Навчання асоціативних правил
Навчання асоціативних правил — метод машинного навчання заснованого на правилах для знаходження цікавих відношень між змінними у великих базах даних. Метою є ідентифікація сильних правил, які виявляються в базах даних з використанням деяких вимірів зацікавленості.[1]
Ґрунтуючись на концепції сильних правил, Ракеш Агравал, Томаш Імієлінський та Арун Свамі[2] запровадили асоціативні правила для виявлення закономірностей між продажами продуктів, які фіксуються через торгові точки (англ. point-of-sale, POS) у супермаркетах і всі ці транзакції зберігаються у величезній базі даних. Наприклад, правило , що містяться в даних про продажі супермаркету, вказує на те, що якщо споживач купує цибулю та картоплю разом, то, ймовірно, також буде придбано олію для смаження картопельки з цибулею. Така інформація може бути використана як підґрунтя для прийняття рішень щодо маркетингової діяльності, наприклад, рекламних цін або вибору місць для розташування товарів.

Окрім вищезгаданого прикладу з аналізу ринкових кошиків, асоціативні правила застосовуються сьогодні у багатьох областях, включаючи Web mining, виявлення вторгнень, безперервне виробництво та біоінформатику. На відміну від пошуку шаблону послідовності виведення послідовності, навчання асоціативних правил, як правило, не враховує порядок елементів у межах транзакції чи транзакцій.
Визначення
| ID операції | молоко | хліб | масло | пиво | підгузники |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 | 1 |
| 4 | 1 | 1 | 1 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 | 0 |
Відповідно до визначення запропонованого Агравалем, Імієлінські, Свамі[2] задача пошуку асоціативного правила визначається так: Нехай — множина двійкових атрибутів, яка називається предмети.


Нехай — множина операцій або транзакцій, яка називається база даних.

Кожна транзакція в має унікальний номер — ID і містить підмножину предметів .


Правило визначається як імплікація форми:
, де .


Аграваль, Імієлінські та Свамі[2] визначали правило тільки між множиною і окремими предметами, для .


Кожне правило складається з двох різних множин предметів, також відомих як набори предметів та , де називається попередником (англ. antecedent) або лівостороннім, а наступний (англ. consequent) або правостороннім.


Для пояснення концепції, розглянемо приклад пов'язаний з супермаркетом. Множина предметів і в таблиці зображена невелика база даних, що містить предмети, де в кожному рядку значення 1 означає наявність елемента у відповідній транзакції, а значення 0 — відсутність елемента в цій транзакції.

Приклад правила для супермаркету може бути , а це означає, що, якщо купили масло та хліб, то також придбають молоко.

Варто зауважити, що цей приклад дуже маленький. Для застосувань на практиці, правило повинно виконуватись для декількох сотень транзакцій, перш ніж його можна буде вважати статистично значущим, а набори даних часто містять тисячі або мільйони транзакцій.
Корисні концепції
Для відбору цікавих правил з множини усіх можливих правил, накладають обмеження на різні способи вимірювання значущості та інтересу. Найбільш відомими обмеженнями є мінімальні пороги затребуваності та довіри.
Нехай буде набором предметів, — асоціативне правило і — множина транзакцій.

Більше вимірювань представлені і порівняні Таном та іншими[3], як і Гахслером.[4] Пошук методів, які можуть моделювати те, що користувач знає (і використання цих моделей як заходи цікавість), наразі активно досліджується під назвою «суб'єктивна зацікавленість» (англ. Subjective Interestingness).
Затребуваність
Затребуваність (англ. Support) вказує наскільки часто набір предметів з'являється у наборі даних.
Затребуваність відносно визначається як частка транзакцій у наборі даних, які містять підмножиною .


У наведеному вище прикладі, набір предметів має затребуваність , бо зустрічається у 20 % всіх транзакцій (1 з 5 транзакцій). Аргументом є сукупність передумов, і, таким чином, при збільшенні кількості предметів стає більш жорсткою умовою.[5]



Впевненість
Впевненість (англ. Confidence) вказує на те, як часто виконується правило.
Значення впевненості у правилі відносно множини транзакцій є часткою транзакцій, які містять , який також містить .
Впевненість визначається так:

Наприклад, правило має впевненість у базі, що означає, що для 100 % операцій, які містять масло та хліб, правило істинне (у 100 % випадків споживач, який купив масло та хліб, так само купив і молоко).

Зауважимо, що означає затребуваність об'єднання предметів з X та Y. Це може трохи заплутати, оскільки ми зазвичай думаємо про ймовірність подій, а не про набори предметів. Ми можемо переписати як імовірність , де та — це події, в яких транзакція містить набори та , відповідно.[4]




Таким чином, довіру можна інтерпретувати як оцінку умовної ймовірності , ймовірності знайти наступника у транзакції, якщо вона містить попередника.[5][6]

Ліфт
Ліфт правила визначається так:

або співвідношення спостережуваної затребуваності до очікуваного, якщо б Х та Y були незалежними.[джерело?]
Наприклад, правило має ліфт .


Якщо правило має ліфт 1, це означає, що ймовірності появи попередника та наступника є незалежними одна від одної. Коли дві події є незалежними одна від одної, то й не можна вивести правила за участю цих двох подій.
Якщо ліфт > 1, це вказує на те, наскільки ці дві ситуації залежать одна від одної, і робить ці правила потенційно корисними для прогнозування таких послідовностей у майбутніх наборах даних.
Якщо ліфт < 1, це вказує на те, що предмети замінюють один одного. Це означає, що наявність одного товару негативно впливає на наявність іншого товару, і навпаки.
Значення ліфта полягає в тому, що він враховує як впевненість, так і весь набір даних.[5]
Переконливість
Переконливість (англ. Conviction) правила визначається як .

Наприклад, правило має переконливість , що може бути інтерпретовано як відношення очікуваної частоти того, що X трапляється без Y (тобто частота того, що правило робить неправильне передбачення), якщо Х та Y незалежні, поділене на частоту спостережень невірних передбачень. У цьому прикладі значення переконливості 1.2 показує, що правило буде правильним на 20 % частіше (у 1,2 рази частіше), якби зв'язок між X та Y був чисто випадковим.

Процес
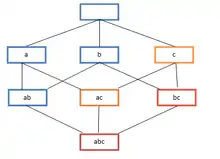

Асоціативні правила повинні відповідати мінімальній затребуваності та мінімальній впевненості, які визначаються користувачем одночасно. Утворення асоціативних правил, зазвичай, поділяється на два окремих кроки:
- Порогове значення мінімальної затребуваності використовується для знаходження всіх частот предметів у базі даних.
- Обмеження на мінімальну впевненість застосовується до частот наборів предметів для утворення правил.
Хоча другий крок є простим, перший крок потребує більшої уваги.
Пошук усіх частот наборів предметів у базі даних складний, оскільки він включає в себе пошук усіх можливих наборів, тобто усіх комбінацій предметів. Множина можливих комбінацій є булеаном та за розміром буде (за винятком порожнього набору, який не є набором предметів). Хоча кількість підмножин експоненціально зростає залежно від кількості предметів в , ефективний пошук можливий за допомогою властивості спадного змикання (англ. downward-closure) значущості[2][7] (також називається анти-монотонністю[8]), що гарантує, що для частих наборів предметів всі його підмножини також є частими, і тому не рідкісні набори предметів можуть бути підмножиною частих наборів предметів. Використовуючи цю властивість, ефективні алгоритми (наприклад, Apriori[9] та Eclat[10]) можуть знаходити всі часті набори предметів.

Статистично обгрунтовані асоціації
Одним з обмежень стандартного підходу до виявлення асоціацій є те, що, перебираючи величезну кількість можливих асоціацій для пошуку колекцій предметів, які можуть бути пов'язані, існує великий ризик виявлення багатьох фальшивих асоціацій. Це набори предметів, що збігаються випадково. Наприклад, припустимо, ми розглядаємо колекцію з 10000 предметів і шукаємо правила, що містять два предмети в лівій частині та 1 предмет у правій частині. Існує приблизно 1 000 000 000 000 таких правил. Якщо ми застосуємо статистичну перевірку для незалежності з рівнем значущості 0.05, це означає, що шанс прийняти правило, якщо немає асоціації, є лише 5%. Якщо ми вважатимемо, що немає об'єднань, ми все ж повинні розраховувати на пошук 50 000 000 000 правил. Виявлення статистично обґрунтованої асоціації[11][12] контролює цей ризик, і в більшості випадків зменшую ризик виявлення будь-яких хибних асоціацій відповідно до визначеного користувачем рівня значущості.
Примітки
- Piatetsky-Shapiro, Gregory (1991), Discovery, analysis, and presentation of strong rules, in Piatetsky-Shapiro, Gregory; and Frawley, William J.; eds., Knowledge Discovery in Databases, AAAI/MIT Press, Cambridge, MA.
- Agrawal, R.; Imieliński, T.; Swami, A. (1993). Mining association rules between sets of items in large databases. Proceedings of the 1993 ACM SIGMOD international conference on Management of data - SIGMOD '93. с. 207. ISBN 0897915925. doi:10.1145/170035.170072.
- Tan, Pang-Ning; Kumar, Vipin; and Srivastava, Jaideep; [Selecting the right objective measure for association analysis, https://cse.msu.edu/%7Eptan/papers/IS.pdf] Information Systems, 29(4):293-313, 2004
- Michael Hahsler (2015). A Probabilistic Comparison of Commonly Used Interest Measures for Association Rules. http://michael.hahsler.net/research/association_rules/measures.html
- Hahsler, Michael (2005). Introduction to arules – A computational environment for mining association rules and frequent item sets. Journal of Statistical Software.
- Hipp, J.; Güntzer, U.; Nakhaeizadeh, G. (2000). Algorithms for association rule mining --- a general survey and comparison. ACM SIGKDD Explorations Newsletter 2: 58. doi:10.1145/360402.360421.
- Tan, Pang-Ning; Michael, Steinbach; Kumar, Vipin (2005). Chapter 6. Association Analysis: Basic Concepts and Algorithms. Introduction to Data Mining. Addison-Wesley. ISBN 0-321-32136-7.
- Pei, Jian; Han, Jiawei; and Lakshmanan, Laks V. S.; Mining frequent itemsets with convertible constraints, in Proceedings of the 17th International Conference on Data Engineering, April 2–6, 2001, Heidelberg, Germany, 2001, pages 433—442
- Agrawal, Rakesh; and Srikant, Ramakrishnan; Fast algorithms for mining association rules in large databases Архівовано 25 лютого 2015 у Wayback Machine., in Bocca, Jorge B.; Jarke, Matthias; and Zaniolo, Carlo; editors, Proceedings of the 20th International Conference on Very Large Data Bases (VLDB), Santiago, Chile, September 1994, pages 487—499
- Zaki, M. J. (2000). Scalable algorithms for association mining. IEEE Transactions on Knowledge and Data Engineering 12 (3): 372–390. doi:10.1109/69.846291.
- Webb, Geoffrey I. (2007); Discovering Significant Patterns, Machine Learning 68(1), Netherlands: Springer, pp. 1-33 online access
- Gionis, Aristides; Mannila, Heikki; Mielikäinen, Taneli; and Tsaparas, Panayiotis; Assessing Data Mining Results via Swap Randomization, ACM Transactions on Knowledge Discovery from Data (TKDD), Volume 1, Issue 3 (December 2007), Article No. 14