстрепує вибірки,[9], еластично-сіткова регуляризація, яка поєднує штраф L1 LASSO із штрафом L2 гребеневої регресії, та FeaLect, яке встановлює бали всім ознакам на основі комбінаторного аналізу коефіцієнтів регресії.[10] Ці підходи з погляду обчислювальної складності тяжіють до знаходження між фільтрами та обгортками.
У традиційному регресійному аналізі найпопулярнішим видом обирання ознак є поетапна регресія, яка є обгортковою методикою. Це жадібний алгоритм, що під час кожного раунду додає найкращу ознаку (або видаляє найгіршу). Головним питанням у керуванні є вирішування, коли зупинити алгоритм. У машинному навчанні це зазвичай здійснюють за допомогою перехресного затверджування. У статистиці деякі критерії є оптимізованими. Це призводить до проблеми, притаманної вкладеності. Було досліджено надійніші методи, такі як гілки і межі, та кусково-лінійна мережа.
Обирання підмножин
Обирання підмножини оцінює на придатність підмножину ознак як групу. Алгоритми обирання підмножин можливо розділити на обгорткові, фільтрові та вбудовані методи. Обгорткові використовують пошуковий алгоритм для пошуку простором можливих ознак, і оцінки кожної підмножини запуском моделі на ній. Обгортки можуть бути обчислювально витратними, і мати ризик перенавчитися моделі. Фільтри є схожими на обгортки в підході до пошуку, але замість оцінки проти моделі виводять простіший фільтр. Вбудовані методики є вбудованими в модель, і особливими для моделі.
Багато популярних підходів до пошуку використовують жадібний підйом схилом, що ітеративно оцінює кандидата-підмножину ознак, а потім змінює цю підмножину й оцінює, чи є нова підмножина покращенням відносно старої. Оцінка підмножин вимагає оцінкової метрики, що реалізує градацію підмножин ознак. Вичерпний пошук в загальному випадку є непрактичним, тому на певній визначеній реалізатором (або оператором) точці зупинки підмножину ознак із найвищим знайденим до цієї точки балом обирають задовільною підмножиною ознак. Критерій зупинки залежить від алгоритму; до можливих критеріїв належать: перевищення порогу балом підмножини, перевищення максимального допустимого часу виконання програми тощо.
Альтернативні методики на основі пошуку ґрунтуються на націленому пошуку найкращої проекції, який знаходить низькорозмірні проекції даних, що мають високий бал: тоді обирають ознаки, що мають найбільші проекції в низькорозмірному просторі.
До пошукових підходів належать:
- Вичерпний
- Перший-ліпший
- Імітація відпалу
- Генетичний алгоритм[11]
- Жадібне поступальне обирання (англ. Greedy forward selection)[12][13][14]
- Жадібне зворотне усунення (англ. Greedy backward elimination)
- Метод рою часток[15]
- Націлений пошук найкращої проекції
- Пошук врозсип (англ. Scatter Search)[16]
- Пошук змінними околами[17][18]
Двома популярними фільтровими метриками для задач класифікації є кореляція та взаємна інформація, хоча жодна з них не є справжньою метрикою, або «мірою відстані», в математичному сенсі, оскільки вони не підкоряються нерівності трикутника, і відтак не обчислюють жодної дійсної «відстані» — їх слід було би швидше розглядати як «бали». Ці бали обчислюють між ознаками-кандидатами (або наборами ознак) та бажаною категорією виходу. Проте існують і справжні метрики, що є простою функцією взаємної інформації;[19] див. тут.
До інших доступних фільтрових метрик належать:
- Віддільність класів (англ. class separability)
- Імовірність похибки (англ. error probability)
- Міжкласова відстань (англ. inter-class distance)
- Імовірнісна відстань (англ. probabilistic distance)
- Інформаційна ентропія
- Обирання ознак на основі узгодженості (англ. consistency-based feature selection)
- Обирання ознак на основі кореляції (англ. correlation-based feature selection)
Критерій оптимальності
Обирання критерію оптимальності є складним, оскільки в завдання обирання ознак є кілька цілей. Багато поширених критеріїв включають міру точності, штрафовану кількістю обраних ознак. До прикладів належать інформаційний критерій Акаіке (ІКА, англ. AIC) та Cp Меллоуза, що мають штраф у для кожної доданої ознаки. ІКА ґрунтується на теорії інформації, й практично виводиться з принципу максимуму ентропії.[20][21]

Іншими критеріями є баєсів інформаційний критерій (БІК, англ. BIC), що використовує штраф у для кожної доданої ознаки, принцип мінімальної довжини опису (МДО, англ. MDL), що асимптотично використовує , Бонферроні / КРР (англ. RIC), який використовує , обирання ознак максимальної залежності (англ. maximum dependency feature selection) та ряд нових критеріїв, обґрунтованих рівнем хибного виявляння (англ. false discovery rate, FDR), який використовує щось близьке до . Для обирання найвідповіднішої множини ознак можна також використовувати й критерій максимальної ентропійної швидкості.[22]



Навчання структури
Фільтрове обирання ознак є окремим випадком загальнішої парадигми, що називають навчанням структури. Обирання ознак знаходить доречний набір ознак для конкретної цільової змінної, тоді як навчання структури знаходить взаємозв'язки між усіма змінними, зазвичай виражаючи ці взаємозв'язки як граф. Найпоширеніші алгоритми навчання структури виходять із того, що дані було породжено баєсовою мережею, і тому структурою є орієнтована графова модель. Оптимальним розв'язком задачі фільтрового обирання ознак є марковське покриття цільового вузла, і в баєсовій мережі існує єдине марковське покриття для кожного вузла.[23]
Механізми обирання ознак на основі теорії інформації
Існують різні механізми обирання ознак, що для оцінювання різних ознак використовують взаємну інформацію. Вони зазвичай використовують один і той же алгоритм:
- Обчислити взаємну інформацію як оцінку між усіма ознаками () та цільовим класом ( )
- Обрати ознаку з найвищим балом (наприклад, ), і додати її до набору обраних ознак ()
- Обчислити похідну оцінку, яку може бути виведено із взаємної інформації
- Обрати ознаку з найвищим балом, і додати її до набору обраних ознак (наприклад, )
- Повторювати 3. та 4., допоки не буде обрано певне число ознак (наприклад, )






Найпростіший підхід як цю «похідну» оцінку використовує власне взаємну інформацію.[24]
Проте існують різні підходи, що намагаються знижувати надлишковість серед ознак.
Обирання ознак мінімальної-надлишковості-максимальної-доречності (mRMR)
Пен та ін.[25] запропонували метод обирання ознак, що може використовувати для обирання ознак або взаємну інформацію, кореляцію, або відстань/бали схожості. Мета полягає у штрафуванні доречності (англ. relevancy) ознаки її надлишковістю (англ. redundancy) в присутності інших обраних ознак. Доречність набору ознак S для класу c визначають усередненим значенням усіх значень взаємної інформації між окремою ознакою fi та класом c таким чином:
- .

Надлишковістю всіх ознак у множині S є усереднене значення всіх значень взаємної інформації між ознакою fi та ознакою fj:

Критерій мінімальної-надлишковості-максимальної-доречності (англ. minimum-redundancy-maximum-relevance, mRMR) є поєднанням двох наведених вище мір, і його визначено наступним чином:

Припустімо, що є n ознак повної множини. Нехай xi буде індикаторною функцією членства ознаки fi в множині, такою, що xi=1 показує наявність, а xi=0 показує відсутність ознаки fi в глобально оптимальній множині ознак. Нехай , а . Наведене вище може бути записано як задачу оптимізації:



Алгоритм mRMR є наближенням теоретично оптимального максимально-залежнісного алгоритму обирання ознак, який максимізує взаємну інформацію між спільним розподілом обраних ознак та змінною класифікації. Оскільки mRMR наближує задачу комбінаторної оцінки рядом набагато менших задач, кожна з яких включає лише дві змінні, він таким чином використовує попарні спільні ймовірності, що є надійнішими. В деяких ситуаціях цей алгоритм може недооцінювати корисність ознак, оскільки він не має способу вимірювати взаємодії між ознаками, що можуть збільшувати доречність. Це може призводити до поганої продуктивності,[24] коли ознаки є марними поодинці, але корисними у поєднанні (патологічний випадок трапляється, коли клас є функцією парності ознак). В цілому цей алгоритм є ефективнішим (у термінах кількості потрібної інформації) за теоретично оптимальне максимально-залежнісне обирання, хоча й виробляє набір ознак із невеликою попарною надлишковістю.
mRMR є примірником більшого класу фільтрових методів, які шукають компроміс між доречністю та надлишковістю відмінними шляхами.[24][26]
Обирання ознак квадратичним програмуванням
mRMR є типовим прикладом приростової жадібної стратегії обирання ознак: щойно ознаку було обрано, її не може бути виключено на пізнішому етапі. І хоча mRMR може бути оптимізовано застосуванням рухливого пошуку (англ. floating search) для скорочування деяких ознак, його також може бути переформульовано як задачу глобальної оптимізації квадратичного програмування (англ. quadratic programming feature selection, QPFS) таким чином:[27]
- т. щ.


де є вектором доречності ознак, за припущення, що загалом є n ознак, є матрицею попарної надлишковості ознак, а представляє відносні ваги ознак. QPFS розв'язується за допомогою квадратичного програмування. Нещодавно було показано, що QPFS має схильність до ознак із меншою ентропією,[28] тому що воно ставить член самонадлишковості ознаки на діагональ H.




Умовна взаємна інформація
Інша оцінка, що виводять із взаємної інформації, ґрунтується на умовній доречності:[28]
- т. щ.


де , а .


Перевага SPECCMI полягає в тому, що воно може розв'язуватися просто знаходженням домінантного власного вектора Q, і тому є дуже масштабовуваним. Також SPECCMI обробляє взаємодії ознак другого порядку.
Спільна взаємна інформація
У дослідженні різних балів Браун та ін.[24] рекомендували як добрий бал для обирання ознак спільну взаємну інформацію.[29] Цей бал намагається знайти ознаку, що додає найбільше нової інформації до вже відомих ознак, щоби уникати надмірності. Цей бал сформульовано наступним чином:

Цей бал використовує умовну взаємну інформацію для оцінювання надмірності між вже обраними ознаками () та досліджуваною ознакою ().


Обирання ознак на основі LASSO критерію незалежності Гільберта-Шмідта
Для даних із високою розмірністю та малою вибіркою (наприклад, розмірність > 105, а кількість зразків < 103) корисним є LASSO критерію незалежності Гільберта-Шмідта (англ. Hilbert-Schmidt Independence Criterion Lasso, HSIC Lasso).[30] Задачу оптимізації HSIC Lasso задають як
- т. щ.


де є мірою незалежності на ядровій основі, що називають (емпіричним) критерієм незалежності Гільберта-Шмідта (англ. Hilbert-Schmidt independence criterion, HSIC), позначає слід, є регуляризаційним параметром, та є центрованими матрицями Ґрама входу та виходу, та є матрицями Ґрама, та є ядровими функціями, є центрувальною матрицею, є m-вимірною одиничною матрицею (m — кількість зразків), є m-вимірним вектором з усіма одиницями, а є -нормою. HSIC завжди набуває невід'ємного значення, і є нулем тоді й лише тоді, коли дві випадкові змінні є статистично незалежними при використанні універсального відтворювального ядра, такого як ґаусове.














HSIC Lasso також може бути записано як
- т. щ.

де є нормою Фробеніуса. Ця задача оптимізації є задачею LASSO, і відтак її можливо ефективно розв'язувати передовим розв'язувачем LASSO, таким як подвійний метод розширеного Лагранжіана.

Кореляційне обирання ознак
Міра кореляційного обирання ознак (англ. Correlation Feature Selection, CFS) оцінює підможину ознак на основі наступної гіпотези: «Добрі підмножини ознак містять ознаки, високо корельовані з класифікацією, але некорельовані між собою».[31][32] Наступне рівняння задає якість підмножини ознак S, що складається із k ознак:

Тут є усередненим значенням усіх кореляцій ознака-класифікація, а є усередненим значенням усіх кореляцій ознака-ознака. Критерій CFS визначають наступним чином:



Змінні та називають кореляціями, але вони не обов'язково є коефіцієнтами кореляції Пірсона або ρ Спірмена. Дисертація доктора Марка Голла (англ. Mark Hall) не використовує жодного з цих, але використовує три відмінні міри пов'язаності, мінімальну довжину опису (англ. minimum description length, MDL), симетричну невизначеність та relief.


Нехай xi буде індикаторною функцією членства ознаки fi; тоді наведене вище може бути переписано як задачу оптимізації:

Комбінаторні задачі вище є, фактично, задачами змішаного двійкового лінійного програмування, які можливо розв'язувати застосуванням алгоритмів гілок та меж.[33]
Регуляризовані дерева
Ознаки з дерева або ансамблю дерев рішень виявляються надлишковими. Для обирання підмножини ознак можливо застосовувати нещодавній метод, названий регуляризованим деревом.[34] Регуляризовані дерева здійснюють штрафування, використовуючи для розділення поточного вузла змінну, подібну до змінних, вибраних на попередніх вузлах дерева. Регуляризовані дерева потребують побудови лише однієї деревної моделі (або однієї моделі ансамблю дерев), і, отже, є обчислювально ефективними.
Регуляризовані дерева природно обробляють числові та категорійні ознаки, взаємодії та нелінійності. Вони є інваріантними відносно масштабів (одиниць виміру) атрибутів та нечутливими до викидів, і, таким чином, вимагають незначної попередньої обробки даних, такої як нормалізація. Одним із типів регуляризованих дерев є регуляризований випадковий ліс (РВЛ, англ. Regularized random forest, RRF).[35] Цей керований РВЛ є розширеним РВЛ, що керується балами важливості зі звичайного випадкового лісу.
Огляд метаевристичних методів
Метаевристика є загальним описом алгоритму, присвяченого розв'язанню складних (зазвичай, NP-складних) задач оптимізації, для яких не існує класичних методів розв'язання. Загалом, метаевристика є стохастичним алгоритмом, який веде до досягнення глобального оптимуму. Існує багато метаевристик, від простого локального пошуку, і до алгоритму складного глобального пошуку.
Головні принципи
Методи обирання ознак зазвичай представляють трьома класами на основі того, як вони поєднують алгоритм обирання та побудову моделі.
Фільтровий метод
Методи фільтрового типу обирають змінні незалежно від моделі. Вони ґрунтуються лише на загальних ознаках, таких як кореляція з передбачуваною змінною. Фільтрові методи придушують найменш цікаві змінні. Інші змінні будуть частиною моделі класифікації або регресії, яку застосовують для класифікування або передбачення даних. Ці методи є особливо ефективними з точки зору обчислювального часу, та стійкими до перенавчання.[36]
Фільтрові методи схильні обирати надлишкові змінні, коли вони не беруть до уваги взаємовідношення між змінними. Проте більш продумані функції, такі як алгоритм FCBF,[37] намагаються й мінімізують цю проблему шляхом усування сильно корельованих між собою змінних.
Обгортковий метод
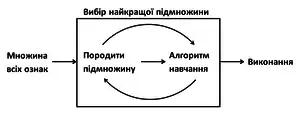
Обгорткові методи оцінюють підмножини змінних, що дозволяє, на відміну від фільтрових підходів, виявляти можливі взаємодії між змінними.[38] Двома головними недоліками цих методів є:
- Підвищення ризику перенавчання за недостатньої кількості спостережень.
- Значний обчислювальний час за великої кількості змінних.
Вбудований метод

Нещодавно було запропоновано вбудовані методи, які намагаються поєднувати переваги обох попередніх методів. Алгоритм навчання отримує перевагу від свого власного процесу обирання змінних, і виконує обирання ознак та класифікування одночасно, як це робить алгоритм FRMT.[39]
Застосування метаевристик обирання ознак
Це огляд застосувань метаевристик обирання ознак, що останнім часом використовували в літературі. Цей огляд було реалізовано Дж. Геммон (англ. J. Hammon) в її дисертації 2013 року.[36]
| Застосування | Алгоритм | Підхід | класифікатор | Оцінна функція | Посилання |
|---|---|---|---|---|---|
| ОНП | Обирання ознак за схожістю | Фільтр | r2 | Phuong 2005[38] | |
| ОНП | Генетичний алгоритм | Обгортка | Дерево рішень | Точність класифікації (10-кратна) | Shah 2004[40] |
| ОНП | Підйом схилом | Фільтр + обгортка | Наївний баєсів | Predicted residual sum of squares | Long 2007[41] |
| ОНП | Імітація відпалу | Наївний баєсів | Точність класифікації (5-кратна) | Ustunkar 2011[42] | |
| Мовна сегментація | Мурашиний алгоритм | Обгортка | Штучна нейронна мережа | СКП | Al-ani 2005 [джерело?] |
| Маркетинг | Імітація відпалу | Обгортка | Регресія | ІКА, r2 | Meiri 2006[43] |
| Економіка | Імітація відпалу, генетичний алгоритм | Обгортка | Регресія | БІК | Kapetanios 2005[44] |
| Спектральна маса | Генетичний алгоритм | Обгортка | Множинна лінійна регресія, частинні найменші квадрати | Коренева середньоквадратична похибка передбачення | Broadhurst 2007[45] |
| Спам | Двійковий МРЧ + мутація | Обгортка | Дерево рішень | Зважені витрати | Zhang 2014[15] |
| Мікрочипи | Табу-пошук + МРЧ | Обгортка | Метод опорних векторів, k найближчих сусідів | Евклідова відстань | Chuang 2009[46] |
| Мікрочипи | МРЧ + генетичний алгоритм | Обгортка | Метод опорних векторів | Точність класифікації (10-кратна) | Alba 2007[47] |
| Мікрочипи | Генетичний алгоритм + ітеративний локальний пошук | Вбудований | Метод опорних векторів | Точність класифікації (10-кратна) | Duval 2009[48] |
| Мікрочипи | Ітеративний локальний пошук | Обгортка | Регресія | Апостеріорна ймовірність | Hans 2007[49] |
| Мікрочипи | Генетичний алгоритм | Обгортка | k найближчих сусідів | Точність класифікації (перехресне затверджування з виключенням по одному) | Jirapech-Umpai 2005[50] |
| Мікрочипи | Гібридний генетичний алгоритм | Обгортка | k найближчих сусідів | Точність класифікації (перехресне затверджування з виключенням по одному) | Oh 2004[51] |
| Мікрочипи | Генетичний алгоритм | Обгортка | Метод опорних векторів | Чутливість і специфічність | Xuan 2011[52] |
| Мікрочипи | Генетичний алгоритм | Обгортка | Повноспарований метод опорних векторів | Точність класифікації (перехресне затверджування з виключенням по одному) | Peng 2003[53] |
| Мікрочипи | Генетичний алгоритм | Вбудований | Метод опорних векторів | Точність класифікації (10-кратна) | Hernandez 2007[54] |
| Мікрочипи | Генетичний алгоритм | Гібридний | Метод опорних векторів | Точність класифікації (перехресне затверджування з виключенням по одному) | Huerta 2006[55] |
| Мікрочипи | Генетичний алгоритм | Метод опорних векторів | Точність класифікації (10-кратна) | Muni 2006[56] | |
| Мікрочипи | Генетичний алгоритм | Обгортка | Метод опорних векторів | EH-DIALL, CLUMP | Jourdan 2004[57] |
| Хвороба Альцгеймера | t-перевірка Велша | Фільтр | Ядровий метод опорних векторів | Точність класифікації (10-кратна) | Zhang 2015[58] |
| Комп'ютерне бачення | Нескінченне обирання ознак | Фільтр | Незалежний | Усереднена чіткість, ППК РХП | Roffo 2015[59] |
| Мікрочипи | ВО центральністю власного вектора | Фільтр | Незалежний | Усереднена чіткість, Точність, ППК РХП | Roffo & Melzi 2016[60] |
| XML | Симетрична Тау (англ. ST) | Фільтр | Структурна асоціативна класифікація | Точність, Покриття | Shaharanee & Hadzic 2014 |
Обирання ознак, вбудоване до алгоритмів навчання
Деякі алгоритми навчання виконують обирання ознак як частину своєї загальної роботи. До них належать:
- Методики -регуляризації, такі як розріджена регресія, LASSO, та -МОВ
- Регуляризовані дерева,[34] наприклад, регуляризований випадковий ліс, втілений у пакеті RRF[35]
- Дерева рішень[61]
- Меметичний алгоритм
- Випадковий поліноміальний логіт (англ. Random multinomial logit, RMNL)
- Автокодувальні мережі з рівнем — вузьким місцем
- Субмодулярне обирання ознак[62][63][64]
- Обирання ознак на основі локального навчання.[65] В порівнянні з традиційними методами, він не передбачає жодного евристичного пошуку, може легко впоруватися з полікласовими задачами, і працює як для лінійних, так і для нелінійних задач. Він також підтримується сильним теоретичним підґрунтям. Чисельні експерименти показали, що цей метод може досягати близького до оптимального розв'язку навіть коли дані містять понад мільйон недоречних ознак.

Див. також
- Кластерний аналіз
- Добування даних
- Зниження розмірності
- Виділяння ознак
- Оптимізація гіперпараметрів
- Relief (обирання ознак)
Примітки
- Gareth James; Daniela Witten; Trevor Hastie; Robert Tibshirani (2013). An Introduction to Statistical Learning. Springer. с. 204. (англ.)
- Bermingham, Mairead L.; Pong-Wong, Ricardo; Spiliopoulou, Athina; Hayward, Caroline; Rudan, Igor; Campbell, Harry; Wright, Alan F.; Wilson, James F.; Agakov, Felix; Navarro, Pau; Haley, Chris S. (2015). Application of high-dimensional feature selection: evaluation for genomic prediction in man. Sci. Rep. 5: 10312. Bibcode:2015NatSR...510312B. PMC 4437376. PMID 25988841. doi:10.1038/srep10312. (англ.)
- Guyon, Isabelle; Elisseeff, André (2003). An Introduction to Variable and Feature Selection. JMLR 3. (англ.)
- Yang, Yiming; Pedersen, Jan O. (1997). A comparative study on feature selection in text categorization ICML. (англ.)
- Urbanowicz, Ryan J.; Meeker, Melissa; LaCava, William; Olson, Randal S.; Moore, Jason H. (2017-11-22). «Relief-Based Feature Selection: Introduction and Review». arXiv:1711.08421 [cs.DS]. (англ.)
- Forman, George (2003). An extensive empirical study of feature selection metrics for text classification. Journal of Machine Learning Research 3: 1289–1305. (англ.)
- Yishi Zhang; Shujuan Li; Teng Wang; Zigang Zhang (2013). Divergence-based feature selection for separate classes. Neurocomputing 101 (4): 32–42. doi:10.1016/j.neucom.2012.06.036. (англ.)
- Guyon I.; Weston J.; Barnhill S.; Vapnik V. (2002). Gene selection for cancer classification using support vector machines. Machine Learning 46 (1-3): 389–422. doi:10.1023/A:1012487302797. (англ.)
- Bach, Francis R (2008). Bolasso: model consistent lasso estimation through the bootstrap. Proceedings of the 25th International Conference on Machine Learning. с. 33–40. ISBN 9781605582054. doi:10.1145/1390156.1390161. (англ.)
- Zare, Habil (2013). Scoring relevancy of features based on combinatorial analysis of Lasso with application to lymphoma diagnosis. BMC Genomics 14: S14. PMC 3549810. PMID 23369194. doi:10.1186/1471-2164-14-S1-S14. (англ.)
- Soufan, Othman; Kleftogiannis, Dimitrios; Kalnis, Panos; Bajic, Vladimir B. (26 лютого 2015). DWFS: A Wrapper Feature Selection Tool Based on a Parallel Genetic Algorithm. PLOS One (англ.) 10 (2): e0117988. Bibcode:2015PLoSO..1017988S. ISSN 1932-6203. PMC 4342225. PMID 25719748. doi:10.1371/journal.pone.0117988. (англ.)
- Figueroa, Alejandro (2015). Exploring effective features for recognizing the user intent behind web queries. Computers in Industry 68: 162–169. doi:10.1016/j.compind.2015.01.005. (англ.)
- Figueroa, Alejandro; Guenter Neumann (2013). Learning to Rank Effective Paraphrases from Query Logs for Community Question Answering AAAI. (англ.)
- Figueroa, Alejandro; Guenter Neumann (2014). Category-specific models for ranking effective paraphrases in community Question Answering. Expert Systems with Applications 41 (10): 4730–4742. doi:10.1016/j.eswa.2014.02.004. (англ.)
- Zhang, Y.; Wang, S.; Phillips, P. (2014). Binary PSO with Mutation Operator for Feature Selection using Decision Tree applied to Spam Detection. Knowledge-Based Systems 64: 22–31. doi:10.1016/j.knosys.2014.03.015. (англ.)
- F.C. Garcia-Lopez, M. Garcia-Torres, B. Melian, J.A. Moreno-Perez, J.M. Moreno-Vega. Solving feature subset selection problem by a Parallel Scatter Search, European Journal of Operational Research, vol. 169, no. 2, pp. 477–489, 2006. (англ.)
- F.C. Garcia-Lopez, M. Garcia-Torres, B. Melian, J.A. Moreno-Perez, J.M. Moreno-Vega. Solving Feature Subset Selection Problem by a Hybrid Metaheuristic Архівовано 30 серпня 2019 у Wayback Machine.. In First International Workshop on Hybrid Metaheuristics, pp. 59–68, 2004. (англ.)
- M. Garcia-Torres, F. Gomez-Vela, B. Melian, J.M. Moreno-Vega. High-dimensional feature selection via feature grouping: A Variable Neighborhood Search approach, Information Sciences, vol. 326, pp. 102-118, 2016. (англ.)
- Kraskov, Alexander; Stögbauer, Harald; Andrzejak, Ralph G; Grassberger, Peter (2003). Hierarchical Clustering Based on Mutual Information. Bibcode:2003q.bio....11039K. arXiv:q-bio/0311039. (англ.)
- Akaike, H. (1985). Prediction and entropy. У Atkinson, A. C.; Fienberg, S. E.. A Celebration of Statistics. Springer. с. 1–24.. (англ.)
- Burnham, K. P.; Anderson, D. R. (2002). Model Selection and Multimodel Inference: A practical information-theoretic approach (вид. 2nd). Springer-Verlag.. (англ.)
- Einicke, G. A. (2018). Maximum-Entropy Rate Selection of Features for Classifying Changes in Knee and Ankle Dynamics During Running. IEEE Journal of Biomedical and Health Informatics 28 (4): 1097–1103. PMID 29969403. doi:10.1109/JBHI.2017.2711487. (англ.)
- Aliferis, Constantin (2010). Local causal and markov blanket induction for causal discovery and feature selection for classification part I: Algorithms and empirical evaluation. Journal of Machine Learning Research 11: 171–234. (англ.)
- Brown, Gavin; Pocock, Adam; Zhao, Ming-Jie; Luján, Mikel (2012). Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection. Journal of Machine Learning Research 13: 27–66. (англ.)
- Peng, H. C.; Long, F.; Ding, C. (2005). Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence 27 (8): 1226–1238. PMID 16119262. doi:10.1109/TPAMI.2005.159. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) Програма - Nguyen, H., Franke, K., Petrovic, S. (2010). "Towards a Generic Feature-Selection Measure for Intrusion Detection", In Proc. International Conference on Pattern Recognition (ICPR), Istanbul, Turkey. (англ.)
- Rodriguez-Lujan, I.; Huerta, R.; Elkan, C.; Santa Cruz, C. (2010). Quadratic programming feature selection. JMLR 11: 1491–1516. (англ.)
- Nguyen X. Vinh, Jeffrey Chan, Simone Romano and James Bailey, "Effective Global Approaches for Mutual Information based Feature Selection". Proceedings of the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'14), August 24–27, New York City, 2014. "" (англ.)
- Yang, Howard Hua; Moody, John (2000). Data visualization and feature selection: New algorithms for nongaussian data. Advances in Neural Information Processing Systems: 687–693. (англ.)
- M. Yamada, W. Jitkrittum, L. Sigal, E. P. Xing, M. Sugiyama, High-Dimensional Feature Selection by Feature-Wise Non-Linear Lasso. Neural Computation, vol.26, no.1, pp.185-207, 2014. (англ.)
- M. Hall 1999, Correlation-based Feature Selection for Machine Learning (англ.)
- Senliol, Baris, et al. "Fast Correlation Based Filter (FCBF) with a different search strategy." Computer and Information Sciences, 2008. ISCIS'08. 23rd International Symposium on. IEEE, 2008. (англ.)
- Hai Nguyen, Katrin Franke, and Slobodan Petrovic, Optimizing a class of feature selection measures, Proceedings of the NIPS 2009 Workshop on Discrete Optimization in Machine Learning: Submodularity, Sparsity & Polyhedra (DISCML), Vancouver, Canada, December 2009. (англ.)
- H. Deng, G. Runger, "Feature Selection via Regularized Trees", Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), IEEE, 2012 (англ.)
- RRF: Regularized Random Forest, пакет R на CRAN (англ.)
- J. Hammon. Optimisation combinatoire pour la sélection de variables en régression en grande dimension : Application en génétique animale. November 2013 (фр.)
- https://www.aaai.org/Papers/ICML/2003/ICML03-111.pdf. (англ.)
- T. M. Phuong, Z. Lin et R. B. Altman. Choosing SNPs using feature selection. Архівовано 13 вересня 2016 у Wayback Machine. Proceedings / IEEE Computational Systems Bioinformatics Conference, CSB. IEEE Computational Systems Bioinformatics Conference, pages 301-309, 2005. PubMed. (англ.)
- Saghapour E, Kermani S, Sehhati M (2017) A novel feature ranking method for prediction of cancer stages using proteomics data. PLOS ONE 12(9): e0184203. https://doi.org/10.1371/journal.pone.0184203 (англ.)
- Shah, S. C.; Kusiak, A. (2004). Data mining and genetic algorithm based gene/SNP selection. Artificial Intelligence in Medicine 31 (3): 183–196. PMID 15302085. doi:10.1016/j.artmed.2004.04.002. (англ.)
- Long, N.; Gianola, D.; Weigel, K. A (2011). Dimension reduction and variable selection for genomic selection : application to predicting milk yield in Holsteins. Journal of Animal Breeding and Genetics 128 (4): 247–257. PMID 21749471. doi:10.1111/j.1439-0388.2011.00917.x. (англ.)
- G. Ustunkar, S. Ozogur-Akyuz, G. W. Weber, C. M. Friedrich et Yesim Aydin Son. Selection of representative SNP sets for genome-wide association studies : a metaheuristic approach. Optimization Letters, November 2011. (англ.)
- R. Meiri et J. Zahavi. Using simulated annealing to optimize the feature selection problem in marketing applications. European Journal of Operational Research, vol. 171, no. 3, pages 842-858, Juin 2006 (англ.)
- G. Kapetanios. Variable Selection using Non-Standard Optimisation of Information Criteria. Working Paper 533, Queen Mary, University of London, School of Economics and Finance, 2005. (англ.)
- D. Broadhurst, R. Goodacre, A. Jones, J. J. Rowland et D. B. Kell. Genetic algorithms as a method for variable selection in multiple linear regression and partial least squares regression, with applications to pyrolysis mass spectrometry. Analytica Chimica Acta, vol. 348, no. 1-3, pages 71-86, August 1997. (англ.)
- Chuang, L.-Y.; Yang, C.-H. (2009). Tabu search and binary particle swarm optimization for feature selection using microarray data. Journal of Computational Biology 16 (12): 1689–1703. PMID 20047491. doi:10.1089/cmb.2007.0211. (англ.)
- E. Alba, J. Garia-Nieto, L. Jourdan et E.-G. Talbi. Gene Selection in Cancer Classification using PSO-SVM and GA-SVM Hybrid Algorithms. Congress on Evolutionary Computation, Singapor : Singapore (2007), 2007 (англ.)
- B. Duval, J.-K. Hao et J. C. Hernandez Hernandez. A memetic algorithm for gene selection and molecular classification of an cancer. In Proceedings of the 11th Annual conference on Genetic and evolutionary computation, GECCO '09, pages 201-208, New York, NY, USA, 2009. ACM. (англ.)
- C. Hans, A. Dobra et M. West. Shotgun stochastic search for 'large p' regression. Journal of the American Statistical Association, 2007. (англ.)
- Aitken, S. (2005). Feature selection and classification for microarray data analysis : Evolutionary methods for identifying predictive genes. BMC Bioinformatics 6 (1): 148. PMC 1181625. PMID 15958165. doi:10.1186/1471-2105-6-148. (англ.)
- Oh, I. S.; Moon, B. R. (2004). Hybrid genetic algorithms for feature selection. IEEE Transactions on Pattern Analysis and Machine Intelligence 26 (11): 1424–1437. PMID 15521491. doi:10.1109/tpami.2004.105. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Xuan, P.; Guo, M. Z.; Wang, J.; Liu, X. Y.; Liu, Y. (2011). Genetic algorithm-based efficient feature selection for classification of pre-miRNAs. Genetics and Molecular Research 10 (2): 588–603. PMID 21491369. doi:10.4238/vol10-2gmr969. (англ.)
- >Peng, S. (2003). Molecular classification of cancer types from microarray data using the combination of genetic algorithms and support vector machines. FEBS Letters 555 (2): 358–362. doi:10.1016/s0014-5793(03)01275-4. (англ.)
- J. C. H. Hernandez, B. Duval et J.-K. Hao. A genetic embedded approach for gene selection and classification of microarray data. In Proceedings of the 5th European conference on Evolutionary computation, machine learning and data mining in bioinformatics, EvoBIO'07, pages 90-101, Berlin, Heidelberg, 2007. SpringerVerlag. (англ.)
- E. B. Huerta, B. Duval et J.-K. Hao. A hybrid GA/SVM approach for gene selection and classification of microarray data. evoworkshops 2006, LNCS, vol. 3907, pages 34-44, 2006. (англ.)
- D. P. Muni, N. R. Pal et J. Das. Genetic programming for simultaneous feature selection and classifier design. IEEE Transactions on Systems, Man, and Cybernetics - Part B: Cybernetics : Cybernetics, vol. 36, no. 1, pages 106-117, February 2006. (англ.)
- L. Jourdan, C. Dhaenens et E.-G. Talbi. Linkage disequilibrium study with a parallel adaptive GA. International Journal of Foundations of Computer Science, 2004. (англ.)
- Zhang, Y.; Dong, Z.; Phillips, P.; Wang, S. (2015). Detection of subjects and brain regions related to Alzheimer's disease using 3D MRI scans based on eigenbrain and machine learning. Frontiers in Computational Neuroscience 9: 66. PMC 4451357. PMID 26082713. doi:10.3389/fncom.2015.00066. (англ.)
- Roffo, G.; Melzi, S.; Cristani, M. (1 грудня 2015). Infinite Feature Selection. 2015 IEEE International Conference on Computer Vision (ICCV). с. 4202–4210. ISBN 978-1-4673-8391-2. doi:10.1109/ICCV.2015.478. (англ.)
- Roffo, Giorgio; Melzi, Simone (September 2016). Features Selection via Eigenvector Centrality. NFmcp2016. Процитовано 12 листопада 2016. (англ.)
- R. Kohavi and G. John, "Wrappers for feature subset selection", Artificial intelligence 97.1-2 (1997): 273-324 (англ.)
- Das, Abhimanyu; Kempe, David (2011). «Submodular meets Spectral: Greedy Algorithms for Subset Selection, Sparse Approximation and Dictionary Selection». arXiv:1102.3975 [stat.ML]. (англ.)
- Liu et al, Submodular feature selection for high-dimensional acoustic score spaces Архівовано 17 жовтня 2015 у Wayback Machine. (англ.)
- Zheng et al, Submodular Attribute Selection for Action Recognition in Video Архівовано 18 листопада 2015 у Wayback Machine. (англ.)
- Y. Sun, S. Todorovic, S. Goodison (2010), "Local-Learning-Based Feature Selection for High-Dimensional Data Analysis", IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9): 1610-1626 (англ.)
Література
- Harrell, F. (2001). Regression Modeling Strategies. Springer. (англ.)
- Liu, Huan; Motoda, Hiroshi (1998). Feature Selection for Knowledge Discovery and Data Mining. Springer. (англ.)
- Special Issue on Variable and Feature Selection —Journal of Machine Learning Research (2003) (англ.)
- An Introduction to Variable and Feature Selection (огляд) (англ.)
- Toward integrating feature selection algorithms for classification and clustering (огляд) (англ.)
- Efficient Feature Subset Selection and Subset Size Optimization (огляд 2010 року) (англ.)
- "Searching for Interacting Features" —Zhao & Liu, представлена на IJCAI (2007) (англ.)
Посилання
- Пакет обирання ознак, Університет штату Аризона (код Matlab)
- Змагання NIPS 2003 року (див. також NIPS)
- Реалізація наївного баєсового класифікатора із обиранням ознак на Visual Basic (включає виконуваний та джерельний код)
- Програма обирання ознак мінімальної-надлишковості-максимальної-доречності (minimum-redundancy-maximum-relevance, mRMR)
- FEAST (відкриті алгоритми обирання ознак на C та MATLAB)