Часовий ряд
Часовий ряд (англ. time series) — це ряд точок даних, проіндексованих (або перелічених, або відкладених на графіку) в хронологічному порядку. Найчастіше часовий ряд є послідовністю, взятою на рівновіддалених точках в часі, які йдуть одна за одною. Таким чином, він є послідовністю даних дискретного часу. Прикладами часових рядів є висоти океанських припливів, кількості сонячних плям, та щоденне середньозважене значення індексу ПФТС на момент закриття торгів.
Часові ряди дуже часто представляють за допомогою лінійних діаграм. Часові ряди використовуються в статистиці, обробці сигналів, розпізнаванні образів, економетриці, фінансовій математиці, прогнозуванні погоди, розумному транспорті та передбаченні траєкторій,[1] передбаченні землетрусів, електроенцефалографії, автоматичному керуванні, астрономії, технологіях зв'язку, а також значною мірою в будь-якій області прикладної науки та інженерії, яка включає часові вимірювання.
Аналіз часових рядів (англ. time series analysis) включає методи аналізу даних часових рядів з метою витягування значимих статистик та інших характетистик даних. Прогнозування часових рядів (англ. time series forecasting) — це застосування моделі для передбачування майбутніх значень на основі значень попередньо спостережених. І хоча регресійний аналіз часто застосовують для перевірки теорій про те, що поточні значення одного чи більше незалежних часових рядів впливають на поточне значення іншого часового ряду, цей тип аналізу часових рядів не називають «аналізом часових рядів», який натомість зосереджується на порівнянні значень одного часового ряду або багатьох залежних часових рядів у різні моменти часу.[2]
Дані часових рядів мають природний часовий порядок. Це робить аналіз часових рядів відмінним від поперечних досліджень, у яких не існує природного порядку спостережень (наприклад, пояснення заробітної платні людей через посилання на їхні рівні освіти, де дані осіб можуть вводитися у будь-якому порядку). Аналіз часових рядів відрізняється також і від аналізу просторових даних, де спостереження зазвичай відносяться до географічних розташувань (наприклад, підрахунок цін на будинки за розташуванням, а також за власними характеристиками цих будинків). Стохастична модель часового ряду, як правило, відображатиме той факт, що спостереження, які знаходяться близько в часі, будуть пов'язані тісніше, ніж спостереження, які знаходяться далі одне від одного. Крім того, моделі часових рядів часто застосовують природне односпрямоване впорядкування часу, так, що значення для заданого періоду виражено як похідні від минулих значень, а не від майбутніх (див. зворотність часу).
Аналіз часових рядів може застосовуватися до дійснозначних неперервних даних, дискретних числових даних, та дискретних символьних даних (наприклад, послідовностей символів, таких як літери та слова української мови).[3]
Методи аналізу часових рядів
Методи аналізу часових рядів може бути розділено на два класи: методи частотної області, та методи часової області. Перші включають спектральний та вейвлетний аналіз, другі — аналіз автокореляції та взаємної кореляції. У часовій області кореляція та аналіз можуть здійснюватися фільтроподібним чином із застосуванням масштабної кореляції, зменшуючи таким чином потребу діяти в частотній області.
Методики аналізу часових рядів можуть додатково поділятися на параметричні та непараметричні. Параметричні підходи передбачають, що стаціонарний стохастичний процес, який лежить в основі даних, має певну структуру, яку може бути описано із застосуванням невеликого числа параметрів (наприклад, із застосуванням авторегресійної моделі, або моделі ковзного середнього). В цих підходах задачєю є оцінити параметри моделі, яка описує цей стохастичний процес. На противагу цьому, непараметричні підходи явно оцінюють коваріацію або спектр процесу без припущення про наявність у цього процесу якоїсь певної структури.
Методи аналізу часових рядів також може бути розділено на лінійні й нелінійні, та на одновимірні й багатовимірні.
Часові ряди та панельні дані
Часові ряди є одним із типів панельних даних. Панельні дані є загальним класом, багатовимірним набором даних, тоді як набір даних часового ряду є одновимірною панеллю (як і набір перехресних даних). Набір даних може демонструвати характеристики як панельних даних, так і даних часового ряду. Одним зі способів сказати це, є спитати, що робить один запис даних унікальним відносно інших записів. Якщо відповіддю буде поле даних часу, то цей набір даних є кандидатом до наборів даних часових рядів. Якщо визначення унікального запису вимагає поля даних часу та додаткового ідентифікатора, не пов'язаного з часом (ідентифікатора студента, тікерної назви, коду країни), то цей набір даних є кандидатом до панельних даних. Якщо розмежування покладається на нечасовий ідентифікатор, то такий набір даних є кандидатом до наборів перехресних даних.
Методика прогнозування
Прогнозні оцінки за допомогою методів екстраполяції розраховуються в кілька етапів:
- перевірка базової лінії прогнозу;
- виявлення закономірностей минулого розвитку явища;
- оцінка ступеня достовірності виявленої закономірності розвитку явища в минулому (підбір трендової функції);
- екстраполювання — перенесення виявлених закономірностей на деякий період майбутнього;
- коректування отриманого прогнозу з урахуванням результатів змістовного аналізу поточного стану.
Для отримання об'єктивного прогнозу розвитку досліджуваного явища дані базової лінії повинні відповідати таким вимогам:
- крок за часом для всієї базової лінії повинен бути однаковий;
- спостереження фіксуються в один і той же момент кожного часового відрізку (наприклад, на полудень кожного дня, першого числа кожного місяця);
- базова лінія повинна бути повною, тобто пропуск даних не допускається.
Якщо у спостереженнях відсутні результати за незначний відрізок часу, то для забезпечення повноти базової лінії необхідно їх заповнити приблизними даними, наприклад, використовувати середнє значення сусідніх відрізків.
Коректування отриманого прогнозу виконується для уточнення отриманих довгострокових прогнозів з урахуванням впливу сезонності або стрибкоподібності розвитку досліджуваного явища.
Аналіз
Для часових рядів існує кілька типів задач і типів аналізу даних, які підходять для різних цілей тощо.
Задачі
- Описання
- Зазвичай, відображення часового ряду у вигляді графіка є першим кроком при його аналізі. Існують потужніші інструменти аналізу часового ряду, однак графік часового ряду дозволяє швидко отримати інформацію про найпростіші характеристики ряду, помітити поворотні точки тощо.
- Пояснення
- Якщо спостереження ведуться за декількома змінними, існує можливість використання інформації часового ряду для пояснення впливу змін в одному ряді на інший. Корисним методом дослідження залежностей є регресійний аналіз.[4] Обчислення передавальної функції системи — визначення динамічної моделі вхід — вихід; за допомогою цієї моделі можна визначити ефект на виході динамічної системи за довільно визначеними параметрами на її вході.[5]
- Прогнозування
- Використання доступних на момент результатів спостереження за часовим рядом для обчислення його значень в момент може бути основою для а) планування в економіці та торгівлі; б) планування випуску продукції; в) складського контролю та контролю виробництва; г) керування та оптимізації промислових процесів;[5] д) в політології — для дослідження того, як варіюються фактори підтримки глав держав, гонки озброєнь, політичного ділового циклу, політична підтримка та урядові витрати.[6]
- Керування
- Проектування простих систем управління з прямим та зворотним зв'язком, із допомогою яких можливо в максимально допустимих межах компенсувати потенціальні відхилення системи від бажаного значення.


В контексті статистики, економерії, фінансової математики, сейсмології, метеорології та геофізики головною метою аналізу часових рядів є прогнозування. В контексті обробки сигналів, автоматичного керування та технологій зв'язку він застосовується для виявлення та оцінювання сигналу, тоді як у контексті добування даних, розпізнавання образів та машинного навчання аналіз часових рядів може застосовуватися для кластерування, класифікації, запитів за вмістом, виявлення аномалій, а також і для прогнозування.
Розвідувальний аналіз
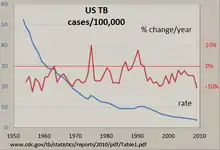
Найясніший спосіб вивчення регулярних часових рядів вручну — це Лінійна діаграма, така, як показана діаграма захворюваності на сухоти в США, зроблена за допомогою електронних таблиць. Число випадків захворювання нормалізовано до рівня на 100 000, і обчислено відсоткову зміну цього рівня за рік. Майже неухильно спадна лінія показує, що захворюваність на сухоти знижувалася в більшості років, але відсоткова зміна цього рівня коливалася аж на +/- 10 %, зі «сплесками» 1975 року та приблизно на початку 1990-х років. Застосування обох вертикальних осей уможливлює порівняння двох часових рядів на одному графіку.
До інших методик належать:
- Автокореляційний аналіз для дослідження періодичної залежності
- Спектральний аналіз для дослідження циклічної поведінки, не обов'язково пов'язаної із сезонністю. Наприклад, активність сонячних плям змінюється протягом 11-річних циклів.[7][8] До інших звичних прикладів належать небесні явища, погодні умови, нейронна активність, ціни на біржові товари, та економічна активність.
- Поділ на складові, які представляють тенденцію, сезонність, повільні та швидкі зміни, та циклічну нерівномірність: див. оцінку тенденції та розклад часових рядів.
Допасовування кривої
Детальніші відомості з цієї теми ви можете знайти в статті Допасовування кривої.
Допасовування кривої (англ. curve fitting)[9][10] — це процес побудови кривої, або математичної функції, яка має найкращу допасованість до ряду точок даних,[11] можливо, з урахуванням обмежень.[12][13] Допасовування кривої може включати або інтерполювання,[14][15] коли вимагається точна допасованість до даних, або згладжування,[16][17] в якому будується «плавна» функція, яка допасовується до даних наближено. Пов'язаною темою є регресійний аналіз,[18][19] що зосереджується більше на питаннях статистичного висновування, таких як скільки невизначеності є в кривій, яку допасовано до даних, спостережених із випадковими помилками. Допасовані криві можуть використовуватися як допомога для унаочнення даних,[20][21] для отримування висновків про значення функції там, де дані відсутні,[22] та для підбиття взаємозв'язку між двома чи більше змінними.[23] Екстраполювання стосується застосування допасованої кривої за межами області спостережених даних,[24] і є предметом ступеню невизначеності,[25] оскільки воно може відображати метод, використаний для побудови кривої, настільки ж, наскільки воно відображає спостережені дані.
Побудова економічних часових рядів включає оцінювання деяких складових на деякі дати шляхом інтерполювання між значеннями («орієнтирами») для раніших й пізніших дат. Інтерполювання є оцінюванням невідомого значення між двома відомими значеннями (історичні дані), або здійсненням висновків про відсутню інформацію з інформації доступної («читання між рядками»).[26] Інтерполювання є корисним тоді, коли дані навколо відсутніх є доступними, і їхня тенденція, сезонність та довготривалі цикли є відомими. Воно часто здійснюється за допомогою застосуванням пов'язаних рядів, відомих для всіх відповідних дат.[27] Як альтернативу застосовують поліномну або сплайнову інтерполяцію, коли кусенево-поліномні функції допасовуються до часових інтервалів таким чином, що вони допасовуються плавно й одна до одної. Іншою задачею, тісто пов'язаною з інтерполюванням, є наближення складної функції простою (що також називають регресією. Основною відмінністю між регресією та інтерполюванням є те, що поліноміальна регресія дає єдиний поліном, що моделює весь набір даних. Сплайнове інтерполювання ж, натомість, для моделювання набору даних видає кусенево-неперервну функцію, складену з багатьох поліномів.
Екстраполювання — це процес оцінювання значення змінної за межами первинної області спостереження на основі її взаємозв'язку з іншою змінною. Воно є подібним до інтерполювання, що виробляє оцінки між відомими спостереженнями, але екстраполювання є предметом більшої невизначеності, й вищого ризику вироблення безглуздих результатів.
Наближення функцій
Детальніші відомості з цієї теми ви можете знайти в статті Наближення функцій.
Загалом, задача наближення функції полягає у виборі функції з чітко окресленого класу, яка близько підходить до цільової функції («наближує» її), характерним для цієї задачі способом. Можна розділяти два основні класи задач наближення функцій: По-перше, для відомих цільових функцій, Теорія наближення є галуззю чисельного аналізу, яка досліджує, як певні відомі функції (наприклад, спеціальні функції) можна наближувати певним класом функцій (наприклад, поліномами, або раціональними функціями), які часто мають бажані властивості (невитратне обчислення, неперервність, значення інтегралів та границь тощо).
По-друге, цільова функція, назвімо її g, може бути невідомою; замість явної формули, може бути надано лише набір точок (часовий ряд) вигляду (x, g(x)). В залежності від структури області визначення та множини значень g, можуть застосовуватися кілька методик наближення g. Наприклад, якщо g є оператором над дійсними числами, то можуть застосовуватися методики інтерполювання, екстраполювання, регресійного аналізу та допасовування кривих. Якщо множина (область) значень g є скінченною множиною, то ми натомість маємо справу із задачею класифікації. Пов'язаною задачею оперативного наближення часових рядів (англ. online time series approximation)[28] є узагальнення даних за один прохід, та побудова наближеного представлення, яке може підтримувати різноманітні запити до часових рядів з обмеженою найгіршою похибкою.
У якійсь мірі ці різні задачі (регресії, класифікації, наближення допасованості) отримали уніфіковане трактування в теорії статистичного навчання, де їх розглядають як задачі керованого навчання.
Передбачення та прогнозування
У статистиці передбачення є частиною статистичного висновування. Один із конкретних підходів до такого висновування відомий як передбачувальне висновування, але передбачення може проводитися з будь-яким із підходів до статистичного висновування. Справді, одним із описів статистики є те, що вона забезпечує засоби перенесення знань про вибірку із сукупності на всю сукупність, і на інші пов'язані сукупності, що не обов'язково є тим же, що й передбачення в часі. При перенесенні інформації в часі, часто на конкретні моменти часу, цей процес називається прогнозуванням.
- Повно сформовані статистичні моделі для задач стохастичного моделювання, такі, що можуть породжувати альтернативні версії часових рядів, представляючи, що могло би трапитися у не конкретні періоди часу в майбутньому.
- Прості або повно сформовані статистичні моделі для опису правдоподібних результатів часових рядів у безпосередньому майбутньому за заданого знання найнещодавніших результатів (прогнозування).
- Прогнозування на часових рядах зазвичай здійснюється із застосуванням автоматизованих статистичних програмних пакетів та мов програмування на кшталт R, S, SAS, SPSS, Minitab, pandas (Python) та багатьох інших.
Класифікація
Віднесення зразків часових рядів до певної категорії, наприклад, ідентифікування слова на основі ряду рухів рук мовою жестів.
Регресійний аналіз
Оцінювання майбутнього значення сигналу на основі його попередньої поведінки, наприклад, передбачування ціни акцій MSICH на основі попереднього руху їхньої ціни протягом цієї години, дня або місяця, або передбачування положення космічного корабля Аполлон-11 у певний майбутній момент на основі його поточної траєкторії (тобто, часового ряду його попередніх положень).[29] Регресійний аналіз зазвичай ґрунтується на статистичній інтерпретації властивостей часових рядів у часовій області визначення, започаткованій статистиками Джорджем Боксом та Ґвилимом Дженкінсом у 1950-х роках: див. метод Бокса — Дженкінса.
Оцінювання сигналів
Цей підхід ґрунтується на гармонічному аналізі та фільтруванні сигналів у частотній області із застосуванням перетворення Фур'є та оцінки спектральної густини, розробку яких було значно прискорено під час Другої світової війни математиком Норбертом Вінером, електроінженерами Рудольфом Калманом, Деннісом Габором та іншими для відфільтровування сигналу від шуму та передбачування значень сигналу на певний момент часу. Див. фільтр Калмана, теорію оцінювання та цифрову обробку сигналів.
Сегментування
Детальніші відомості з цієї теми ви можете знайти в статті Сегментування часових рядів.
Поділ часових рядів на послідовність сегментів. Часто трапляється так, що часовий ряд може бути представлено як послідовність окремих сегментів, кожен зі своїми характерними властивостями. Наприклад, звуковий сигнал із телефонної конференції може бути розділено на частини, які відповідають проміжкам часу, протягом яких говорила кожна з осіб. Метою сегментування часових рядів є визначити межові точки сегментів у часовому ряді, та охарактеризувати динамічні властивості, пов'язані з кожним із сегментів. Можна підходити до цієї задачі, застосовуючи виявлення точок змін, або моделювання часових рядів як складніших систем, таких як лінійні системи марковських стрибків.
Моделі
Моделі даних часових рядів можуть мати багато форм, і представляти різні стохастичні процеси. Три широкі класи, що становлять практичний інтерес при моделюванні змін рівня якогось процесу, складають авторегресійні моделі (англ. autoregressive models, AR models), інтегровані моделі (англ. integrated models, I models) та моделі ковзного середнього (англ. moving average models, MA models). Ці три класи залежать від попередніх точок даних лінійно.[30] Поєднання цих ідей дає модель авторегресії — ковзного середнього (англ. autoregressive–moving-average model, ARMA model) та модель авторегресії — інтегрованого ковзного середнього (англ. autoregressive integrated moving average model, ARIMA model). Модель авторегресії — дробово інтегрованого ковзного середнього (англ. autoregressive fractionally integrated moving average model, ARFIMA model) узагальнює три перші. Розширення цих методів для роботи з векторнозначними даними доступні під назвою багатовимірних моделей часових рядів (англ. multivariate time-series models), і іноді попередні абревіатури розширюються включенням початкової літери V від англ. vector (вектор), як у VAR для векторної авторегресії. Існує додатковий набір розширень цих моделей для застосування у випадках, коли спостережуваний часовий ряд ведеться певним «примушувальним» часовим рядом (який може не мати причинного впливу на спостережуваний ряд): відмінність від багатовимірного випадку полягає в тому, що змушувальний ряд може бути детермінованим, або перебувати під керуванням експериментатора. Для цих моделей акроніми розширюються завершувальною літерою X, від англ. exogenous (екзогенний).
Зацікавлення складає й нелінійна залежність рівня ряду від попередніх точок даних, почасти через можливість отримання хаотичних часових рядів. Проте, що важливіше, емпіричні дослідження можуть показувати переваги застосування передбачень, отриманих від нелінійних моделей, над отриманими від лінійних моделей, як, наприклад, у нелінійних авторегресійних екзогенних моделях. Додаткові посилання про аналіз нелінійних часових рядів: Канц і Шряйбер,[31] та Абарбанель.[32]
Серед інших типів нелінійних моделей часових рядів є моделі для представлення змін дисперсії протягом часу (гетероскедастичність). Ці моделі представляють авторегресійну умовну гетероскедастичність (англ. autoregressive conditional heteroskedasticity, ARCH), і це зібрання обіймає широку різноманіть представлень (GARCH}, TARCH, EGARCH, FIGARCH, CGARCH тощо). Тут зміни дисперсії ставляться у відповідність до, або передбачуються через нещодавні попередні значення спостережуваного ряду. Це протиставляється іншим можливим представленням локально змінної мінливості, де мінливість може моделюватися як ведена окремим змінним у часі процесом, як у бістохастичній моделі.
В нещодавній праці з безмодельного аналізу набули прихильності методи на основі вейвлетного перетворення (наприклад, локально стаціонарні вейвлети та вейвлетно-розкладені нейронні мережі). Полімасштабні (англ. multiscale, часто згадувані як поліроздільнісні, англ. multiresolution) методики розкладають заданий часовий ряд, намагаючись проілюструвати часову залежність на декількох масштабах. Див. також поліфрактальні методики з марковським перемиканням (англ. markov switching multifractal, MSMF) для моделювання процесу зміни волатильності.
Прихована марковська модель (ПММ, англ. hidden Markov model, HMM) — це статистична марковська модель, у якій модельована система розглядається як марковський процес із неспостережуваними (прихованими) станами. ПММ можна розглядати як найпростішу динамічну баєсову мережу. ПММ широко застосовуються в розпізнаванні мовлення, для перетворення часових рядів вимовлених слів на текст.
Позначення
Для аналізу часових рядів використовується ряд різних позначень. Звичне позначення, яке визначає часовий ряд X, проіндексований натуральними числами, записується як
- X = {X1, X2, …}.
Іншим поширеним позначенням є
- Y = {Yt: t ∈ T},
де T є індексною множиною.
Умови
Є два набори умов, за яких побудовано більшу частину цієї теорії:
- Стаціонарність процесу
- Ергодичність процесу
Проте, ідеї стаціонарності мусить бути розкрито для розгляду двох важливих ідей: строгої стаціонарності та стаціонарності другого порядку. Як моделі, так і застосування може бути розроблено за кожної з цих умов, хоча моделі в другому випадку можуть розглядатися як лише частково визначені.
Крім того, аналіз часових рядів може застосовуватися там, де ряди є сезонно стаціонарними або не стаціонарними. Ситуації, коли амплітуди частотних складових змінюються з часом, можуть оброблятися в частотно-часовому аналізі, що застосовує частотно-часове представлення часового ряду або сигналу.[33]
Моделі
Детальніші відомості з цієї теми ви можете знайти в статті Авторегресійна модель.
Загальним представленням авторегресійної моделі (англ. autoregressive model), добре відомої як AR(p), є

де член εt є джерелом випадковості, й називається білим шумом. Вважається, що він має наступні характеристики:
- *

- *

- *

За цих припущень процес є визначеним до моментів другого порядку, і, за умови дотримання умов на коефіцієнти, може мати стаціонарність другого порядку.
Якщо також і шум має нормальний розподіл, то він називається нормальним або ґаусовим білим шумом. В такому разі авторегресійний процес може бути строго стаціонарним, знов-таки, за умови дотримання умов на коефіцієнти.
До інструментів для дослідження даних часових рядів належать:
- Розгляд автокореляційної функції та функції спектральної густини (а також функцій взаємної кореляції та функцій взаємної спектральної густини)
- Масштабні взаємо- та автокореляційні функції для усунення внеску повільних складових[34]
- Виконання перетворення Фур'є для дослідження ряду в частотній області
- Застосування фільтру для усунення небажаного шуму
- Метод головних компонент (або метод емпіричних ортогональних функцій)
- Сингулярно-спектральний аналіз
- «Структурні» моделі:
- Загальні моделі представлення простором станів
- Моделі неспостережуваних складових
- Машинне навчання
- Прихована марковська модель
- Теоретико-черговий аналіз
- Контрольний графік
- Окремий контрольний графік Шухарта
- CUSUM-графік
- EWMA-графік
- Аналіз знетрендованих флуктуацій
- Динамічне трансформування шкали часу[35]
- Взаємна кореляція[36]
- Динамічна баєсова мережа
- Методики частотно-часового представлення:
- Швидке перетворення Фур'є
- Неперервне вейвлетне перетворення
- Віконне перетворення Фур'є
- Чірплетне перетворення
- Дробове перетворення Фур'є
- Аналіз хаосу
- Кореляційна розмірність
- Діаграми рекурентності
- Кількісний аналіз рекурентності
- Показники Ляпунова
- Ентропійне кодування
Міри
Міри або ознаки часових рядів, які можуть застосовуватися для їхнього класифікаційного або регресійного аналізу:[37]
- Одновимірні лінійні міри
- Момент (математика)
- Потужність спектрального діапазону
- Частота краю спектра
- Накопичена енергія (обробка сигналів)
- Характеристики автокореляційної функції
- Йортові параметри
- Параметри ШПФ
- Параметри авторегресійної моделі
- Критерій Манна — Кендала
- Одновимірні нелінійні міри
- Міри на основі суми кореляції
- Кореляційна розмірність
- Кореляційний інтеграл
- Кореляційна густина
- Кореляційна ентропія
- Приблизна ентропія[38]
- Ви́біркова ентропія
- Ентропія Фур'є
- Вейвлетна ентропія
- Ентропія Реньї
- Методи вищих порядків
- Відособлена передбачуваність
- Індекс динамічної подібності
- Міри несхожості простору станів
- Показник Ляпунова
- Методи перестановки
- Локальний потік
- Інші одновимірні міри
- Алгоритмічна складність
- Оцінки колмогоровської складності
- Стани прихованої марковської моделі
- Сурогатні часові ряди та сурогатне виправлення
- Втрата рекурентності (міра нестаціонарності)
- Двовимірні лінійні міри
- Максимальна лінійна взаємна кореляція
- Лінійна когерентність (обробка сигналів)
- Двовимірні нелінійні міри
- Нелінійна взаємозалежність
- Динамічне захоплення (фізика)
- Міри фазової синхронізації
- Міри фазового АПЧ
- Міри подібності:[39]
- Взаємна кореляція
- Динамічне трансформування шкали часу[35]
- Приховані марковські моделі
- Редагувальна відстань
- Повна кореляція
- Оцінка Ньюї — Уеста
- Перетворення Прейза — Уінсена
- Дані як вектори в метризованому просторі
- Дані як часові ряди з обвідними
- Глобальне стандартне відхилення
- Локальне стандартне відхилення
- Віконне стандартне відхилення
- Дані, інтерпретовані як стохастичні ряди
- Дані, інтерпретовані як функція розподілу ймовірності
- Критерій Колмогорова — Смирнова
- Критерій Крамера — фон Мізеса
Унаочнення
Часові ряди може бути унаочнювано за допомогою двох категорій графіків: накладених графіків, та відокремлених графіків. Накладені графіки відображають всі часові ряди на одному компонуванні, в той час як відокремлені графіки представляють їх на різних компонуваннях (але вирівняних з метою порівняння).[40]
Накладені графіки
Відокремлені графіки
- Обрійні графіки (англ. horizon graphs)
- Зменшені лінійні графіки (багато маленьких)
- Силуетний графік
- Круговий силуетний графік
Програмне забезпечення
Робота з даними часових рядів є відносно поширеним застосуванням для програмного забезпечення статистичного аналізу. В результаті цього, існує багато пропозицій як комерційного, так і відкритого програмного забезпечення. До деяких прикладів належать:
- Додатковий статистичний пакет CRAN для R[41]
- Аналіз та прогнозування з Weka[42]
- Передбачувальне моделювання з GMDH Shell[43]
- Функції та моделювання мовою Wolfram[44]
- Об'єкти часових рядів у MATLAB[45]
- SAS/ETS у програмному забезпеченні SAS[46]
- Expert Modeler в IBM SPSS Statistics та IBM SPSS Modeler
- Автоматичне прогнозування часових рядів з LDT[47]
- EViews, статистичний пакет для Windows, що використовується головно для орієнтованого на часові ряди економетрійного аналізу.
- bayesloop: імовірнісний програмний каркас, що полегшує об'єктивне обирання моделей для моделей параметрів, що змінюються в часі[48]
Див. також
- Аналіз знетрендованих флуктуацій
- База даних часових рядів
- Випадкове блукання
- Коригування на сезонні коливання
- Лінійна частотна модуляція
- Масштабна кореляція
- Метод Монте-Карло
- Нерівномірний часовий ряд
- Обробка сигналів
- Тренд (статистика)
- Панельне дослідження
- Показник Хьорста
- Прогнозування
- Розклад часових рядів
- Розподілене запізнювання
- Секвенувальний аналіз
- Теорія оцінювання
- Цифрова обробка сигналів
- Часові ряди аномалій
Примітки
- Zissis, Dimitrios; Xidias, Elias; Lekkas, Dimitrios (2015). Real-time vessel behavior prediction. Evolving Systems 7: 1–12. doi:10.1007/s12530-015-9133-5. (англ.)
- Imdadullah. Time Series Analysis. Basic Statistics and Data Analysis. itfeature.com. Процитовано 2 січня 2014. (англ.)
- Lin, Jessica; Keogh, Eamonn; Lonardi, Stefano; Chiu, Bill (2003). A symbolic representation of time series, with implications for streaming algorithms. Proceedings of the 8th ACM SIGMOD workshop on Research issues in data mining and knowledge discovery. New York: ACM Press. doi:10.1145/882082.882086. (англ.)
- Chris Chatfield (1996). The Analysis of Time Series, an Introduction (вид. 5-те). Chapman & Hall/CRC. с. 33. (англ.)
- Бокс, Дженкинс (1974). Анализ временных рядов прогноз и управление. (рос.)
- Якубін О. Л. Застосування «аналізу часових рядів» у сучасній політичній науці: досвід та перспективи// Трибуна. — 2009. — Березень-квітень № 3-4. — С. 19-22
- Bloomfield, P. (1976). Fourier analysis of time series: An introduction. New York: Wiley. ISBN 0471082562. (англ.)
- Shumway, R. H. (1988). Applied statistical time series analysis. Englewood Cliffs, NJ: Prentice Hall. ISBN 0130415006. (англ.)
- Sandra Lach Arlinghaus, PHB Practical Handbook of Curve Fitting. CRC Press, 1994. (англ.)
- William M. Kolb. Curve Fitting for Programmable Calculators. Syntec, Incorporated, 1984. (англ.)
- S.S. Halli, K.V. Rao. 1992. Advanced Techniques of Population Analysis. ISBN 0306439972 Page 165 (пор. … функції виконуються, якщо ми маємо від доброї до помірної допасованості до спостережених даних.) (англ.)
- The Signal and the Noise: Why So Many Predictions Fail-but Some Don't. By Nate Silver (англ.)
- Data Preparation for Data Mining: Text. By Dorian Pyle. (англ.)
- Numerical Methods in Engineering with MATLAB®. By Jaan Kiusalaas. Page 24. (англ.)
- Numerical Methods in Engineering with Python 3. By Jaan Kiusalaas. Page 21. (англ.)
- Numerical Methods of Curve Fitting. By P. G. Guest, Philip George Guest. Page 349. (англ.)
- Див. також згладжувальний оператор
- Fitting Models to Biological Data Using Linear and Nonlinear Regression. By Harvey Motulsky, Arthur Christopoulos. (англ.)
- Regression Analysis By Rudolf J. Freund, William J. Wilson, Ping Sa. Page 269. (англ.)
- Visual Informatics. Edited by Halimah Badioze Zaman, Peter Robinson, Maria Petrou, Patrick Olivier, Heiko Schröder. Page 689. (англ.)
- Numerical Methods for Nonlinear Engineering Models. By John R. Hauser. Page 227. (англ.)
- Methods of Experimental Physics: Spectroscopy, Volume 13, Part 1. By Claire Marton. Page 150. (англ.)
- Encyclopedia of Research Design, Volume 1. Edited by Neil J. Salkind. Page 266. (англ.)
- Community Analysis and Planning Techniques. By Richard E. Klosterman. Page 1. (англ.)
- An Introduction to Risk and Uncertainty in the Evaluation of Environmental Investments. DIANE Publishing. Pg 69 (англ.)
- Hamming, Richard. Numerical methods for scientists and engineers. Courier Corporation, 2012. (англ.)
- Friedman, Milton. «The interpolation of time series by related series.» Journal of the American Statistical Association 57.300 (1962): 729—757. (англ.)
- Gandhi, Sorabh, Luca Foschini, and Subhash Suri. «Space-efficient online approximation of time series data: Streams, amnesia, and out-of-order.» Data Engineering (ICDE), 2010 IEEE 26th International Conference on. IEEE, 2010. (англ.)
- Lawson, Charles L.; Hanson, Richard J. (1995). Solving Least Squares Problems. Philadelphia: Society for Industrial and Applied Mathematics. ISBN 0898713560. (англ.)
- Gershenfeld, N. (1999). The Nature of Mathematical Modeling. New York: Cambridge University Press. с. 205–208. ISBN 0521570956. (англ.)
- Kantz, Holger; Thomas, Schreiber (2004). Nonlinear Time Series Analysis. London: Cambridge University Press. ISBN 978-0521529020. (англ.)
- Abarbanel, Henry (25 листопада 1997). Analysis of Observed Chaotic Data. New York: Springer. ISBN 978-0387983721. (англ.)
- Boashash, B. (ed.), (2003) Time-Frequency Signal Analysis and Processing: A Comprehensive Reference, Elsevier Science, Oxford, 2003 ISBN 0-08-044335-4 (англ.)
- Nikolić, D.; Muresan, R. C.; Feng, W.; Singer, W. (2012). Scaled correlation analysis: a better way to compute a cross-correlogram. European Journal of Neuroscience 35 (5): 742–762. doi:10.1111/j.1460-9568.2011.07987.x. (англ.)
- Sakoe, Hiroaki; Chiba, Seibi (1978). Dynamic programming algorithm optimization for spoken word recognition. IEEE Transactions on Acoustics, Speech and Signal Processing. doi:10.1109/TASSP.1978.1163055. (англ.)
- Goutte, Cyril; Toft, Peter; Rostrup, Egill; Nielsen, Finn Å.; Hansen, Lars Kai (1999). On Clustering fMRI Time Series. NeuroImage. doi:10.1006/nimg.1998.0391. (англ.)
- Mormann, Florian; Andrzejak, Ralph G.; Elger, Christian E.; Lehnertz, Klaus (2007). Seizure prediction: the long and winding road. Brain 130 (2): 314–333. PMID 17008335. doi:10.1093/brain/awl241. (англ.)
- Land, Bruce; Elias, Damian. Measuring the ‘Complexity’ of a time series. (англ.)
- Ropella, G. E. P.; Nag, D. A.; Hunt, C. A. (2003). Similarity measures for automated comparison of in silico and in vitro experimental results. Engineering in Medicine and Biology Society 3: 2933–2936. doi:10.1109/IEMBS.2003.1280532. (англ.)
- Tominski, Christian; Aigner, Wolfgang. The TimeViz Browser:A Visual Survey of Visualization Techniques for Time-Oriented Data. Процитовано 1 червня 2014. (англ.)
- Hyndman, Rob J (22 січня 2016). CRAN Task View: Time Series Analysis.
- Time Series Analysis and Forecasting with Weka - Pentaho Data Mining - Pentaho Wiki. wiki.pentaho.com. Процитовано 7 липня 2016.
- Time Series Analysis & Forecasting Software 2016 [Free Download] (амер.). Процитовано 7 липня 2016.
- Time Series—Wolfram Language Documentation. reference.wolfram.com. Процитовано 7 липня 2016.
- Time Series Objects - MATLAB & Simulink. www.mathworks.com. Процитовано 7 липня 2016.
- Econometrics and Time Series Analysis, SAS/ETS Software. Процитовано 7 липня 2016.
- LDT. SourceForge. Процитовано 4 вересня 2016.
- bayesloop: Probabilistic programming framework that facilitates objective model selection for time-varying parameter models. Процитовано 6 грудня 2016.
Література
- Box, George; Jenkins, Gwilym (1976). Time Series Analysis: forecasting and control, rev. ed. Oakland, California: Holden-Day. (англ.)
- Бокс, Дж.; Дженкинс, Г. (1974). Анализ временных рядов: прогноз и управление. Москва: Мир. (рос.)
- Cowpertwait P.S.P., Metcalfe A.V. (2009), Introductory Time Series with R, Springer. (англ.)
- Durbin J., Koopman S.J. (2001), Time Series Analysis by State Space Methods, Oxford University Press. (англ.)
- Gershenfeld, Neil (2000). The Nature of Mathematical Modeling. Cambridge University Press. ISBN 978-0-521-57095-4. OCLC 174825352. (англ.)
- Hamilton, James (1994). Time Series Analysis. Princeton University Press. ISBN 0-691-04289-6.
- Priestley, M. B. (1981), Spectral Analysis and Time Series, Academic Press. ISBN 978-0-12-564901-8 (англ.)
- Shasha, D. (2004). High Performance Discovery in Time Series. Springer. ISBN 0-387-00857-8. (англ.)
- Shumway R. H., Stoffer (2011), Time Series Analysis and its Applications, Springer. (англ.)
- Weigend A. S., Gershenfeld N. A. (Eds.) (1994), Time Series Prediction: Forecasting the Future and Understanding the Past. Proceedings of the NATO Advanced Research Workshop on Comparative Time Series Analysis (Santa Fe, May 1992), Addison-Wesley. (англ.)
- Wiener, N. (1949), Extrapolation, Interpolation, and Smoothing of Stationary Time Series, MIT Press. (англ.)
- Woodward, W. A., Gray, H. L. & Elliott, A. C. (2012), Applied Time Series Analysis, CRC Press. (англ.)
- Якубін О. Л. Застосування «аналізу часових рядів» у сучасній політичній науці: досвід та перспективи// Трибуна. — 2009. — Березень-квітень № 3-4. — С. 19-22
Посилання
- Time series в Математичній енциклопедії (англ.)
- A First Course on Time Series Analysis — відкрита книга про аналіз часових рядів у SAS (англ.)
- Introduction to Time series Analysis (Engineering Statistics Handbook) — практичний посібник з аналізу часових рядів (англ.)
- Інструментарій MATLAB для обчислення кількох мір на базах даних часових рядів (англ.)
- Підручник Matlab зі спектрів потужності, вейвлетного аналізу та когерентності на вебсайті з багатьма іншими підручниками (англ.)
- Огляд TimeViz (англ.)
- Gaussian Processes for Machine Learning: веб-сторінка книги (англ.)
- CRAN Time Series Task View — часові ряди в R (англ.)
- TimeSeries Analysis with Pandas (англ.)