Бутстрепова агрегація
Бутстреп агрегація (англ. Bootstrap aggregating) — це машинний навчальний груповий мета-алгоритм, створений для покращення стабільності і точності машинних навчальних алгоритмів, які використовують статистичні класифікації і регресії. Він також зменшує неточність, хоча зазвичай застосовується до методів «дерева рішень», але може використовуватися з будь-яким типом методів.
Метод схожий на ансамбль методів однак, замість використання декількох моделей на одних і тих самих данних, кожна модель застосовується до різних вибірок отриманих методом бутстреп. [1]
Опис методу
Наприклад, дано стандартний навчальний набір D розміром n. Даний мета-алгоритм сукупності створює нові навчальні зразки , відбираючи однорідно або із заміною зразки з набору D , кожен з яких розміром nʹ. Деякі спостереження можуть повторюватися в кожному . Якщо n′=n, тоді для великого n набір очікувано матиме дріб (1 — 1/e) (≈63.2 %) єдиних прикладів D, а всі інші будуть дублюватися. Такий вид відбору відомий як бутстреп відбір.

Сумування приводить до «покращення нестійких процедур» (Брейман, 1996), які включають, наприклад, штучні нервові системи, класифікаційні і регресивні дерева та відбір підгрупи в лінійній регресії (Брейман, 1996). Цікаве застосування алгоритму показано тут.[2][3] Алгоритм трішки понижує значення стійких методів таких як К-найближчі сусіди (Брейман, 1996).
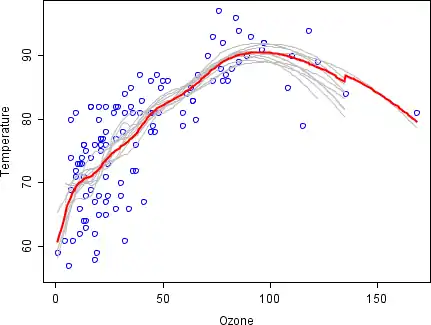
Приклад: Озон
Щоб проілюструвати основні принципи бутстрепу, нижче показано аналіз відношення між озоном і температурою (дані з Rousseeuw and Leroy (1986), доступно в класичних наборах даних, аналіз робиться в R (мова програмування).
Взаємозв'язок між озоном і температурою в цьому прикладі є очевидно нелінійним, що видно на розсіяному графіку. Щоб описати математично це відношення застосовують LOESS рівні частинки. Замість того, щоб побудувати одну точку з повним набором даних, зразу намалювали 100 зразків за аналогією. Кожен зразок відрізняється від початкового набору даних, але він схожий за розподілом і мінливістю. Прогноз був зроблений на основі 100 груп. Перші 10 прогнозованих зразків є сірими лініями на графіку, які є дуже гнучкими.
Беручи середнє число із 100 зразків, кожний з них встановлює підгрупу початкових даних, ми підходимо до одного сукупного прогнозованого — це червоні лінії на графіку.
Сукупність найближчих сусідніх класифікаторів
Похибка одного найближчого сусіднього класифікатора є вдвічі більшою за похибку Баєсовського класифікатора.[4] За допомогою уважного вибору розміру зразків сукупність сумування цих зразків може привести до помітного покращення 1NN класифікатора. Беручи велику кількість зразків розміром , супутній найближчий класифікатор буде послідовним, забезпечуючи та відходячи від норми, але як відібраний розмір .




Під безкінечною симуляцією сукупний найближчий сусідній класифікатор може розглядатися як масовий найближчий сусідній класифікатор. Допускаємо, що характерний простір є вимірним і позначається , сукупний найближчий класифікатор базується на навчальному наборі розміром та зі зразком розміром . У безкінечному відборі зразків за певних регулярних умов на групових розподілах крайня похибка має наступну формулу[5]




для деяких констант and . Оптимальний вибір nʹ, що збалансовує два терміни, є у формулі для деякої константи .




{kind=link}
Історія
Бутстреп агрегація була запропонована Лео Брейманом у 1994 році для покращення класифікації випадково утворених наборів даних. See Breiman, 1994. Technical Report No. 421.
Див. також
- Підсилювання (машинне навчання)
- Статистичний бутстреп
- Перехресне затверджування
- Random forest
- Random subspace method (attribute bagging)
Примітки
- Practical Statistics for Data Scientists [Book]. www.oreilly.com (англ.). Процитовано 21 травня 2021.
- Sahu, A., Runger, G., Apley, D., Image denoising with a multi-phase kernel principal component approach and an ensemble version, IEEE Applied Imagery Pattern Recognition Workshop, pp.1-7, 2011.
- Shinde, Amit, Anshuman Sahu, Daniel Apley, and George Runger. «Preimages for Variation Patterns from Kernel PCA and Bagging.» IIE Transactions, Vol.46, Iss.5, 2014
- Castelli, Vittorio. Nearest Neighbor Classifiers, p.5. columbia.edu. Columbia University. Процитовано 25 квітня 2015.
- Samworth R. J. (2012). Optimal weighted nearest neighbour classifiers. Annals of Statistics 40 (5): 2733–2763. doi:10.1214/12-AOS1049.
Посилання
- Breiman, Leo (1996). Bagging predictors. Machine Learning 24 (2): 123–140. doi:10.1007/BF00058655. CiteSeerX: 10.1.1.121.7654.
- Alfaro, E., Gámez, M. and García, N. (2012). adabag: An R package for classification with AdaBoost.M1, AdaBoost-SAMME and Bagging.