Варіаційний автокодувальник
У машинному навчанні варіаційний автокодувальник (англ. variational autoencoder),[1] відомий також як ВАК (англ. VAE), — це архітектура штучної нейронної мережі, запроваджена Дідеріком П. Кінгмою та Максом Веллінгом, що належить до сімейств імовірнісних графових моделей та варіаційних баєсових методів.
Її часто асоціюють із моделлю автокодувальника[2][3] через її архітектурну спорідненість, але між ними є значні відмінності як у цілі, так і в математичному формулюванні. Варіаційні автокодувальники призначено для стискання інформації входу до обмеженого багатовимірного латентного розподілу (кодування), щоби відбудовувати її якомога точніше (декодування). Хоча первинно цей тип моделі було розроблено для спонтанного навчання,[4][5] його дієвість було доведено й в інших областях машинного навчання, таких як напівавтоматичне[6][7] та кероване навчання.[8]
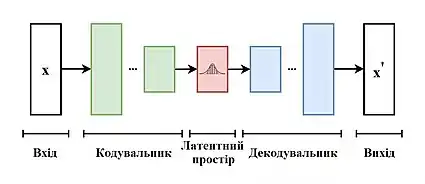
Архітектура
Варіаційні автокодувальники є варіаційними баєсовими методами з багатовимірним розподілом як апріорне, й апостеріорним, наближуваним штучною нейронною мережею, що утворюють так звану структуру варіаційного кодувальника-декодувальника.[9][10][11]
Стандартний кодувальник є штучною нейронною мережею, здатною зводити свою вхідну інформацію до найвужчого подання, що називають латентним простором. Він являє собою першу половину архітектури як автокодувальника, так і варіаційного автокодувальника: для першого виходом є фіксований вектор штучних нейронів, а в другому інформація виходу стискається до ймовірнісного латентного простору, що все ще складається зі штучних нейронів. Проте в архітектурі варіаційного автокодувальника вони представляють і їх розглядають як два різні вектори однакової вимірності, що подають вектор середніх значень та вектор стандартних відхилень відповідно.
Стандартний декодувальник все ще є штучною нейронною мережею, призначеною віддзеркалювати архітектуру кодувальника. Він бере на вході стиснену інформацію, що надходить із латентного простору, а потім розгортає її, виробляючи вихід, якомога ближчий до входу кодувальника. І хоча для автокодувальника вхід декодувальника є просто вектором дійсних значень фіксованої довжини, для варіаційного автокодувальника необхідно ввести проміжний етап: враховуючи ймовірнісну природу латентного простору, можливо розглядати його як багатовимірний гауссів вектор. За цього припущення й за допомогою методики, відомої як перепараметрувальний трюк (англ. reparametrization trick), можливо вибирати сукупності з цього латентного простору й розглядати їх точно як вектор дійсних значень фіксованої довжини.
З системної точки зору моделі як стандартного, так і варіаційного автокодувальників отримують як вхід набір даних великої розмірності. Потім вони адаптивно стискають його до латентного простору (кодування) і, нарешті, намагаються якомога точніше його відбудувати (декодування). Враховуючи природу його латентного простору, варіаційний автокодувальник характеризується дещо іншою цільовою функцією: він має мінімізувати функцію втрат відбудови, як і стандартний автокодувальник. Проте він також враховує розходження Кульбака — Лейблера між латентним простором та вектором нормальних гауссіан.
Формулювання


З формальної точки зору, за заданого набору даних входу , описуваного невідомою функцією ймовірності , та багатовимірного вектору латентного кодування , мета полягає в моделюванні цих даних як розподілу , де визначено як набір параметрів мережі.




Цей розподіл можливо формалізувати як

де є свідченням даних цієї моделі з відособленням, виконаним над неспостережуваними змінними, й відтак подає спільний розподіл даних входу та їхнього латентного подання відповідно до параметрів мережі .


Відповідно до теореми Баєса, це рівняння можливо переписати як

У стандартному варіаційному автокодувальнику ми вважаємо, що має скінченну розмірність, і що є гауссовим розподілом, тоді є сумішшю гауссових розподілів.

Тепер можливо визначити набір взаємозв'язків між даними входу та їх латентним поданням як
- Апріорне
- Правдоподібність
- Апостеріорне



На жаль, обчислення є дуже витратним, і в більшості випадків навіть непіддатливим. Щоби пришвидшити це обчислення й зробити його здійсненним, необхідно ввести додаткову функцію для наближення апостеріорного розподілу:

де визначено як набір дійсних значень, що параметрує .


Таким чином загальну задачу можливо легко перевести до області визначення автокодувальника, в якому розподіл умовної правдоподібності провадиться імовірнісним кодувальником (англ. probabilistic encoder), а наближений апостеріорний розподіл обчислюється імовірнісним декодувальником (англ. probabilistic decoder).

Функція втрат НМЕС
Як і в будь-якій задачі глибинного навчання, щоб уточнювати ваги мережі шляхом зворотного поширення, необхідно визначити диференційовну функцію втрат.
Для варіаційних автокодувальників ідея полягає в спільному мінімізуванні параметрів породжувальної моделі , щоби зменшувати похибку відбудови між входом і виходом мережі, та , щоби мати якомога ближчою до .
Як втрати відбудови, добрими варіантами є середньоквадратична похибка та перехресна ентропія.
Як втрати відстані між цими двома розподілами, добрим вибором, щоби втискувати під , є обернене розходження Кульбака — Лейблера .[1][12]

Щойно визначені втрати відстані розкриваються як

На цьому етапі можливо переписати це рівняння як

Метою є максимізувати логарифмічну правдоподібність лівої частини цього рівняння для поліпшення якості породжуваних даних та мінімізування відстаней між розподілами справжнього та оцінюваного апостеріорних.
Це є рівнозначним мінімізуванню від'ємної логарифмічної правдоподібності, що є типовою практикою в задачах оптимізації.
Отриману таким чином функцію втрат, яку також називають функцією втрат нижньої межі свідчення (англ. evidence lower bound), скорочено НМЕС (англ. ELBO), можливо записати як

Враховуючи властивість невід'ємності розходження Кульбака — Лейблера, буде правильним стверджувати, що

Оптимальними параметрами є ті, які мінімізують цю функцію втрат. Цю задачу можливо узагальнити як

Основна перевага цього формулювання полягає в можливості спільного оптимізування за параметрами та .
Перш ніж застосовувати функцію втрат НМЕС до задачі оптимізування для зворотного поширення градієнта, необхідно зробити її диференційовною, застосувавши так званий трюк перепараметрування (англ. reparameterization trick), щоб усунути стохастичне вибирання з цього формування, й таким чином зробити її диференційовною.
Трюк перепараметрування


Щоб зробити формулювання НМЕС придатним для цілей тренування, необхідно ввести подальшу незначну зміну до формулювання задачі, а також до структури варіаційного автокодувальника.[1][13][14]
Стохастичне вибирання є недиференційовною операцією, через яку можливо вибирати з латентного простору й подавати на ймовірнісний декодувальник.
Щоб уможливити застосування процесів зворотного поширення, таких як стохастичний градієнтний спуск, запроваджують трюк перепараметрування.
Основним припущенням про латентний простір є те, що його можливо розглядати як сукупність багатовимірних гауссових розподілів і, отже, можливо описати як

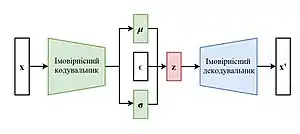
Якщо , а визначено як поелементний добуток, то трюк перепараметрування змінює наведене вище рівняння до


.

Завдяки цьому перетворенню, яке можливо поширити й на інші розподіли, відмінні від гауссового, варіаційний автокодувальник піддається тренуванню, а ймовірнісний кодувальник має навчатися відображувати стиснене подання вхідних даних у два латентні вектори та , тоді як стохастичність залишається виключеною з процесу уточнювання, й вводиться до латентного простору як зовнішній вхід через випадковий вектор .



Різновиди
Існує багато застосувань і розширень варіаційних автокодувальників для пристосовування цієї архітектури до різних областей та поліпшення її продуктивності.
β-ВАК (англ. β-VAE) є втіленням зі зваженим членом розходження Кульбака — Лейблера для автоматичного виявляння та інтерпретування розкладених латентних подань. За допомогою цього втілення можливо нав'язувати розплутування многовиду для значень , більших за одиницю. Автори показали здатність цієї архітектури породжувати високоякісні синтетичні зразки.[15][16]

Ще одне втілення, назване умовним варіаційним автокодувальником (англ. conditional variational autoencoder), скорочено УВАК (англ. CVAE), як вважають, вставляє міткову інформацію до латентного простору, нав'язуючи детерміноване обмежене подання навчених даних.[17]
Деякі структури безпосередньо займаються якістю породжуваних зразків[18][19] або втілюють понад одного латентного простору для подальшого поліпшення навчання подань.[20][21]
Деякі архітектури поєднують структури варіаційних автокодувальників та породжувальних змагальних мереж, щоб отримувати гібридні моделі з високими породжувальними спроможностями.[22][23][24]
Див. також
- Автокодувальник
- Глибинне навчання
- Збільшування даних
- Зворотне поширення
- Навчання подань
- Навчання розріджених словників
- Породжувальна змагальна мережа
- Штучна нейронна мережа
Примітки
- Kingma, Diederik P.; Welling, Max (2014-05-01). «Auto-Encoding Variational Bayes». arXiv:1312.6114 [stat.ML]. (англ.)
- Kramer, Mark A. (1991). Nonlinear principal component analysis using autoassociative neural networks. AIChE Journal (англ.) 37 (2): 233–243. doi:10.1002/aic.690370209. (англ.)
- Hinton, G. E.; Salakhutdinov, R. R. (28 липня 2006). Reducing the Dimensionality of Data with Neural Networks. Science (англ.) 313 (5786): 504–507. Bibcode:2006Sci...313..504H. PMID 16873662. doi:10.1126/science.1127647. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Dilokthanakul, Nat; Mediano, Pedro A. M.; Garnelo, Marta; Lee, Matthew C. H.; Salimbeni, Hugh; Arulkumaran, Kai; Shanahan, Murray (2017-01-13). «Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders». arXiv:1611.02648 [cs.LG]. (англ.)
- Hsu, Wei-Ning; Zhang, Yu; Glass, James (December 2017). Unsupervised domain adaptation for robust speech recognition via variational autoencoder-based data augmentation. 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). с. 16–23. ISBN 978-1-5090-4788-8. arXiv:1707.06265. doi:10.1109/ASRU.2017.8268911. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Ehsan Abbasnejad, M.; Dick, Anthony; van den Hengel, Anton (2017). Infinite Variational Autoencoder for Semi-Supervised Learning. с. 5888–5897. (англ.)
- Xu, Weidi; Sun, Haoze; Deng, Chao; Tan, Ying (12 лютого 2017). Variational Autoencoder for Semi-Supervised Text Classification. Proceedings of the AAAI Conference on Artificial Intelligence (англ.) 31 (1). (англ.)
- Kameoka, Hirokazu; Li, Li; Inoue, Shota; Makino, Shoji (1 вересня 2019). Supervised Determined Source Separation with Multichannel Variational Autoencoder. Neural Computation 31 (9): 1891–1914. PMID 31335290. doi:10.1162/neco_a_01217. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - An, J., & Cho, S. (2015). Variational autoencoder based anomaly detection using reconstruction probability. Special Lecture on IE, 2(1). (англ.)
- A bot will complete this citation soon. Click here to jump the queue«Model-Aware Deep Architectures for One-Bit Compressive Variational Autoencoding». arXiv:1911.12410. 2019. (англ.)
- Kingma, Diederik P.; Welling, Max (2019). An Introduction to Variational Autoencoders. Foundations and Trends in Machine Learning 12 (4): 307–392. ISSN 1935-8237. arXiv:1906.02691. doi:10.1561/2200000056. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - From Autoencoder to Beta-VAE. Lil'Log (англ.). 12 серпня 2018.
- Bengio, Yoshua; Courville, Aaron; Vincent, Pascal (2013). Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (8): 1798–1828. ISSN 1939-3539. PMID 23787338. arXiv:1206.5538. doi:10.1109/TPAMI.2013.50. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.) - Kingma, Diederik P.; Rezende, Danilo J.; Mohamed, Shakir; Welling, Max (2014-10-31). «Semi-Supervised Learning with Deep Generative Models». arXiv:1406.5298 [cs.LG]. (англ.)
- >Higgins, Irina; Matthey, Loic; Pal, Arka; Burgess, Christopher; Glorot, Xavier; Botvinick, Matthew; Mohamed, Shakir; Lerchner, Alexander (4 листопада 2016). beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework (англ.). (англ.)
- >Burgess, Christopher P.; Higgins, Irina; Pal, Arka; Matthey, Loic; Watters, Nick; Desjardins, Guillaume; Lerchner, Alexander (2018-04-10). «Understanding disentangling in β-VAE». arXiv:1804.03599 [stat.ML]. (англ.)
- Sohn, Kihyuk; Lee, Honglak; Yan, Xinchen (1 січня 2015). Learning Structured Output Representation using Deep Conditional Generative Models (англ.). (англ.)
- Dai, Bin; Wipf, David (2019-10-30). «Diagnosing and Enhancing VAE Models». arXiv:1903.05789 [cs.LG]. (англ.)
- Dorta, Garoe; Vicente, Sara; Agapito, Lourdes; Campbell, Neill D. F.; Simpson, Ivor (2018-07-31). «Training VAEs Under Structured Residuals». arXiv:1804.01050 [stat.ML]. (англ.)
- Tomczak, Jakub; Welling, Max (31 березня 2018). VAE with a VampPrior. International Conference on Artificial Intelligence and Statistics (англ.) (PMLR): 1214–1223. arXiv:1705.07120. (англ.)
- Razavi, Ali; Oord, Aaron van den; Vinyals, Oriol (2019-06-02). «Generating Diverse High-Fidelity Images with VQ-VAE-2». arXiv:1906.00446 [cs.LG]. (англ.)
- Larsen, Anders Boesen Lindbo; Sønderby, Søren Kaae; Larochelle, Hugo; Winther, Ole (11 червня 2016). Autoencoding beyond pixels using a learned similarity metric. International Conference on Machine Learning (англ.) (PMLR): 1558–1566. arXiv:1512.09300. (англ.)
- Bao, Jianmin; Chen, Dong; Wen, Fang; Li, Houqiang; Hua, Gang (2017). «CVAE-GAN: Fine-Grained Image Generation Through Asymmetric Training». arXiv:1703.10155 [cs.CV]. (англ.)
- >Gao, Rui; Hou, Xingsong; Qin, Jie; Chen, Jiaxin; Liu, Li; Zhu, Fan; Zhang, Zhao; Shao, Ling (2020). Zero-VAE-GAN: Generating Unseen Features for Generalized and Transductive Zero-Shot Learning. IEEE Transactions on Image Processing 29: 3665–3680. Bibcode:2020ITIP...29.3665G. ISSN 1941-0042. PMID 31940538. doi:10.1109/TIP.2020.2964429. Проігноровано невідомий параметр
|s2cid=(довідка) (англ.)