Ієрархічна кластеризація
Ієрархічна кластеризація (англ. hierarchical cluster analysis, HCA) в добуванні даних та статистиці — метод кластерного аналізу, який намагається побудувати ієрархію кластерів. Стратегії побудови ієрархічної кластеризації діляться на два типи:[1]
- агломератові (об'єднувальні). Це підхід «знизу-вгору». Спочатку кожна точка має власний кластер, а далі пари кластерів об'єднуються при підйомі по ієрархії.
- розділювальні. Це підхід «згори-вниз». Спочатку всі точки знаходяться у єдиному кластері, потім відбувається рекурсивне розбиття при русі вниз по ієрархії.
Зазвичай розбиття та об'єднання визначаються у жадібний спосіб. Отриману ієрархію типово зображають як дендрограму.
Стандартний алгоритм ієрархічної кластеризації має часову складність та потребує пам'яті, що занадто повільно навіть для наборів даних середнього розміру. Однак, для деяких випадків, є агломератові методи, які виконуються за час . Це методи SLINK[2][3] при однозв'язній та CLINK[4][3] при повнозв'язній кластеризації. Використання купи дозволяє у загальному випадку скоротити час виконання до ціною збільшення вимог до об'єму пам'яті. Такі накладні витрати на пам'ять, для багатьох мов програмування, роблять цей підхід неможливим для реалізації.



Окрім спеціального однозв'язного випадку немає алгоритмів (окрім повного перебору за час ), який би гарантував оптимальний розв'язок.

Розділювальна кластеризація з повним перебором виконується за час , проте звичайною практикою є використання більш швидких евристик для розбиття, такі як k-середні.
Дендрограма
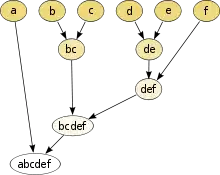
Під дендрограмою зазвичай розуміється дерево, тобто граф без циклів побудований за матриці заходів близькості. Дендрограма дозволяє зобразити взаємні зв'язки між об'єктами з заданого переліку[5]. Для створення дендрограми потрібно матриця подібності (чи відмінності), яка визначає рівень спорідненості між парами об'єктів. Частіше використовуються агломеративні методи.
Далі необхідно вибрати метод побудови дендрограми, який визначає метод візуалізації матриці подібності (чи відмінності) після об'єднання (або поділу) чергових двох об'єктів в кластер.
У роботах по кластерному аналізу описаний досить значний ряд способів побудови (англ. sorting strategies) дендрограмм[6]:
- Метод одиночного зв'язку (англ. single linkage). Також відомий як «метод найближчого сусіда».
- Метод повного зв'язку (англ. complete linkage). Також відомий як «метод далекого сусіда».
- Метод середнього зв'язку (англ. pair-group method using arithmetic averages).
- Центроїдний метод (англ. pair-group method using the centroid average).
- Незважений.
- Зважений (медіанний).
- Метод Уорда (англ. Ward's method).
Для перших трьох методів існує загальна формула, запропонована А. Н. Колмогоровим для заходів подібності[7]:

де — група з двох об'єктів (кластерів) і ; — об'єкт (кластер), з яким шукається схожість зазначеної групи; — кількість елементів у кластері ; — кількість елементів у кластері . Для відстаней є аналогічна формула Ланса — Вільямса[8].






Центроїдний метод використовує для перерахунку матриці відстаней[9]. Як відстані між двома кластерами у цьому методі береться відстань між центрами тяжіння.
У методі Уорда як відстані між кластерами береться приріст суми квадратів відстаней об'єктів до центрів кластерів, що отримується в результаті їх об'єднання[10]. На відміну від інших методів кластерного аналізу для оцінки відстаней між кластерами, тут використовуються методи дисперсійного аналізу. На кожному кроці алгоритму об'єднуються такі два кластери, які призводять до мінімального збільшення цільової функції, тобто внутрішньогрупової суми квадратів. Цей метод спрямований на об'єднання близько розташованих кластерів.
Кореляційні плеяди
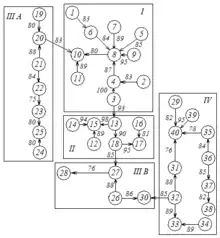
Широко застосовуються в геоботаніці та флористиці. Їх часто називають «кореляційними плеядами»[11][12][13][14].
Окремим випадком є метод, відомий як метод побудови «оптимальних дерев (дендритів)», який був запропонований математиком львівської школи Гуго Штейнгаузом[15], згодом метод був розвинений математиками вроцлавської таксономічної школи[16]. Дендрити також не повинні утворювати циклів. Можна частково використовувати спрямовані дуги графів при використанні додатково заходів включення (несиметричних заходів подібності).
Діаграма Чекановського
Метод «діагоналізації» матриці відмінності і графічне зображення кластерів уздовж головної діагоналі матриці відмінності (діаграма Чекановського) вперше запропонований Яном Чекановським у 1909 році[17]. Наведемо опис методики:
Суть цього методу полягає в тому, що всю амплітуду отриманих величин подібності розбивають на ряд класів, а потім в матриці величин подібності замінюють ці величини штрихуванням, різної для кожного класу, причому зазвичай для більш високих класів подібності застосовують темніше штрихування. Потім, змінюючи порядок описів в таблиці, домагаються того, щоб подібні описи були розташовані поруч[18]
Наведемо гіпотетичний приклад отримання такої діаграми. Основою методу є побудова матриці транзитивного замикання[19].
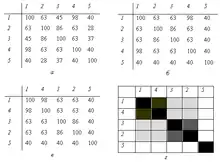
Для побудови матриці транзитивного замикання візьмемо просту матрицю подібності і помножимо її на саму себе:

де — елемент, що стоїть на перетині -го рядка -го стовпця в новій (другій) матриці, отриманій після першої ітерації; — загальна кількість рядків (стовпчиків) матриці подібності. Дану процедуру необхідно продовжувати поки матриця не стане ідемпотентною (тобто самоподібною): , де — кількість ітерацій.





Далі перетворюємо матрицю таким чином, щоб близькі числові значення знаходилися поряд. Якщо кожному числовому значенню поставити у відповідність будь-який колір або відтінок кольору (як у нашому випадку), то отримаємо класичну діаграму Чекановського. Традиційно темніший колір відповідає більшій подібності, а світліший — меншій. В цьому вона схожа з теплокартою матриці відстаней.
Примітки
- Rokach, Lior, and Oded Maimon. «Clustering methods.» Data mining and knowledge discovery handbook. Springer US, 2005. 321—352.
- R. Sibson (1973). SLINK: an optimally efficient algorithm for the single-link cluster method. The Computer Journal (British Computer Society) 16 (1): 30–34. doi:10.1093/comjnl/16.1.30.
- Schütze, Hinrich; Christopher D. Manning; Raghavan, Prabhakar (2008). Introduction to information retrieval. Cambridge, UK: Cambridge University Press. с. 382–385. ISBN 0-521-86571-9.
- D. Defays (1977). An efficient algorithm for a complete-link method. The Computer Journal (British Computer Society) 20 (4): 364–366. doi:10.1093/comjnl/20.4.364.
- «Жамбю М.» Ієрархічний кластер-аналіз та відповідності. — М.: Финансы и статистика, 1988. — 345 с.
- Классификация и кластер. Под ред. Дж. Вэн Райзина. М.: Мир, 1980. 390 с.
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: Классификация и снижение размерности. — М.: Финансы и статистика, 1989. — 607 с.
- «Lance G.N., Willams W.T.» A general theory classification of sorting strategies. 1. Hierarchical systems // Comp. J. 1967. № 9. P. 373—380.
- «Sneath P.H.A., Sokal R.R.» Numerical taxonomy: The principles and practices of numerical classification. — San-Francisco: Freeman, 1973. — 573 p.
- «Ward J.H.» Hierarchical grouping to optimize an objective function // J. of the American Statistical Association, 1963. — 236 р.
- «von Terentjev P.V.» Biometrische Untersuchungen über die morphologischen Merkmale von Rana ridibunda Pall. (Amphibia, Salientia) // Biometrika. 1931. № 23(1-2). P. 23-51.
- «Терентьєв П. У.» Метод кореляційних плеяд // Вісн. ЛДУ. № 9. 1959. С. 35-43.
- «Терентьєв П. У.» Подальший розвиток методу кореляційних плеяд // Застосування математичних методів в біології. Т. 1. Л.: 1960. С. 42-58.
- «Выханду Л. К.» Про дослідженні многопризнаковых біологічних систем // Застосування математичних методів в біології. Л.: вып. 3. 1964. С. 19-22.
- «Штейнгауз Р.» Математичний калейдоскоп. — М.: Наука, 1981. — 160 с.
- «Florek K., Lukaszewicz S., Percal S., Steinhaus H., Zubrzycki S.» Taksonomia Wroclawska // Przegl. antropol. 1951. T. 17. S. 193—211.
- «Czekanowski J.» Zur differential Diagnose der Neandertalgruppe // Korrespbl. Dtsch. Ges. Anthropol. 1909. Bd 40. S. 44-47.
- Василевич В. И. Статистические методы в геоботанике. — Л.: Наука, 1969. — 232 с.
- «Tamura S., Hiquchi S., Tanaka K.» Pattern classification based on fuzzy relation // IEEE transaction on systems, man, and cybernetics, 1971, SMC 1, № 1, P. 61-67.
