Автокодувальник
Автокодува́льник (англ. autoencoder) — це один із типів штучних нейронних мереж, який використовують для навчання ефективних кодувань немічених даних (спонтанного навчання).[1] Це кодування перевіряється та вдосконалюється шляхом намагання відтворювати вхід із цього кодування. Автокодувальник навчається подання (кодування) для набору даних, зазвичай для зниження розмірності, шляхом тренування цієї мережі ігнорувати незначущі дані («шум»).
Існують варіанти, спрямовані на змушування навчених подань набувати корисних властивостей.[2] Прикладами є регуляризовані автокодувальники (розріджені, знешумлювальні та стягувальні, англ. Sparse, Denoising, Contractive відповідно), що є дієвими в навчанні подань для пізніших задач класифікування,[3] та варіаційні (англ. Variational) автокодувальники, із застосуванням як породжувальних моделей.[4] Автокодувальники застосовують у багатьох задачах, від розпізнавання облич[5] до оволодівання семантичним значенням слів.[6][7]
Базова архітектура
Автокодувальник має дві основні частини: кодувальник (англ. encoder), що відображує вхід до коду, та декодувальник (англ. decoder), що відображує код до відбудови входу.
Найпростішим способом виконувати задачу копіювання ідеальним чином було би просто дублювати сигнал. Натомість, автокодувальники зазвичай змушено відбудовувати вхід приблизно, залишаючи в копії лише найдоречніші аспекти даних.
Ідея автокодувальників була популярною протягом десятиріч. Перші застосування сходять до 1980-х років.[2][8][9] Їхніми найтрадиційнішими застосуваннями були знижування розмірності та навчання ознак, але цю концепцію стали застосовувати ширше, для навчання породжувальних моделей даних.[10][11] Деякі з найпотужніших ШІ у 2010-ті роки містили автокодувальники, вкладені всередині глибинних нейронних мереж.[12]
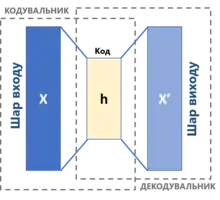
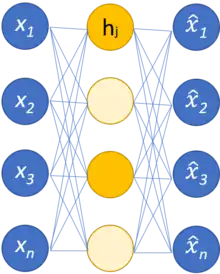
Найпростішою формою автокодувальника є нерекурентна нейронна мережа прямого поширення, подібна до одношарових перцептронів, що беруть участь у багатошарових перцептронах (БШП), з використанням шару входу та шару виходу, з'єднаних одним або декількома прихованими шарами. Шар виходу має таке саме число вузлів (нейронів), що й шар входу. Її метою є відбудовувати свої входи (мінімізуючи різницю між входом та виходом) замість передбачувати цільову змінну за заданих входів . Таким чином, автокодувальники навчаються спонтанно.


Автокодувальник складається з двох частин, кодувальника та декодувальника, які може бути визначено як переходи та , такі, що





У найпростішому випадку, якщо взяти один прихований шар, кодувальна стадія автокодувальника бере вхід та відображує його до :



Це зображення зазвичай називають кодом, латентними змінними, або латентним поданням. Тут є поелементною передавальною функцією, такою як сигмоїда або зрізаний лінійний вузол. є матрицею ваг, а є вектором зсуву. Ваги та зсуви зазвичай ініціалізують випадковим чином, а потім ітеративно уточнюють протягом тренування шляхом зворотного поширення. Після цього декодувальна стадія автокодувальника відображує у відбудову такої ж форми, що й :







де , та для декодувальника можуть бути непов'язаними з відповідними , та для кодувальника.




Автокодувальники тренують мінімізувати похибки відбудови (такі як середньоквадратичні похибки), що часто називають «втратами» (англ. «loss»):

де зазвичай усереднюють над тренувальним набором даних.
Як було зазначено вище, автокодувальне тренування виконується шляхом зворотного поширення цієї похибки, як і в інших нейронних мережах прямого поширення.
Якщо простір ознак має меншу розмірність, ніж простір входів , то вектор ознак можливо розглядати як стиснене подання входу . Це у випадку понижувальних[13] (англ. undercomplete) автокодувальників. Якщо приховані шари є більшими (підвищувальними,[14] англ. overcomplete), або такими же, як і шар входу, або якщо прихованим вузлам надано достатньої ємності, то автокодувальник потенційно може навчитися тотожної функції, й стати марним. Проте експериментальні результати виявили, що підвищувальні автокодувальники все ж можуть навчатися корисних подань.[15] В ідеальній постановці розмірність коду та ємність моделі можливо встановлювати на основі складності модельованого розподілу даних. Одним зі способів робити це є використання різновидів цієї моделі, відомих як регуляризовані автокодувальники (англ. Regularized Autoencoders).[2]




Різновиди
Регуляризовані автокодувальники
Існують різні методики запобігання навчанню автокодувальниками тотожної функції та покращення їхньої здатності вловлювати важливу інформацію та навчатися цінніших подань.
Розріджений автокодувальник (РАК)
Навчання подань у спосіб, який заохочує розрідженість, покращує продуктивність на задачах класифікування.[16] Розріджені автокодувальники (англ. Sparse autoencoders, SAE) можуть містити більше (а не менше) прихованих вузлів, аніж входів, але лише невеликому числу цих прихованих вузлів дозволено бути збудженими одночасно (власне, розрідженість).[12] Це обмеження змушує модель реагувати на унікальні статистичні ознаки тренувальних даних.
Зокрема, розріджений автокодувальник є автокодувальником, чий тренувальний критерій містить розріджувальний штраф шару коду .



Якщо пригадати, що , то цей штраф заохочує модель збуджувати (тобто, значення виходу близько 1) на основі даних входу особливі області мережі, одночасно гальмуючи всі інші нейрони (тобто, щоби вони мали значення виходу близько 0).[17]

Цієї розрідженості можливо досягати шляхом формулювання членів штрафу різними способами.
- Одним зі способів є використовувати розходження Кульбака — Лейблера (КЛ, KL).[16][17][18][19] Нехай

- буде усередненим збудженням прихованого вузла (усередненим над тренувальних зразків). Запис вказує на значення входу, що ви́кликало це збудження. Щоби заохотити більшість нейронів бути не збудженими, потрібно бути близьким до 0. Тому цей метод накладає обмеження , де є параметром розрідженості, значенням, близьким до 0. Член штрафу набуває вигляду, який штрафує за значне відхиляння від , використовуючи розходження КЛ:







- де є підсумовуванням над прихованих вузлів у прихованім шарі, а є КЛ-розходженням між випадковою змінною Бернуллі з середнім та випадковою змінною Бернуллі з середнім .[17]


- Іншим способом досягання розрідженості є застосування до збудження членів регуляризації L1 або L2, масштабованих певним параметром .[20] Наприклад, у випадку L1 функція втрат набуває вигляду


- Наступною пропонованою стратегією примушування до розрідженості є занулювати вручну всі крім найсильніших збуджень прихованих вузлів (k-розріджений автокодувальник, англ. k-sparse autoencoder).[21] k-розріджений автокодувальник ґрунтується на лінійному автокодувальнику (тобто, з лінійною передавальною функцією) та ув'язаних вагах (англ. tied weights). Визначення найсильніших збуджень можливо досягати впорядковуванням цих збуджень та залишанням лише перших k значень, або застосовуванням випрямляльних прихованих вузлів з порогами, які адаптивно підлаштовуються доти, поки не буде виявлено k найбільших збуджень. Це обирання діє як згадані раніше члени регуляризації, оскільки запобігає відбудовуванню моделлю входу із застосуванням занадто великого числа нейронів.[21]
Знешумлювальний автокодувальник (ЗАК)
Знешумлювальні автокодувальники (ЗАК, англ. denoising autoencoders, DAE) намагаються досягати доброго подання шляхом зміни критерію відбудови.[2]
Дійсно, ЗАКи беруть частково зіпсований вхід, і тренуються відновлювати первинний неспотворений вхід. На практиці метою знешумлювальних кодувальників є очищування зіпсованого входу, або знешумлювання. Цьому підходові притаманні два припущення:
- Подання вищого рівня є відносно стабільними й стійкими до псування входу;
- Щоби виконувати знешумлювання добре, моделі потрібно виділяти ознаки, які вловлюють корисну структуру в розподілі входу.[3]
Іншими словами, знешумлювання пропагується як тренувальний критерій для навчання виділяння корисних ознак, що утворюватимуть кращі подання входу вищого рівня.[3]
Процес тренування ЗАК працює наступним чином:
- Початковий вхід спотворюється в шляхом стохастичного відображення .
- Цей пошкоджений вхід відтак відображується до прихованого подання таким же процесом, як і в стандартного автокодувальника, .
- Із цього прихованого подання модель відбудовує .[3]




Параметри моделі та тренуються мінімізувати усереднену над усіма тренувальними даними похибку відбудовування, зокрема, мінімізуючи різницю між та первинним непошкодженим входом .[3] Зауважте, що кожного разу, як моделі подається випадковий зразок , на основі стохастично породжується нова пошкоджена версія.





Вищезгаданий тренувальний процес можливо застосовувати із будь-яким видом процесу пошкоджування. Деякими прикладами можуть бути адитивний ізотропний гауссів шум, маскувальний шум (випадково обрана частка входу кожного зразка примусово встановлюється в 0) або сольовий-та-перцевий шум (випадково обрана частка входу кожного зразка примусово встановлюється у своє мінімальне або максимальне значення з рівномірною ймовірністю).[3]
Пошкоджування входу виконується лише під час тренування. Після тренування пошкоджування не додається.
Стягувальний автокодувальник (САК)
Стягувальний автокодувальник (англ. contractive autoencoder, CAE) додає до своєї цільової функції явний регуляризатор, що змушує модель навчатися кодування стійко до незначних варіацій значень входу. Цей регуляризатор відповідає нормі Фробеніуса матриці Якобі збуджень кодувальника відносно входу. Оскільки цей штраф застосовується лише до тренувальних зразків, цей член змушує модель навчатися корисної інформації про тренувальний розподіл. Остаточна цільова функція має наступний вигляд:

Цей автокодувальник названо стягувальним, оскільки він заохочується відображувати окіл точок входу до меншого околу точок виходу.[2]
ЗАК є пов'язаним із САК: на границі малого гауссового шуму входу ЗАКи роблять функцію відбудови стійкою до малих, але скінченного розміру, збурень входу, тоді як САКи роблять витягнуті ознаки стійкими до нескінченно малих збурень входу.
Конкретний автокодувальник
Конкретний автокодувальник (англ. concrete autoencoder) розроблено для обирання дискретних ознак.[22] Конкретний автокодувальник примушує латентний простір складатися лише із вказаного користувачем числа ознак. Конкретний автокодувальник використовує неперервне послаблення категорійного розподілу, щоби дозволити градієнтам проходити крізь шар обирання ознак, що уможливлює застосування стандартного зворотного поширення для навчання оптимальної підмножини ознак входу, яка мінімізує втрати відбудови.
Варіаційний автокодувальник (ВАК)
Варіаційні автокодувальники (ВАКи, англ. variational autoencoders, VAEs) належать до сімейств варіаційних баєсових методів. Незважаючи на архітектурні подібності з базовими автокодувальниками, ВАКи є архітектурою з відмінними цілями та з абсолютно іншим математичним формулюванням. Латентний простір у цьому випадку складається з суміші розподілів замість фіксованого вектору.
За заданого набору даних входу , описуваного невідомою функцією ймовірності , та багатовимірного вектору латентного кодування , метою є змоделювати ці дані як розподіл , де визначено як набір таких параметрів цієї мережі, що .




Переваги глибини
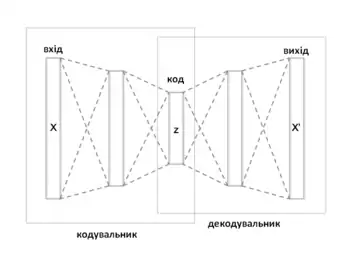
Автокодувальники часто тренують із одношаровим кодувальником та одношаровим декодувальником, але використання багатошарових (глибинних) кодувальників та декодувальників пропонує багато переваг.[2]
- Глибина може експоненційно скорочувати обчислювальну витратність подання деяких функцій.[2]
- Глибина може експоненційно зменшувати кількість тренувальних даних, потрібних для навчання деяких функцій.[2]
- Експериментально встановлено, що глибинні автокодувальники дають краще стиснення у порівнянні з поверхневими або лінійними автокодувальниками.[23]
Тренування
Для тренування багатошарових глибинних автокодувальників Джефрі Гінтон розробив методику глибинної мережі переконань. Його метод полягає в опрацюванні кожної сусідньої пари з двох шарів як обмеженої машини Больцмана, щоби попереднє тренування наближувало добрий розв'язок, і в наступнім застосуванні зворотного поширення для тонкого налаштування результатів.[23]
Дослідники дискутували, чи буде спільне тренування (тобто тренування всієї архітектури разом із єдиною глобальною метою відбудовування для оптимізування) для глибинних автокодувальників кращим.[24] Дослідження 2015 року показало, що спільне тренування навчається кращих моделей разом з показовішими ознаками для класифікування, у порівнянні з пошаровим методом.[24] Проте їхні експерименти показали, що успіх спільного тренування сильно залежить від прийнятих стратегій регуляризації.[24][25]
Застосування
Двома основними застосуваннями автокодувальників є знижування розмірності та інформаційний пошук,[2] але сучасні різновиди застосовували й до інших задач.
Знижування розмірності
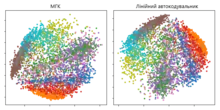
Знижування розмірності було одним із перших застосувань глибинного навчання.[2]
Гінтон для свого дослідження 2006 року[23] попередньо тренував багатошаровий автокодувальник стосом ОМБ, а потім використовував їхні ваги, щоби ініціалізувати автокодувальник із поступово меншими прихованими шарами, поки не вперся у вузьке місце з 30 нейронів. Отримані в результаті 30 вимірів коду давали меншу похибку відбудови в порівнянні з першими 30 компонентами методу головних компонент (МГК), і навчалися подання, що було якісно легшим для інтерпретування, чітко відокремлюючи кластери даних.[2][23]
Подавання вимірів може покращувати продуктивність у таких задачах як класифікування.[2] Дійсно, ознакою якості знижування розмірності є розміщування семантично пов'язаних зразків один біля одного.[27]
Метод головних компонент
Якщо застосовуються лінійні передавальні функції, або лише єдиний сигмоїдний прихований шар, то оптимальний розв'язок для автокодувальника є тісно пов'язаним із методом головних компонент (МГК).[28][29] Ваги автокодувальника з єдиним прихованим шаром розміру (де є меншим за розмір входу) охоплюють той самий векторний підпростір, що охоплюється й першими головними компонентами, а вихід автокодувальника є ортогональною проєкцією на цей підпростір. Ваги автокодувальника не дорівнюють головним компонентам, і загалом не є ортогональними, проте головні компоненти може бути відновлено з них шляхом застосування сингулярного розкладу матриці.[30]

Проте потенціал автокодувальників полягає у їхній нелінійності, що дозволяє цій моделі навчатися потужніших узагальнень порівняно з МГК та відбудовувати вхід із значно нижчими втратами інформації.[23]
Інформаційний пошук
Інформаційний пошук виграє́ зокрема завдяки зниженню розмірності, бо пошук в певних типах просторів низької вимірності можете ставати дієвішим. Автокодувальники дійсно застосовували до семантичного гешування, запропонованого Салахутдіновим та Гінтоном 2007 року.[27] Шляхом тренування цього алгоритму виробляти двійковий код низької вимірності, всі записи бази даних може бути збережено в геш-таблиці, що відображує вектори двійкового коду на записи. Ця таблиця відтак підтримуватиме інформаційний пошук, повертаючи всі записи з таким же двійковим кодом, як і в запиту, або дещо менш подібні записи шляхом перекидання деяких бітів із кодування запиту.
Виявляння аномалій
Іншим застосуванням для автокодувальників є виявляння аномалій.[31][32][33][34] Шляхом навчання відтворювати найпомітніші ознаки в тренувальних даних за деякого з описаних вище обмежень цю модель заохочують навчатися точно відтворювати найчастіше спостережувані характеристики. Стикаючись із аномаліями, модель повинна погіршувати свою відтворювальну продуктивність. В більшості випадків для тренування автокодувальника використовують лише дані з нормальними зразками, в інших частота аномалій є невеликою в порівнянні з набором спостережень, тож їхнім внеском до навченого подання можливо нехтувати. Після тренування автокодувальник точно відбудовуватиме «нормальні» дані, в той же час зазнаючи невдач у цьому з незнайомими аномальними даними.[32] Похибку відбудови (похибку між первинними даними та їхньою низьковимірною відбудовою) використовують як показник аномальності для виявляння аномалій.[32]
Проте нещодавні публікації показали, що певні автокодувальні моделі можуть, як не дивно, бути дуже вправними у відбудовуванні аномальних зразків, і відтак бути нездатними надійно виконувати виявляння аномалій.[35][36]
Обробка зображень
Характеристики автокодувальників є корисними в обробці зображень.
Один із прикладів можливо знайти у стисканні зображень із втратами, де автокодувальники перевершували інші підходи, й довели конкурентноспроможність у порівнянні з JPEG 2000.[37][38]
Іншим корисним застосуванням автокодувальників у попередній обробці зображень є знешумлювання зображень.[39][40][41]
Автокодувальники знайшли застосування у вимогливіших контекстах, таких як медична візуалізація, де їх використовували як для знешумлювання зображень,[42] так і для надвисокої роздільної здатністі.[43][44] У діагностиці за допомогою зображень, в експериментах застосовували автокодувальники для виявляння раку молочної залози[45] та для моделювання зв'язку між когнітивним спадом хвороби Альцгеймера та латентними ознаками автокодувальника, натренованого за допомогою МРТ.[46]
Пошук ліків
2019 року молекули, породжені варіаційними автокодувальниками, було перевірено експериментально на мишах.[47][48]
Передбачування популярності
Нещодавно система складених автокодувальників (англ. stacked autoencoder) продемонструвала обнадійливі результати в передбачуванні популярності публікацій у соціальних мережах,[49] що є корисним для стратегій реклами через Інтернет.
Машинний переклад
Автокодувальник застосовують для машинного перекладу, що зазвичай називають нейронним машинним перекладом(НМП).[50][51] На відміну від стандартних автокодувальників, вихід не збігається із входом — його мова є іншою. В НМП тексти розглядають як послідовності для кодування в процедурі навчання, тоді як на декодувальому боці породжуються послідовності цільовою мовою. Мовно-специфічні автокодувальники включають до навчальної процедури додаткові мовознавчі ознаки, такі як ознаки розкладу китайської мовм.[52]
Див. також
- Навчання подань
- Навчання розрідженого словника
- Глибинне навчання
Примітки
- Kramer, Mark A. (1991). Nonlinear principal component analysis using autoassociative neural networks. AIChE Journal 37 (2): 233–243. doi:10.1002/aic.690370209. (англ.)
- Goodfellow, Ian; Bengio, Yoshua; Courville, Aaron (2016). Deep Learning. MIT Press. ISBN 978-0262035613. (англ.)
- Vincent, Pascal; Larochelle, Hugo (2010). Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. Journal of Machine Learning Research 11: 3371–3408. (англ.)
- Welling, Max; Kingma, Diederik P. (2019). An Introduction to Variational Autoencoders. Foundations and Trends in Machine Learning 12 (4): 307–392. Bibcode:2019arXiv190602691K. arXiv:1906.02691. doi:10.1561/2200000056. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Hinton GE, Krizhevsky A, Wang SD. Transforming auto-encoders. In International Conference on Artificial Neural Networks 2011 Jun 14 (pp. 44-51). Springer, Berlin, Heidelberg. (англ.)
- Liou, Cheng-Yuan; Huang, Jau-Chi; Yang, Wen-Chie (2008). Modeling word perception using the Elman network. Neurocomputing 71 (16–18): 3150. doi:10.1016/j.neucom.2008.04.030. (англ.)
- Liou, Cheng-Yuan; Cheng, Wei-Chen; Liou, Jiun-Wei; Liou, Daw-Ran (2014). Autoencoder for words. Neurocomputing 139: 84–96. doi:10.1016/j.neucom.2013.09.055. (англ.)
- Schmidhuber, Jürgen (January 2015). Deep learning in neural networks: An overview. Neural Networks 61: 85–117. PMID 25462637. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Hinton, G. E., & Zemel, R. S. (1994). Autoencoders, minimum description length and Helmholtz free energy. In Advances in neural information processing systems 6 (pp. 3-10). (англ.)
- Diederik P Kingma; Welling, Max (2013). «Auto-Encoding Variational Bayes». arXiv:1312.6114 [stat.ML]. (англ.)
- Generating Faces with Torch, Boesen A., Larsen L. and Sonderby S.K., 2015 torch.ch/blog/2015/11/13/gan.html (англ.)
- Domingos, Pedro (2015). 4. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World. Basic Books. "Deeper into the Brain" subsection. ISBN 978-046506192-1. Проігноровано невідомий параметр
|title-link=(довідка) (англ.) - Кривохата, А. Г. (2020). Нейромережеві математичні моделі звукових сигналів у задачах розпізнавання (кандидатська дисертація). Запоріжжя: ЗНУ. с. 64. Процитовано 18 червня 2021.
- Андросов, Д. В. (2020). Система відновлення динаміки часового ряду методом штучних нейромереж (бакалаврська дипломна робота). Київ: НТУУ КПІ. с. 24. Процитовано 18 червня 2021.
- Bengio, Y. (2009). Learning Deep Architectures for AI. Foundations and Trends in Machine Learning 2 (8): 1795–7. PMID 23946944. doi:10.1561/2200000006. Проігноровано невідомий параметр
|citeseerx=(довідка) (англ.) - Frey, Brendan; Makhzani, Alireza (19 грудня 2013). k-Sparse Autoencoders. Bibcode:2013arXiv1312.5663M. arXiv:1312.5663. (англ.)
- Ng, A. (2011). Sparse autoencoder. CS294A Lecture notes, 72(2011), 1-19. (англ.)
- Nair, Vinod; Hinton, Geoffrey E. (2009). 3D Object Recognition with Deep Belief Nets. Proceedings of the 22Nd International Conference on Neural Information Processing Systems. NIPS'09 (USA: Curran Associates Inc.): 1339–1347. ISBN 9781615679119. (англ.)
- Zeng, Nianyin; Zhang, Hong; Song, Baoye; Liu, Weibo; Li, Yurong; Dobaie, Abdullah M. (17 січня 2018). Facial expression recognition via learning deep sparse autoencoders. Neurocomputing 273: 643–649. ISSN 0925-2312. doi:10.1016/j.neucom.2017.08.043. (англ.)
- Arpit, Devansh; Zhou, Yingbo; Ngo, Hung; Govindaraju, Venu (2015). «Why Regularized Auto-Encoders learn Sparse Representation?». arXiv:1505.05561 [stat.ML]. (англ.)
- Makhzani, Alireza; Frey, Brendan (2013). «K-Sparse Autoencoders». arXiv:1312.5663 [cs.LG]. (англ.)
- Abid, Abubakar; Balin, Muhammad Fatih; Zou, James (2019-01-27). «Concrete Autoencoders for Differentiable Feature Selection and Reconstruction». arXiv:1901.09346 [cs.LG]. (англ.)
- Hinton, G. E.; Salakhutdinov, R.R. (28 липня 2006). Reducing the Dimensionality of Data with Neural Networks. Science 313 (5786): 504–507. Bibcode:2006Sci...313..504H. PMID 16873662. doi:10.1126/science.1127647. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Zhou, Yingbo; Arpit, Devansh; Nwogu, Ifeoma; Govindaraju, Venu (2014). «Is Joint Training Better for Deep Auto-Encoders?». arXiv:1405.1380 [stat.ML]. (англ.)
- R. Salakhutdinov and G. E. Hinton, “Deep boltzmann machines,” in AISTATS, 2009, pp. 448–455. (англ.)
- Fashion MNIST. 12 липня 2019.
- Salakhutdinov, Ruslan; Hinton, Geoffrey (1 липня 2009). Semantic hashing. International Journal of Approximate Reasoning. Special Section on Graphical Models and Information Retrieval 50 (7): 969–978. ISSN 0888-613X. doi:10.1016/j.ijar.2008.11.006. Проігноровано невідомий параметр
|doi-access=(довідка) (англ.) - Bourlard, H.; Kamp, Y. (1988). Auto-association by multilayer perceptrons and singular value decomposition. Biological Cybernetics 59 (4–5): 291–294. PMID 3196773. doi:10.1007/BF00332918. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Chicco, Davide; Sadowski, Peter; Baldi, Pierre (2014). Deep autoencoder neural networks for gene ontology annotation predictions. Proceedings of the 5th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics - BCB '14. с. 533. ISBN 9781450328944. doi:10.1145/2649387.2649442. Проігноровано невідомий параметр
|s2cid=(довідка); Проігноровано невідомий параметр|hdl=(довідка) (англ.) - Plaut, E (2018). «From Principal Subspaces to Principal Components with Linear Autoencoders». arXiv:1804.10253 [stat.ML]. (англ.)
- Sakurada, M., & Yairi, T. (2014, December). Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis (p. 4). ACM. (англ.)
- An, J., & Cho, S. (2015). Variational autoencoder based anomaly detection using reconstruction probability. Special Lecture on IE, 2, 1-18. (англ.)
- Zhou, C., & Paffenroth, R. C. (2017, August). Anomaly detection with robust deep autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 665-674). ACM. (англ.)
- Ribeiro, Manassés; Lazzaretti, André Eugênio; Lopes, Heitor Silvério (2018). A study of deep convolutional auto-encoders for anomaly detection in videos. Pattern Recognition Letters 105: 13–22. doi:10.1016/j.patrec.2017.07.016. (англ.)
- Nalisnick, Eric; Matsukawa, Akihiro; Teh, Yee Whye; Gorur, Dilan; Lakshminarayanan, Balaji (2019-02-24). «Do Deep Generative Models Know What They Don't Know?». arXiv:1810.09136 [stat.ML]. (англ.)
- Xiao, Zhisheng; Yan, Qing; Amit, Yali (2020). Likelihood Regret: An Out-of-Distribution Detection Score For Variational Auto-encoder. Advances in Neural Information Processing Systems (англ.) 33. arXiv:2003.02977. (англ.)
- Theis, Lucas; Shi, Wenzhe; Cunningham, Andrew; Huszár, Ferenc (2017). «Lossy Image Compression with Compressive Autoencoders». arXiv:1703.00395 [stat.ML]. (англ.)
- Balle, J; Laparra, V; Simoncelli, EP (April 2017). End-to-end optimized image compression. International Conference on Learning Representations. arXiv:1611.01704. (англ.)
- Cho, K. (2013, February). Simple sparsification improves sparse denoising autoencoders in denoising highly corrupted images. In International Conference on Machine Learning (pp. 432-440). (англ.)
- Cho, Kyunghyun (2013). «Boltzmann Machines and Denoising Autoencoders for Image Denoising». arXiv:1301.3468 [stat.ML]. (англ.)
- Buades, A.; Coll, B.; Morel, J. M. (2005). A Review of Image Denoising Algorithms, with a New One. Multiscale Modeling & Simulation 4 (2): 490–530. doi:10.1137/040616024. (англ.)
- Gondara, Lovedeep (December 2016). Medical Image Denoising Using Convolutional Denoising Autoencoders. 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW) (Barcelona, Spain: IEEE): 241–246. Bibcode:2016arXiv160804667G. ISBN 9781509059102. arXiv:1608.04667. doi:10.1109/ICDMW.2016.0041. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Zeng, Kun; Yu, Jun; Wang, Ruxin; Li, Cuihua; Tao, Dacheng (January 2017). Coupled Deep Autoencoder for Single Image Super-Resolution. IEEE Transactions on Cybernetics 47 (1): 27–37. ISSN 2168-2267. PMID 26625442. doi:10.1109/TCYB.2015.2501373. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Tzu-Hsi, Song; Sanchez, Victor; Hesham, EIDaly; Nasir M., Rajpoot (2017). Hybrid deep autoencoder with Curvature Gaussian for detection of various types of cells in bone marrow trephine biopsy images. 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017): 1040–1043. ISBN 978-1-5090-1172-8. doi:10.1109/ISBI.2017.7950694. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Xu, Jun; Xiang, Lei; Liu, Qingshan; Gilmore, Hannah; Wu, Jianzhong; Tang, Jinghai; Madabhushi, Anant (January 2016). Stacked Sparse Autoencoder (SSAE) for Nuclei Detection on Breast Cancer Histopathology Images. IEEE Transactions on Medical Imaging 35 (1): 119–130. PMC 4729702. PMID 26208307. doi:10.1109/TMI.2015.2458702. (англ.)
- Martinez-Murcia, Francisco J.; Ortiz, Andres; Gorriz, Juan M.; Ramirez, Javier; Castillo-Barnes, Diego (2020). Studying the Manifold Structure of Alzheimer's Disease: A Deep Learning Approach Using Convolutional Autoencoders. IEEE Journal of Biomedical and Health Informatics 24 (1): 17–26. PMID 31217131. doi:10.1109/JBHI.2019.2914970. Проігноровано невідомий параметр
|s2cid=(довідка); Проігноровано невідомий параметр|doi-access=(довідка) (англ.) - Zhavoronkov, Alex (2019). Deep learning enables rapid identification of potent DDR1 kinase inhibitors. Nature Biotechnology 37 (9): 1038–1040. PMID 31477924. doi:10.1038/s41587-019-0224-x. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Gregory, Barber. A Molecule Designed By AI Exhibits 'Druglike' Qualities. Wired. (англ.)
- De, Shaunak; Maity, Abhishek; Goel, Vritti; Shitole, Sanjay; Bhattacharya, Avik (2017). Predicting the popularity of instagram posts for a lifestyle magazine using deep learning. 2017 2nd IEEE International Conference on Communication Systems, Computing and IT Applications (CSCITA). с. 174–177. ISBN 978-1-5090-4381-1. doi:10.1109/CSCITA.2017.8066548. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Cho, Kyunghyun; Bart van Merrienboer; Bahdanau, Dzmitry; Bengio, Yoshua (2014). «On the Properties of Neural Machine Translation: Encoder-Decoder Approaches». arXiv:1409.1259 [cs.CL]. (англ.)
- Sutskever, Ilya; Vinyals, Oriol; Le, Quoc V. (2014). «Sequence to Sequence Learning with Neural Networks». arXiv:1409.3215 [cs.CL]. (англ.)
- Han, Lifeng; Kuang, Shaohui (2018). «Incorporating Chinese Radicals into Neural Machine Translation: Deeper Than Character Level». arXiv:1805.01565 [cs.CL]. (англ.)
Посилання
- Типи автокодувальників (англ.)