Обмежена машина Больцмана
Обме́жена маши́на Бо́льцмана (ОМБ, англ. restricted Boltzmann machine, RBM) — це породжувальна стохастична штучна нейронна мережа, здатна навчатися розподілу ймовірностей над набором її входів.
ОМБ було спочатку винайдено під назвою Гармоніум (англ. Harmonium — фісгармонія) Полом Смоленським 1986 року,[1] а популярності вони набули після винайдення Джефрі Хінтоном зі співавторами у середині 2000-х років алгоритмів швидкого навчання для них. ОМБ знайшли застосування у зниженні розмірності,[2] класифікації,[3] колаборативній фільтрації,[4] навчанні ознак[5] та тематичному моделюванні.[6] Їх можна тренувати як керованим, так і спонтанним чином, в залежності від завдання.
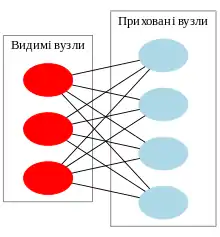
Як випливає з їхньої назви, ОМБ є варіантом машин Больцмана, з тим обмеженням, що їхні нейрони мусять формувати двочастковий граф: пара вузлів з кожної з двох груп вузлів (що, як правило, називають «видимим» та «прихованим» вузлами відповідно) можуть мати симетричне з'єднання між ними, але з'єднань між вузлами в межах групи не існує. На противагу, «необмежені» машини Больцмана можуть мати з'єднання між прихованими вузлами. Це обмеження уможливлює ефективніші алгоритми тренування, ніж доступні для загального класу машин Больцмана, зокрема, алгоритм порівня́льної розбі́жності (англ. contrastive divergence) на основі градієнтного спуску.[7]
Обмежені машини Больцмана можуть також застосовуватися в мережах глибинного навчання. Зокрема, глибинні мережі переконань можуть утворюватися «складанням» ОМБ та, можливо, тонким налаштуванням отримуваної глибинної мережі за допомогою градієнтного спуску та зворотного поширення.[8]
Структура
Стандартний тип ОМБ має двійковозначні (булеві/бернуллієві) приховані та видимі вузли, і складається з матриці вагових коефіцієнтів (розміру m×n), пов'язаної зі з'єднанням між прихованим вузлом та видимим вузлом , а також вагових коефіцієнтів упереджень (зсувів) для видимих вузлів, і для прихованих вузлів. З урахуванням цього, енергія конфігурації (пари булевих векторів) (v,h) визначається як






або, в матричному записі,

Ця функція енергії є аналогічною до функції енергії мережі Хопфілда. Як і в загальних машинах Больцмана, розподіли ймовірності над прихованими та/або видимими векторами визначаються в термінах функції енергії:[9]

де є статистичною сумою, визначеною як сума над усіма можливими конфігураціями (іншими словами, просто нормувальна стала для забезпечення того, щоби розподіл імовірності давав у сумі 1). Аналогічно, (відособлена) ймовірність видимого (вхідного) вектора булевих значень є сумою над усіма можливими конфігураціями прихованого шару:[9]



Оскільки ОМБ має форму двочасткового графу, без з'єднань усередині шарів, активації прихованих вузлів є взаємно незалежними для заданих активацій видимих вузлів, і навпаки, активації видимих вузлів є взаємно незалежними для заданих активацій прихованих вузлів.[7] Тобто, для видимих вузлів та прихованих вузлів умовною ймовірністю конфігурації видимих вузлів v для заданої конфігурації прихованих вузлів h є


- .

І навпаки, умовною ймовірністю h для заданої v є
- .

Окремі ймовірності активації задаються як
- та


де позначає логістичну сигмоїду.

Незважаючи на те, що приховані вузли є бернуллієвими, видимі вузли ОМБ можуть бути багатозначними. В такому випадку логістична функція для видимих вузлів замінюється нормованою експоненційною функцією (англ. Softmax function)

де K є кількістю дискретних значень, які мають видимі значення. Вони застосовуються в тематичному моделюванні[6] та рекомендаційних системах.[4]
Співвідношення з іншими моделями
Обмежені машини Больцмана є особливим випадком машин Больцмана та марковських випадкових полів.[10][11] Їхня графова модель відповідає моделі факторного аналізу.[12]
Алгоритм тренування
Обмежені машини Больцмана тренуються максимізувати добуток ймовірностей, призначених певному тренувальному наборові (матриця, кожен рядок якої розглядається як видимий вектор ),



або, рівноцінно, максимізувати математичне сподівання логарифмічної ймовірності :[10][11]

Алгоритмом, що найчастіше застосовується для тренування ОМБ, тобто для оптимізації вектора вагових коефіцієнтів , є алгоритм порівняльної розбіжності (ПР, англ. contrastive divergence, CD), що належить Хінтонові, первинно розроблений для тренування моделей добутку експертів (англ. product of experts, PoE).[13][14] Цей алгоритм здійснює вибірку за Ґіббсом, і використовується всередині процедури градієнтного спуску (подібного до того, як зворотне поширення використовується всередині такої процедури при тренуванні нейронних мереж прямого поширення) для обчислення уточнення вагових коефіцієнтів.

Елементарну, однокрокову процедуру порівняльної розбіжності (ПР-1, англ. CD-1) для єдиного зразка може бути описано таким чином:
- Взяти тренувальний зразок v, обчислити ймовірності прихованих вузлів, та вибрати вектор прихованої активації h з цього розподілу ймовірності.
- Обчислити зовнішній добуток v та h, і назвати це позитивним градієнтом.
- Спираючись на h, вибрати відбудову видимих вузлів v', а потім перевибрати з неї приховані активації h'. (крок вибірки за Ґіббсом)
- Обчислити зовнішній добуток v' та h', і назвати це негативним градієнтом.
- Покласти уточненням різницю позитивного та негативного градієнтів, помножену на певний темп навчання: .


Правило уточнення для упереджень a та b визначається аналогічно.
Практичну настанову з тренування ОМБ, написану Хінтоном, можна знайти на його домашній сторінці.[9]
Див. також
- Автокодувальник
- Глибинне навчання
- Машина Гельмгольца
- Нейронна мережа Хопфілда
Примітки
- Smolensky, Paul (1986). Chapter 6: Information Processing in Dynamical Systems: Foundations of Harmony Theory. У Rumelhart, David E.; McLelland, James L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations. MIT Press. с. 194–281. ISBN 0-262-68053-X. (англ.)
- Hinton, G. E.; Salakhutdinov, R. R. (2006). Reducing the Dimensionality of Data with Neural Networks. Science 313 (5786): 504–507. PMID 16873662. doi:10.1126/science.1127647. (англ.)
- Larochelle, H.; Bengio, Y. (2008). Classification using discriminative restricted Boltzmann machines Proceedings of the 25th international conference on Machine learning - ICML '08. с. 536. ISBN 9781605582054. doi:10.1145/1390156.1390224. (англ.)
- Salakhutdinov, R.; Mnih, A.; Hinton, G. (2007). Restricted Boltzmann machines for collaborative filtering Proceedings of the 24th international conference on Machine learning - ICML '07. с. 791. ISBN 9781595937933. doi:10.1145/1273496.1273596. (англ.)
- Coates, Adam; Lee, Honglak; Ng, Andrew Y. (2011). An analysis of single-layer networks in unsupervised feature learning International Conference on Artificial Intelligence and Statistics (AISTATS). (англ.)
- Ruslan Salakhutdinov and Geoffrey Hinton (2010). Replicated softmax: an undirected topic model. Neural Information Processing Systems 23. (англ.)
- Miguel Á. Carreira-Perpiñán and Geoffrey Hinton (2005). On contrastive divergence learning. Artificial Intelligence and Statistics. (англ.)
- Hinton, G. (2009). Deep belief networks. Scholarpedia 4 (5): 5947. doi:10.4249/scholarpedia.5947. (англ.)
- Geoffrey Hinton (2010). A Practical Guide to Training Restricted Boltzmann Machines. UTML TR 2010—003, University of Toronto. (англ.)
- Sutskever, Ilya; Tieleman, Tijmen (2010). On the convergence properties of contrastive divergence. Proc. 13th Int'l Conf. on AI and Statistics (AISTATS). Архів оригіналу за 10 червня 2015. Процитовано 13 січня 2016. (англ.)
- Asja Fischer and Christian Igel. Training Restricted Boltzmann Machines: An Introduction Архівовано 10 червня 2015 у Wayback Machine.. Pattern Recognition 47, pp. 25-39, 2014 (англ.)
- María Angélica Cueto; Jason Morton; Bernd Sturmfels (2010). Geometry of the restricted Boltzmann machine. Algebraic Methods in Statistics and Probability (American Mathematical Society) 516. arXiv:0908.4425.[недоступне посилання з квітня 2019] (англ.)
- Geoffrey Hinton (1999). Products of Experts. ICANN 1999. (англ.)
- Hinton, G. E. (2002). Training Products of Experts by Minimizing Contrastive Divergence. Neural Computation 14 (8): 1771–1800. PMID 12180402. doi:10.1162/089976602760128018. (англ.)
Посилання
- Введення до обмежених машин Больцмана. Блог Едвіна Чена (англ. Edwin Chen), 18 липня 2011 р. (англ.)
- Керівництво з обмежених машин Больцмана для початківців. Документація Deeplearning4j (англ.)
- Розуміння ОМБ. Документація Deeplearning4j, 4 серпня 2015 р. (англ.)
