Прихована марковська модель
Прихо́вана ма́рковська моде́ль, ПММ (англ. hidden Markov model, HMM) — це статистична марковська модель, у якій система, що моделюється, розглядається як марковський процес із неспостережуваними (прихованими) станами. ПММ може бути представлено як найпростішу динамічну баєсову мережу. Математичний апарат для ПММ було розроблено Леонардом Баумом зі співробітниками.[1][2][3][4][5] Він тісно пов'язаний з більш ранньою працею про оптимальну нелінійну проблему фільтрування Руслана Стратоновича,[6] який першим описав послідовно-зворотній алгоритм.
У простіших марковських моделях (таких як ланцюги Маркова) стан є безпосередньо видимим спостерігачеві, і тому ймовірності переходу станів є єдиними параметрами. У прихованій марковській моделі стан не є видимим безпосередньо, але вихід, залежний від стану, видимим є. Кожен стан має ймовірнісний розподіл усіх можливих вихідних значень. Отже, послідовність символів, згенерована ПММ, дає якусь інформацію про послідовність станів. Прикметник «прихований» стосується послідовності станів, якою проходить модель, а не параметрів моделі; модель все одно називають «прихованою» марковською моделлю, навіть якщо ці параметри відомі точно.
Приховані марковські моделі відомі в першу чергу завдяки їхньому застосуванню в розпізнаванні часових шаблонів, таких як розпізнавання мовлення, рукописного введення, жестів,[7] морфологічної розмітки, мелодій для акомпонуваня,[8] часткових розрядів[9] та в біоінформатиці.
Приховані марковські моделі можуть розглядатися як узагальнення сумішевої моделі, де приховані (або латентні) змінні, що контролюють, яка складова суміші обиратиметься для кожного спостереження, пов'язані марковським процесом, а не є незалежними одна від одної. Нещодавно приховані марковські моделі було узагальнено до подвійних марковських моделей (англ. pairwise Markov models) та триплетних марковських моделей (англ. triplet Markov models), що дозволяє розглядати складніші структури даних[10][11] та моделювати нестаціонарні дані.[12][13]
Опис у термінах урн
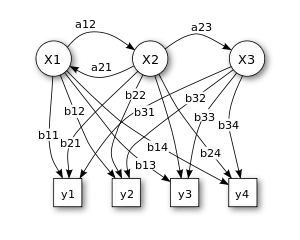
X — стани
y — можливі спостереження
a — ймовірності переходів станів
b — ймовірності виходів
У своїй дискретній формі прихований марковський процес може бути представлено як узагальнення задачі про урни із поверненням (де кожен елемент з урни перед наступним кроком повертається до своєї урни).[14] Розгляньмо цей приклад. У невидимій для спостерігача кімнаті знаходиться джин. Кімната містить урни X1, X2, X3, … кожна з яких містить відому суміш куль, кожну кулю позначено як y1, y2, y3, … . Джин обирає урну в цій кімнаті, та витягує випадкову кулю з цієї урни. Потім він кладе цю кулю на конвеєрну стрічку, на якій спостерігач може бачити послідовність куль, але не послідовність урн, з яких їх було витягнуто. Джин має певну процедуру для обирання урн; вибір урни для n-тої кулі залежить лише від випадкового числа та вибору урни для (n − 1)-ї кулі. Вибір урни не залежить безпосередньо від урн, обраних перед цією однією попередньою урною; отже, це називається марковським процесом. Його може бути зображено верхньою частиною малюнку 1.
Самого марковського процесу не видно, лише послідовність позначених куль, тому цей механізм називатися «прихованим марковським процесом». Це проілюстровано нижньою частиною діаграми, зображеної на малюнку 1, де можна бачити, що кулі y1, y2, y3, y4 може бути витягнуто у кожному стані. Навіть якщо спостерігач знає вміст урн, і щойно побачив на конвеєрній стрічці послідовність трьох куль, наприклад, y1, y2 та y3, він все ще не може бути впевненим з якої урни (тобто, в якому стані) джин витягнув третю кулю. Однак, спостерігач може опрацювати іншу інформацію, таку як ймовірність того, що третю кулю було витягнуто з кожної з урн.
Архітектура
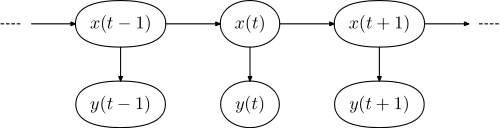
Діаграма нижче показує загальну архітектуру прикладу ПММ. Кожен овал представляє випадкову змінну, що може приймати будь-яке число значень. Випадкова змінна x(t) є прихованим станом у момент часу t (у моделі з діаграми вище x(t) ∈ { x1, x2, x3 }). Випадкова змінна y(t) є спостереженням у момент часу t (де y(t) ∈ { y1, y2, y3, y4 }). Стрілки у цій діаграмі (що часто називають ґратковою діаграмою) позначають ймовірнісні залежності.
З цієї діаграми видно, що умовний розподіл прихованої змінної x(t) у момент часу t, якщо дано значення прихованої змінної x в усі моменти часу, залежить лише від значення прихованої змінної x(t − 1): значення у момент часу t − 2 та раніші не мають впливу. Це називається марковською властивістю. Так само, значення спостережуваної змінної y(t) залежить лише від значення прихованої змінної x(t) (у той же момент часу t).
У стандартному типі прихованої марковської моделі, що тут розглядається, простір станів прихованих змінних є дискретним, тоді як самі спостереження можуть бути або дискретними (що зазвичай генеруються з категорійного розподілу) або неперервними (зазвичай з нормального розподілу). Параметри прихованої марковської моделі належать до двох типів, ймовірності переходів та ймовірності виходів. Ймовірності переходів керують тим, яким чином прихований стан у момент часу t обирається на підставі прихованого стану в момент часу .

Вважається, що простір прихованих станів складається з одного з N можливих значень, змодельований як категорійний розподіл. (Див. розділ нижче про розширення для інших можливостей.) Це означає, що для кожного з N можливих станів, у якому прихована змінна може бути в момент часу t, є ймовірність переходу з цього стану до кожного з N можливих станів прихованої змінної в момент часу , загалом ймовірностей переходів. Зауважте, що набір ймовірностей переходів для переходів з будь-якого заданого стану мусить в сумі дорівнювати 1. Отже, матриця ймовірностей переходів є марковською матрицею. Оскільки будь-яку одну ймовірність переходу може бути визначено, коли відомо решту, загальна кількість параметрів переходу складає .




До того ж, для кожного з N можливих станів є набір ймовірностей виходів, що керує розподілом спостережуваної змінної у певний момент часу для заданого стану прихованої змінної в цей момент часу. Розмір цього набору залежить від природи спостережуваної змінної. Наприклад, якщо спостережувана змінна є дискретною з M можливих значень, що регулюються категорійним розподілом, то буде окремих параметрів, загальним числом параметрів виходу для всіх прихованих станів. З іншого боку, якщо спостережувана змінна є M-мірним вектором з розподілом відповідно до довільного багатовимірного нормального розподілу, то буде M параметрів, що контролюють середні, та параметрів, що контролюють коваріаційну матрицю, загальним числом параметрів виходу. (В такому випадку, якщо значення M не є малим, може бути зручніше обмежити природу коваріацій між індивідуальними елементами вектора спостережень, наприклад, припустивши, що елементи не залежать один від одного, або, менш обмежуюче, не залежать від всіх, крім фіксованого числа сусідніх елементів.)




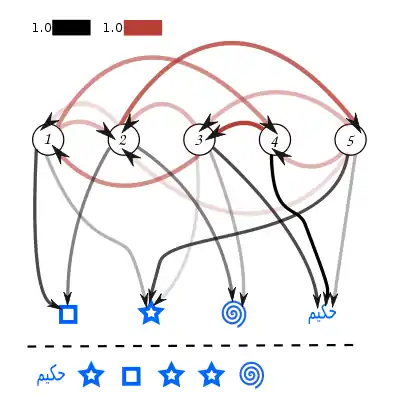
Висновування
5 3 2 5 3 2
4 3 2 5 3 2
3 1 2 5 3 2
Ми можемо знайти найбільш правдоподібну послідовність, обчисливши спільну ймовірність послідовностей станів та спостережень для кожного випадку (просто перемноживши значення ймовірностей, що відповідають непрозорості задіяних стрілок). Загалом, цей тип задач (тобто, знаходження найбільш правдоподібного пояснення спостережуваної послідовності) може ефективно розв'язуватися алгоритмом Вітербі.
З прихованими марковськими моделями пов'язані деякі задачі висновування, як окреслено нижче.
Ймовірність спостережуваної послідовності
Задача полягає в обчисленні найкращим чином, при заданих параметрах моделі, ймовірності певної вихідної послідовності. Це вимагає сумування за всіма можливими послідовностями станів:
Ймовірність спостереження послідовності

довжиною L задається формулою

де сума пробігає усіма можливими послідовностями прихованих вузлів

При застосуванні принципу динамічного програмування ця задача також може розв'язуватися ефективно з використанням послідовного алгоритму.
Імовірність латентних змінних
Ряд пов'язаних задач про ймовірність однієї або більше латентних змінних при заданих параметрах моделі та послідовності спостережень

Фільтрування
Задача полягає в обчисленні, при заданих параметрах моделі та послідовності спостережень, розподілу над прихованими станами останньої латентної змінної в кінці послідовності, тобто в обчисленні . Ця задача зазвичай застосовується, коли послідовність латентних змінних розглядається як базові стані, якими проходить процес у послідовності моментів часу, із відповідними спостереженнями у кожен момент часу. Тоді природно спитати про стан процесу в кінці.

Ця задача може ефективно розв'язуватися із застосуванням послідовного алгоритму.
Згладжування
Ця задача схожа на фільтрування, але в ній питається про розподіл латентної змінної десь у середині послідовності, тобто, потрібно обчислити для деякого . З огляду на описане вище, це може розглядатися як розподіл ймовірностей над прихованими станами для моменту часу k у минулому, по відношенню до часу t.


Ефективним методом обчислення згладжених значень для всіх змінних прихованого стану є послідовно-зворотній алгоритм.
Найбільш правдоподібне пояснення
У цій задачі, на відміну від двох попередніх, питається про спільну ймовірність всієї послідовності прихованих станів, що згенерувала певну послідовність спостережень (див. ілюстрацію праворуч). Ця задача, як правило, можна застосовувати тоді, коли ПММ застосовується до різних типів проблем з тих, для яких застосовуються задачі фільтрування та згладжування. Прикладом є морфологічна розмітка, де приховані стани представляють гадані частини мови, що відповідають спостережуваній послідовності слів. У цьому випадку інтерес становить повна послідовність частин мови, а не просто частина мови для одного слова, що її обчислювали би фільтрування чи згладжування.
Задача вимагає знаходження максимуму над усіма можливими послідовностями станів, і може ефективно розв'язуватися алгоритмом Вітербі.
Статистична значущість
Для деяких із наведених вище задач може бути цікаво спитати про статистичну значущість. Якою є ймовірність того, що послідовність, витягнута з якогось нульового розподілу, матиме ПММ-ймовірність (у випадку послідовного алгоритму) або максимальну ймовірність послідовності станів (у випадку алгоритму Вітербі), не меншу за таку ймовірність певної послідовності?[15] Коли ПММ використовується для оцінювання доречності гіпотези для певної послідовності виходу, статистична значимість показує рівень похибки першого роду, пов'язаною зі слабкістю можливості спростування цієї гіпотези для цієї послідовності виходу.
Конкретний приклад
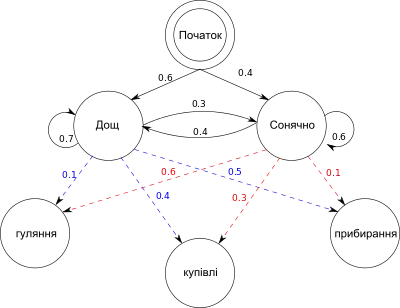
Розгляньмо двох приятелів, Алісу та Боба, які живуть далеко один від одного, і які щодня спілкуються телефоном про те, що вони робили цього дня. Боб цікавиться лише трьома заняттями: гулянням в парку, купівлями та прибиранням своєї квартири. Вибір, чим зайнятися, визначається виключно погодою цього дня. Аліса не має чіткої інформації про погоду в місці проживання Боба, але вона знає загальні тенденції. На підставі того, що Боб каже їй про те, що він робив кожного дня, Аліса намагається вгадати, якою, швидше за все, була погода.
Аліса вважає, що погода діє, як дискретний марковський ланцюг. Є два стани, «Сонячно» та «Дощ», але вона не може спостерігати їх безпосередньо, тобто, вони приховані від неї. Кожного дня є певний шанс, що Боб займатиметься одним із наступних занять, в залежності від погоди: «гуляння», «купівлі» та «прибирання». Оскільки Боб каже Алісі про свої заняття, вони є спостереженнями. Вся система в цілому є тим же, що й прихована марковська модель (ПММ).
Аліса знає загальні тенденції погоди в тій місцевості, і що Боб любить робити в середньому. Іншими словами, параметри ПММ відомі. Їх можна представити мовою програмування Python наступним чином:
# стани
states = ('Дощ', 'Сонячно')
# спостереження
observations = ('гуляння', 'купівлі', 'прибирання')
# початкова ймовірність
start_probability = {'Дощ': 0.6, 'Сонячно': 0.4}
# ймовірність переходу
transition_probability = {
'Дощ' : {'Дощ': 0.7, 'Сонячно': 0.3},
'Сонячно' : {'Дощ': 0.4, 'Сонячно': 0.6},
}
# ймовірність виходу
emission_probability = {
'Дощ' : {'гуляння': 0.1, 'купівлі': 0.4, 'прибирання': 0.5},
'Сонячно' : {'гуляння': 0.6, 'купівлі': 0.3, 'прибирання': 0.1},
}
У цьому фрагменті коду start_probability представляє думку Аліси про те, в якому стані знаходиться ПММ, коли Боб телефонує їй вперше (все, що вона знає, це те, що там зазвичай дощить). Конкретний розподіл ймовірності, що тут використовується, не є рівноважним, що є (при заданих ймовірностях переходів) приблизно {'Дощ': 0.57, 'Сонячно': 0.43}. transition_probability представляє зміну погоди в основному марковському ланцюгові. У цьому прикладі є лише 30% шансів, що завтра буде сонячно, якщо сьогодні дощить. emission_probability представляє, наскільки ймовірно Боб займатиметься певною справою за кожної погоди. Якщо дощить, є ймовірність 50%, що він прибиратиме у квартирі; якщо сонячно, є ймовірність 60%, що він гуляє надворі.
Подібний приклад розбирається далі на сторінці Viterbi algorithm.
Навчання
Задача навчання параметрів у ПММ полягає в знаходженні для заданої послідовності виходів або набору таких послідовностей найкращого набору ймовірностей переходів станів та виходів. Ця задача зазвичай полягає у виведенні оцінки максимальної правдоподібності цих параметрів ПММ для заданого набору послідовностей виходів. Не відомо жодного легкорозв'язного алгоритму для точного розв'язання цієї задачі, але локальну максимальну правдоподібність може бути дієво виведено із застосуванням Алгоритма Баума — Велша або алгоритму Бальді — Шовена. Алгоритм Баума — Велша є окремим випадком алгоритму очікування-максимізації.
Математичний опис
Загальний опис
Базову (не баєсову) приховану марковську модель може бути описано таким чином:
| кількість станів | ||||||
| кількість спостережень | ||||||
| параметр виходу для спостереження, пов'язаного зі станом | ||||||
| ймовірність переходу зі стану до стану | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати , рядок матриці | ||||||
| (прихований) стан у момент часу | ||||||
| спостереження в момент часу | ||||||
| розподіл ймовірностей спостережень, параметризований за | ||||||



















Зауважте що в наведеній вище моделі (а також і в наведеній нижче), апріорний розподіл початкового стану не вказано. Типові моделі навчання відповідають припусканню дискретного рівномірного розподілу можливих станів (тобто, припускається відсутність певного апріорного розподілу).

У баєсовому варіанті всі параметри пов'язано з випадковими змінними, а саме:
| як вище | ||||||
| як вище | ||||||
| як вище | ||||||
| спільний гіперпараметр для параметрів виходу | ||||||
| спільний гіперпараметр для параметрів переходу | ||||||
| апріорний розподіл ймовірності параметрів виходу, параметризований за | ||||||








Ці описи використовують та для опису довільних розподілів над спостереженнями та параметрами відповідно. Зазвичай буде спряженим апріорним розподілом . Двома найпоширенішими варіантами є нормальний та категорійний розподіли; див. нижче.


У порівнянні з простою сумішевою моделлю
Як зазначено вище, розподіл кожного спостереження у прихованій марковській моделі є сумішевою щільністю, де стани відповідають складовим суміші. Корисно порівняти наведені вище описи ПММ з відповідними характеристиками сумішевої моделі, використовуючи той самий запис.
Небаєсова сумішева модель:
| кількість складових суміші | ||||||
| кількість спостережень | ||||||
| параметр розподілу спостереження, пов'язаний зі складовою | ||||||
| сумішева вага, тобто, апріорна ймовірність складової | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати 1 | ||||||
| складова спостереження | ||||||
| спостереження | ||||||
| розподіл ймовірності спостереження, параметризований за | ||||||




Баєсова сумішева модель:
| як вище | ||||||
| як вище | ||||||
| як вище | ||||||
| спільний гіперпараметр для параметрів складових | ||||||
| спільний гіперпараметр для сумішевих ваг | ||||||
| апріорний розподіл ймовірності параметрів складових, параметризований за | ||||||

Приклади
Наступні математичні описи повністю розписано та пояснено для полегшення втілення.
Типова небаєсова ПММ з нормальним розподілом спостережень виглядає так:
| кількість станів | ||||||
| кількість спостережень | ||||||
| ймовірність переходу зі стану до стану | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати 1 | ||||||
| середнє спостережень, пов'язане зі станом | ||||||
| дисперсія спостережень, пов'язана зі станом | ||||||
| стан спостереження у момент часу | ||||||
| спостереження у момент часу | ||||||



Типова баєсова ПММ з нормальним розподілом спостережень виглядає так:
| кількість станів | ||||||
| кількість спостережень | ||||||
| ймовірність переходу зі стану до стану | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати 1 | ||||||
| середнє спостережень, пов'язане зі станом | ||||||
| дисперсія спостережень, пов'язана зі станом | ||||||
| стан спостереження у момент часу | ||||||
| спостереження у момент часу | ||||||
| гіперпараметр концентрації, що контролює щільність матриці переходу | ||||||
| спільні гіперпараметри для середніх для кожного стану | ||||||
| спільні гіперпараметри для дисперсій для кожного стану | ||||||




Типова небаєсова ПММ з категорійними спостереженнями виглядає так:
| кількість станів | ||||||
| кількість спостережень | ||||||
| ймовірність переходу зі стану до стану | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати 1 | ||||||
| розмірність категорійних спостережень, наприклад, розмір словника | ||||||
| ймовірність спостереження -того елементу в стані | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати 1 | ||||||
| стан спостереження у момент часу | ||||||
| спостереження у момент часу | ||||||





Типова баєсова ПММ з категорійними спостереженнями виглядає так:
| кількість станів | ||||||
| кількість спостережень | ||||||
| ймовірність переходу зі стану до стану | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати 1 | ||||||
| розмірність категорійних спостережень, наприклад, розмір словника | ||||||
| ймовірність спостереження -того елементу в стані | ||||||
| -мірний вектор, що складається з ; в сумі має дорівнювати 1 | ||||||
| стан спостереження у момент часу | ||||||
| спостереження у момент часу | ||||||
| спільний гіперпараметр концентрації для кожного стану | ||||||
| гіперпараметр концентрації, що контролює щільність матриці переходу | ||||||




Зауважте, що в наведених вище баєсових описах (параметр концентрації) контролює щільність матриці переходу. Тобто, при високому значенні (значно більше 1) ймовірності, що контролюють перехід з певного конкретного стану, будуть схожими між собою, що означає, що буде суттєва ймовірність переходу до будь-якого іншого стану. Іншими словами, шлях, пройдений ланцюгом Маркова прихованими станами, буде сильно випадковим. При низькому значенні (значно менше 1) лише мала кількість можливих переходів з певного заданого стану матиме значну ймовірність, що означає, що шлях, пройдений прихованими станами, буде до деякої міри передбачуваним.
Дворівнева баєсова ПММ
Альтернативою двох до наведених вище баєсових прикладів буде додавання до матриці переходу додаткового рівня апріорних параметрів. Тобто, замінити рядки
| гіперпараметр концентрації, що контролює щільність матриці переходу | ||||||
наступними:
| гіперпараметр концентрації, що контролює, як багато станів є притаманно ймовірними | ||||||
| гіперпараметр концентрації, що контролює щільність матриці переходу | ||||||
| -мірний вектор ймовірностей, що визначає притаманну ймовірність заданого стану | ||||||




Це означає наступне:
- є розподілом ймовірностей станів, що визначає, які стани є притаманно ймовірними. Що більшою є ймовірність заданого стану в цьому векторі, то більшою є ймовірність переходу до цього стану (незалежно від початкового стану).
- контролює щільність . Значення, значно більші за 1, призводять до такого вектора щільності, в якому всі стани мають схожі апріорні ймовірності. Значення, значно менші за 1, призводять до розрідженого вектора, де лише деякі стани притаманно ймовірні (мають апріорні ймовірності значно більше 0).
- контролює щільність матриці переходу, або, конкретніше, щільність різних векторів ймовірності , що визначають ймовірність переходів зі стану до будь-якого іншого стану.
Уявіть, що значення є значно більшим за 1. Тоді різні вектори будуть щільними, тобто, масу ймовірності буде розкидано досить порівну між всіма станами. Однак, в тій мірі, в якій цю масу розкидано нерівномірно, контролює, які стани ймовірніше отримають більше маси за інші.
Тепер замість цього уявіть, що є значно меншим за 1. Це зробить вектори розрідженими, тобто, майже всю масу ймовірності розподілено між невеликою кількістю станів, а щодо решти, то перехід до таких станів буде вельми малоймовірним. Зверніть увагу, що є різні вектори для кожного з початкових станів, і отже, навіть якщо всі вектори є розрідженими, різні вектори можуть перерозподіляти масу до різних кінцевих станів. Однак, для всіх векторів контролює, які кінцеві стани ймовірніше отримають призначення маси собі. Наприклад, якщо дорівнює 0.1, то кожен буде розрідженим, і, для будь-якого заданого початкового стану множина станів , переходи до яких будуть ймовірними, буде дуже маленькою, зазвичай з одним або двома елементами. Тепер, якщо ймовірності в є всі однаковими (або, рівноцінно, використовується одна з наведених вище моделей без ), то для різних будуть різні стани у відповідних , так що всі стани матимуть однакову ймовірність опинитися у довільно взятому . З іншого боку, якщо значення у є незбалансованими, так що один стан має значно більшу ймовірність за інші, то майже всі міститимуть цей стан; отже, незалежно від початкового стану, переходи майже завжди вестимуть до цього заданого стану.

Отже, така дворівнева модель, якщо щойно описано, дає можливість незалежного контролю над (1) загальною щільністю матриці переходів та (2) щільністю станів, переходи до яких є ймовірними (тобто, щільністю апріорного розподілу станів у будь-якій окремій прихованій змінній ). В обох випадках це робиться із збереженням припущення про невідомість того, які конкретні стани є ймовірнішими за інші. Якщо є бажання ввести цю інформацію до моделі, то можна безпосередньо задати вектор ймовірності ; або, якщо немає такої впевненості про ці відносні ймовірності, як апріорний розподіл над може бути використано несиметричний розподіл Діріхле. Тобто, замість використання симетричного розподілу Діріхле з єдиним параметром (або, рівноцінно, звичайного Діріхле з вектором, чиї значення всі дорівнюють ), використовувати звичайний Діріхле зі значеннями, що є по-різному більшими або меншими за , відповідно до того, якому станові віддається більше або менше переваги.

Пуассонівська прихована марковська модель
Пуассонівські приховані марковські моделі (ППММ, англ. Poisson hidden Markov models, PHMM) — це особливі випадки прихованих марковських моделей, в яких пуассонівський процес має темп, що варіюється у зв'язку зі змінами станів марковської моделі.[16] ППММ самі по собі не обов'язково є марковськими процесами, оскільки марковський ланцюг або марковський процес, що лежить в основі, спостерігати неможливо, а можливо спостерігати лише пуассонівський сигнал.
Застосування
ПММ можуть застосовуватися у багатьох сферах, де метою є виявлення послідовності даних, що не є безпосередньо спостережуваною (але інші дані, що залежать від цієї послідовності, є). До застосування входять:
- Кінетичний аналіз однієї молекули[17]
- Криптоаналіз
- Розпізнавання мовлення
- Синтез мовлення
- Розмічування частин мови
- Розділення документів у рішеннях для сканування
- Машинний переклад
- Часткові розряди
- Передбачення генів
- Вирівнювання біопослідовностей
- Аналіз часових рядів
- Розпізнавання діяльності
- Згортання білків[18]
- Виявлення метаморфних вірусів[19]
- Виявлення консервативних мотивів ДНК[20]
Історія
Послідовну та зворотню рекурсії, що використовуються у ПММ, так само як і розрахунки відособлених згладжувальних ймовірностей, було описано вперше Русланом Стратоновичем у 1960 році[6] (сторінки 160–162) та у пізніх 1950-х у його працях російською. Приховані марковські моделі було пізніше описано в низці статистичних робіт Леонарда Баума та інших авторів у другій половині 1960-х. Одним з перших застосувань ПММ було розпізнавання мовлення, починаючи з середини 1970-х.[21][22][23][24]
У другій половині 1980-х ПММ почали застосовуватися до аналізу біологічних послідовностей,[25] зокрема, ДНК. Відтоді у сфері біоінформатики вони стали всюдисущими.[26]
Типи
Приховані марковські моделі можуть моделювати складні марковські процеси, де стани видають спостереження відповідно до якогось розподілу ймовірностей. Одним з таких прикладів є нормальний розподіл, у такій прихованій марковській моделі вихід станів представлено нормальним розподілом.
Крім того, вони можуть представляти ще складнішу поведінку, коли вихід станів представлено сумішшю двох або більше нормальних розподілів, у такому випадку ймовірність генерації спостереження є добутком ймовірності спочатку вибору одного з нормальних розподілів, і ймовірності генерації цього спостереження з цього нормального розподілу.
Розширення
У розглянутих вище прихованих марковських моделях простір станів прихованих змінних є дискретним, тоді як самі спостереження можуть бути або дискретними (зазвичай згенерованими з категорійного розподілу), або неперервним (зазвичай з нормального розподілу). Приховані марковські моделі також може бути узагальнено, щоби дозволяти неперервні простори станів. Прикладами таких моделей є ті, де марковський процес над прихованими змінними є лінійною динамічною системою з лінійним зв'язком між пов'язаними змінними, і де всі приховані й спостережувані змінні слідують нормальному розподілові. В простих випадках, таких як щойно зазначені лінійні динамічні системи, точне висновування є легкорозв'язним (у цьому випадку з використанням фільтру Калмана); однак у загальному випадку точне висновування в ПММ з неперервними латентними змінними є нездійсненним, і можуть застосовуватися наближені методи, такі як розширений фільтр Калмана або частинковий фільтр.
Приховані марковські моделі є породжувальними моделями, в яких моделюється спільний розподіл спостережень та прихованих станів, або, еквівалентно, як апріорний розподіл прихованих станів (ймовірності переходу), так і умовний розподіл спостережень для заданих станів (ймовірності виходу). Наведені вище алгоритми неявно припускають рівномірний апріорний розподіл ймовірностей переходу. Однак, також можливо створити приховані марковські моделі з іншими типами апріорних розподілів. Очевидним кандидатом, при категорійному розподілі ймовірностей переходу, є розподіл Діріхле, що є спряженим апріорним розподілом категорійного розподілу. Зазвичай обирається симетричний розподіл Діріхле, що відображає незнання того, які стани є притаманно ймовірнішими за інші. Єдиний параметр цього розподілу (що називається параметром концентрації) контролює відносну щільність або розрідженість отримуваної матриці переходу. Вибір 1 породжує рівномірний розподіл. Значення, більші за 1, породжують щільну матрицю, в якій імовірності переходів між парами станів, ймовірно, будуть майже рівними. Значення, менші за 1, породжують розріджену матрицю, в якій для кожного заданого початкового стану лише невелика кількість кінцевих станів має не незначні ймовірності переходу. Також можливе використання дворівневого апріорного розподілу Діріхле, в якому один розподіл Діріхле (верхній розподіл) керує параметрами іншого розподілу Діріхле (нижнього розподілу), який, у свою чергу, керує ймовірностями переходу. Верхній розподіл керує загальним розподілом станів, визначаючи, наскільки ймовірно для кожного стану, що він трапиться; його концентраційний параметр визначає щільність або розрідженість станів. Такий дворівневий апріорний розподіл, де обидва концентраційні параметри встановлено на породження розріджених розподілів, можуть бути корисними, наприклад, у морфологічній розмітці без вчителя, де деякі частини мови трапляються значно частіше за інші; алгоритми навчання, що припускають рівномірний апріорний розподіл, загалом погано працюють з цією задачею. Параметри моделей такого роду, з нерівномірними апріорними розподілами, можуть отримуватися вибіркою за Ґіббсом або розширеними версіями алгоритму очікування-максимізації.
Розширення описаних вище прихованих марковських моделей з апріорними Діріхле використовує процес Діріхле замість розподілу Діріхле. Цей тип моделей дозволяє невідому, і потенційно нескінченну кількість станів. Загальноприйнято використовувати дворівневий процес Діріхле, подібно до описаної вище моделі з двома рівнями розподілів Діріхле. Така модель називається прихованою марковською моделлю з ієрархічним процесом Діріхле (ПММ-ІПД, англ. hierarchical Dirichlet process hidden Markov model, HDP-HMM). Початково її було описано під назвою «Нескінченна прихована марковська модель»[27] і було формалізовано далі у [28].
Інший тип розширень використовує розрізнювальну модель замість породжувальної моделі стандартної ПММ. Цей тип моделі моделює безпосередньо умовний розподіл прихованих станів при заданих спостереженнях, замість моделювання спільного розподілу. Прикладом цієї моделі є так звана марковська модель максимальної ентропії (МММЕ, англ. maximum entropy Markov model, MEMM), що моделює умовний розподіл станів за допомогою логістичної регресії (відома також як «модель максимальної ентропії»). Перевагою цього типу моделі є те, що вона дозволяє моделювати довільні властивості (тобто, функції) спостережень, що дозволяє введення до моделі предметно-орієнтованого знання задачі, яке є під руками. Моделі цього роду не обмежені моделюванням прямих залежностей між прихованими станами та пов'язаними з ними спостереженнями; швидше, для визначення значення прихованого стану до процесу можуть включатися властивості близьких спостережень, комбінацій пов'язаного спостереження і близьких спостережень, або факти довільних спостережень на будь-якій відстані від заданого прихованого стану. До того ж, не потрібно, щоби ці властивості були статистично незалежними одна від одної, як було би у випадку, якби такі властивості використовувалися у породжувальній моделі. Насамкінець, можуть використовуватися довільні властивості над парами суміжних прихованих станів, а не лише ймовірності переходів. Недоліками таких моделей є: (1) Типи апріорних розподілів, що може бути встановлено над прихованими станами, суворо обмежено; (2) Неможливо передрікти ймовірність побачити певне спостереження. Це друге обмеження часто не є проблемою на практиці, оскільки багато звичайних застосувань ПММ не вимагають таких передбачувальних можливостей.
Варіантом описаної вище розрізнювальної моделі є нерозгалужена умовна мережа (англ. linear-chain conditional random field). Вона використовує неспрямовану графічну модель (відому як марковська мережа) замість спрямованих графічних моделей марковської моделі максимальної ентропії, та подібних моделей. Перевагою цього типу моделей є те, що він не страждає від так званої проблеми міткової схильності (англ. label bias) марковських моделей максимальної ентропії, і тому може робити точніші передбачення. Недоліком є те, що навчання може бути повільнішим, ніж в марковських моделях максимальної ентропії.
Ще одним варіантом є факторіальна прихована марковська модель (англ. factorial hidden Markov model), що дозволяє єдиному спостереженню бути обумовленим відповідними прихованими змінними набору незалежних марковських ланцюгів, а не єдиного марковського ланцюга. Це еквівалентно єдиній ПММ з станів (за припущення, що кожен ланцюг має станів), і тому навчання такої моделі є складним: для послідовності довжиною прямолінійний алгоритм Вітербі має складність . Для знаходження точного розв'язку може використовуватися алгоритм дерева з'єднань (англ. junction tree algorithm), але це призводить до складності . На практиці можуть застосовуватися приблизні методи, такі як варіаційні підходи.[29]




Всі наведені вище моделі може бути розширено, щоби дозволити віддаленіші залежності серед прихованих станів, наприклад, дозволяючи заданому станові бути залежним від двох або трьох станів, а не від єдиного попереднього стану; тобто, ймовірності переходу розширюються для охоплення наборів трьох або чотирьох суміжних станів (або, в загальному випадку, суміжних станів). Недоліком таких моделей є те, що алгоритми динамічного програмування для їх навчання мають час виконання для суміжних станів та спостережень (тобто, маркового ланцюга довжиною ).

Іншим недавнім розширенням є трійкова марковська модель (англ. triplet Markov model),[30] у якій для моделювання деяких специфічностей даних додається допоміжний базовий процес. Було запропоновано багато варіантів цієї моделі. Варто також мати на увазі цікавий зв'язок, що встановився між теорією очевидності (англ. theory of evidence) та трійковими марковськими моделями,[10] який дозволяє вплавляти дані до марковського контексту[11] та моделювати нестаціонарні дані.[12][13]
Див. також
- Алгоритм Баума — Велша
- Алгоритм Вітербі
- Аналіз часових рядів
- Андрій Марков
- Багаторівнева прихована марковська модель
- Баєсове висновування
- Безкоштовна ПММ-програма HMMER для аналізу послідовностей білків
- Безкоштовний сервер та програмне забезпечення HHpred / HHsearch для пошуку послідовностей білків
- Ієрархічна прихована марковська модель
- Марковська модель змінного порядку
- Прихована модель Бернуллі
- Прихована напівмарковська модель
- Секвенційна динамічна система
- Стохастична контекстно-вільна граматика
- Теорія оцінювання
- Умовне випадкове поле
Примітки
- Baum, L. E.; Petrie T. (1966). Statistical Inference for Probabilistic Functions of Finite State Markov Chains. The Annals of Mathematical Statistics 37 (6): 1554–1563. doi:10.1214/aoms/1177699147. Процитовано 28 листопада 2011. (англ.)
- Baum, L. E.; Eagon J. A. (1967). An inequality with applications to statistical estimation for probabilistic functions of Markov processes and to a model for ecology. Bulletin of the American Mathematical Society 73 (3): 360. Zbl 0157.11101. doi:10.1090/S0002-9904-1967-11751-8. (англ.)
- Baum, L. E.; Sell G. R. (1968). Growth transformations for functions on manifolds. Pacific Journal of Mathematics 27 (2): 211–227. doi:10.2140/pjm.1968.27.211. Процитовано 28 листопада 2011. (англ.)
- Baum, L. E.; Petrie, T.; Soules, G.; Weiss, N. (1970). A Maximization Technique Occurring in the Statistical Analysis of Probabilistic Functions of Markov Chains. The Annals of Mathematical Statistics 41: 164. JSTOR 2239727. MR MR287613. Zbl 0188.49603. doi:10.1214/aoms/1177697196. (англ.)
- Baum, L.E. (1972). An Inequality and Associated Maximization Technique in Statistical Estimation of Probabilistic Functions of a Markov Process. Inequalities 3: 1–8. (англ.)
- Stratonovich, R.L. (1960). Conditional Markov Processes. Theory of Probability and its Applications 5 (2): 156–178. doi:10.1137/1105015. (англ.)
- Thad Starner, Alex Pentland. Real-Time American Sign Language Visual Recognition From Video Using Hidden Markov Models. Master's Thesis, MIT, Feb 1995, Program in Media Arts (англ.)
- B. Pardo and W. Birmingham. Modeling Form for On-line Following of Musical Performances. AAAI-05 Proc., July 2005. (англ.)
- Satish L, Gururaj BI (April 2003). «Use of hidden Markov models for partial discharge pattern classification». IEEE Transactions on Dielectrics and Electrical Insulation. (англ.)
- Pr. Pieczynski, W. Pieczynski, Multisensor triplet Markov chains and theory of evidence, International Journal of Approximate Reasoning, Vol. 45, No. 1, pp. 1-16, 2007. (англ.)
- Boudaren et al., M. Y. Boudaren, E. Monfrini, W. Pieczynski, and A. Aissani, Dempster-Shafer fusion of multisensor signals in nonstationary Markovian context, EURASIP Journal on Advances in Signal Processing, No. 134, 2012. (англ.)
- Lanchantin et al., P. Lanchantin and W. Pieczynski, Unsupervised restoration of hidden non stationary Markov chain using evidential priors, IEEE Trans. on Signal Processing, Vol. 53, No. 8, pp. 3091-3098, 2005. (англ.)
- Boudaren et al., M. Y. Boudaren, E. Monfrini, and W. Pieczynski, Unsupervised segmentation of random discrete data hidden with switching noise distributions, IEEE Signal Processing Letters, Vol. 19, No. 10, pp. 619-622, October 2012. (англ.)
- Lawrence Rabiner (лютий 1989). A tutorial on Hidden Markov Models and selected applications in speech recognition. Proceedings of the IEEE 77 (2): 257–286. doi:10.1109/5.18626. (англ.)
- Newberg, L. (2009). Error statistics of hidden Markov model and hidden Boltzmann model results. BMC Bioinformatics 10: 212. PMC 2722652. PMID 19589158. doi:10.1186/1471-2105-10-212. (англ.)
- R. Paroli. et al., Poisson hidden Markov models for time series of overdispersed insurance counts (англ.)
- NICOLAI, CHRISTOPHER (2013). SOLVING ION CHANNEL KINETICS WITH THE QuB SOFTWARE. Biophysical Reviews and Letters 8 (3n04): 191–211. doi:10.1142/S1793048013300053. (англ.)
- Stigler, J.; Ziegler, F.; Gieseke, A.; Gebhardt, J. C. M.; Rief, M. (2011). The Complex Folding Network of Single Calmodulin Molecules. Science 334 (6055): 512–516. PMID 22034433. doi:10.1126/science.1207598. (англ.)
- Wong, W.; Stamp, M. (2006). Hunting for metamorphic engines. Journal in Computer Virology 2 (3): 211–229. doi:10.1007/s11416-006-0028-7. (англ.)
- Wong, K. -C.; Chan, T. -M.; Peng, C.; Li, Y.; Zhang, Z. (2013). DNA motif elucidation using belief propagation. Nucleic Acids Research 41 (16): e153. PMC 3763557. PMID 23814189. doi:10.1093/nar/gkt574. (англ.)
- Baker, J. (1975). The DRAGON system--An overview. IEEE Transactions on Acoustics, Speech, and Signal Processing 23: 24–29. doi:10.1109/TASSP.1975.1162650. (англ.)
- Jelinek, F.; Bahl, L.; Mercer, R. (1975). Design of a linguistic statistical decoder for the recognition of continuous speech. IEEE Transactions on Information Theory 21 (3): 250. doi:10.1109/TIT.1975.1055384. (англ.)
- Xuedong Huang, M. Jack, and Y. Ariki (1990). Hidden Markov Models for Speech Recognition. Edinburgh University Press. ISBN 0-7486-0162-7. (англ.)
- Xuedong Huang, Alex Acero, and Hsiao-Wuen Hon (2001). Spoken Language Processing. Prentice Hall. ISBN 0-13-022616-5. (англ.)
- M. Bishop and E. Thompson (1986). Maximum Likelihood Alignment of DNA Sequences. Journal of Molecular Biology 190 (2): 159–165. PMID 3641921. doi:10.1016/0022-2836(86)90289-5. (англ.)
- Richard Durbin, Sean R. Eddy, Anders Krogh, Graeme Mitchison (1999). Biological Sequence Analysis: Probabilistic Models of Proteins and Nucleic Acids. Cambridge University Press. ISBN 0-521-62971-3. (англ.)
- Beal, Matthew J., Zoubin Ghahramani, and Carl Edward Rasmussen. «The infinite hidden Markov model.» Advances in neural information processing systems 14 (2002): 577–584. (англ.)
- Teh, Yee Whye, et al. «Hierarchical dirichlet processes.» Journal of the American Statistical Association 101.476 (2006). (англ.)
- Ghahramani, Zoubin; Jordan, Michael I. (1997). Factorial Hidden Markov Models. Machine Learning 29 (2/3): 245–273. doi:10.1023/A:1007425814087. (англ.)
- Triplet Markov Chain, W. Pieczynski,Chaînes de Markov Triplet, Triplet Markov Chains, Comptes Rendus de l'Académie des Sciences — Mathématique, Série I, Vol. 335, No. 3, pp. 275–278, 2002. (англ.)
Посилання
![]() Вікісховище має мультимедійні дані за темою: Прихована марковська модель
Вікісховище має мультимедійні дані за темою: Прихована марковська модель
Концепції
- Три основні задачі ПММ (рос.)
- Сергій Ніколенко. Лекції № 6 і № 7 (слайди), присвячені прихованим марковським моделям, із курсу «Теорія ймовірності» (рос.)
- Teif V. B. and K. Rippe (2010) Statistical-mechanical lattice models for protein-DNA binding in chromatin. J. Phys.: Condens. Matter, 22, 414105, http://iopscience.iop.org/0953-8984/22/41/414105 (англ.)
- A Revealing Introduction to Hidden Markov Models by Mark Stamp, San Jose State University. (англ.)
- Fitting HMM's with expectation-maximization — complete derivation (англ.)
- Switching Autoregressive Hidden Markov Model (SAR HMM) (англ.)
- A step-by-step tutorial on HMMs (University of Leeds) (англ.)
- Hidden Markov Models (an exposition using basic mathematics) (англ.)
- Hidden Markov Models (by Narada Warakagoda) (англ.)
- Hidden Markov Models: Fundamentals and Applications Part 1, Part 2 (by V. Petrushin) (англ.)
- Lecture on a Spreadsheet by Jason Eisner, Video and interactive spreadsheet (англ.)
Програмне забезпечення
- HMMdotEM (інструментарій для звичайних ПММ з дискретними станами, випущений під 3-пунктовою ліцензією BSD, наразі лише для Matlab)
- Hidden Markov Model (HMM) Toolbox for Matlab (інструментарій для Matlab від Кевіна Мерфі)
- Hidden Markov Model Toolkit (HTK) (переносний інструментарій для побудови й маніпулювання прихованими марковськими моделями)
- Hidden Markov Models (пакет для R для налаштування, застосування та отримання висновків за допомогою прихованих марковських моделей з дискретним часом і дискретним простором)
- HMMlib (оптимізована бібліотека для роботи зі звичайними (дискретними) прихованими марковськими моделями)
- parredHMMlib (паралельна реалізація послідовного алгоритму та алгоритму Вітербі. Надзвичайно швидка для ПММ з малими просторами станів)
- zipHMMlib (бібліотека для звичайних (дискретних) прихованих марковських моделей, що використовує повторення у вхідній послідовності для значного прискорення послідовного алгоритму. Також реалізовано алгоритм апостеріорного декодування та алгоритм Вітербі.)
- GHMM Library (домашня сторінка проекту GHMM Library)
- Jahmm Java Library[недоступне посилання з липня 2019] (Java-бібліотека загального призначення)
- ПММ та інші статистичні програми (Реалізація Тапаса Канунго для C)
- The hmm package (бібліотека для Haskell для роботи з прихованими марковськими моделями)
- GT2K (Georgia Tech Gesture Toolkit — пакет для розпізнавання жестів)
- Hidden Markov Models — Online Calculations (інтерактивний калькулятор для ПММ — шлях Вітербі та ймовірності. Приклади із сирцевим кодом на perl)
- CvHMM (клас дискретних прихованих марковських моделей, на базі OpenCV)
- depmixS4: Dependent Mixture Models — Hidden Markov Models of GLMs and Other Distributions in S4 (пакет для R)
- MLPACK (містить реалізацію ПММ для C++)
- Hidden Markov Models Java Library містить основні абстракції ПММ в Java 8
- SFIHMM швидкісний код C для оцінки прихованих марковських моделей, відтворення шляху Вітербі, та породження модельованих даних з ПММ.