Розходження Кульбака — Лейблера
В математичній статистиці розхо́дження, диверге́нція або ві́дстань Кульбака — Лейблера (що також називають відно́сною ентропі́єю, англ. Kullback–Leibler divergence, relative entropy) є мірою того, наскільки один розподіл імовірності відрізняється від іншого, еталонного розподілу ймовірності.[1][2] До його застосувань належать відно́сна (шеннонова) ентропі́я в інформаційних системах, випадко́вість (англ. randomness) у неперервних часових рядах, та при́ріст інформа́ції (англ. information gain) при порівнюванні статистичних моделей висновування. На противагу до різновидності інформації, воно є асиметричною міжрозподіловою мірою, і відтак не відповідає вимогам статистичної метрики розкиду. В простому випадку нульове розходження Кульбака — Лейблера показує, що два розглядані розподіли є ідентичними. Простішими словами, воно є мірою несподіваності, з різноманітними застосуваннями, такими як прикладна статистика, гідромеханіка, нейронаука та машинне навчання.
| Теорія інформації |
|---|
 |
|
|
|
Етимологія
Розходження Кульбака — Лейблера було запропоновано 1951 року Соломоном Кульбаком та Річардом Лейблером як орієнто́ване розхо́дження (англ. directed divergence) між двома розподілами; Кульбак віддавав перевагу термінові інформа́ція розрі́знення (англ. discrimination information).[3] Це розходження обговорено в книзі Кульбака 1959 року «Теорія інформації та статистика».[2]
Означення
Для дискретних розподілів ймовірності та , визначених на одному й тому ж імовірнісному просторі, розходженням Кульбака — Лейблера означено[4]


|
() |

що є рівнозначним

Іншими словами, воно є математичним сподіванням логарифмічної різниці між імовірностями та , де математичне сподівання беруть із застосуванням ймовірностей . Розходження Кульбака — Лейблера можливо визначити лише якщо для будь-якого означає (абсолютна неперервність). Коли є нулем, внесок відповідного члену розцінюють як нульовий, оскільки





Для розподілів та неперервної випадкової змінної розходженням Кульбака — Лейблера означують інтеграл[5]
|
() |

де символами та позначено густини імовірності та .


Загальніше, якщо та є ймовірнісними мірами над множиною , а є абсолютно неперервною щодо , то розходженням Кульбака — Лейблера від до означують


де є похідною Радона — Нікодима щодо , і за умови існування правобічного виразу. Це може бути рівнозначно (згідно ланцюгового правила) записано як


що є ентропією відносно . У продовження цього випадку, якщо є будь-якою мірою на , для якої існують та (що означає, що та є абсолютно неперервними щодо ), то розходження Кульбака — Лейблера від до задають як




Логарифми в цих формулах беруть за основою 2, якщо інформацію вимірюють в одиницях бітів, або за основою , якщо інформацію вимірюють в натах. Більшість формул, що залучають розходження Кульбака — Лейблера, виконуються не залежно від основи логарифму.

Існують різні угоди, як посилатися на словами. Часто на нього посилаються як на розходження між та , проте, це не передає фундаментальної асиметричності в цьому відношенні. Іноді, як у цій статті, можна знайти його опис як розходження від, або щодо . Це віддзеркалює асиметричність баєсового висновування, що починається від апріорного , і уточнюється до апостеріорного .

Простий приклад
Кульбак[2] наводить простий приклад (таблиця 2.1, приклад 2.1). Нехай та є розподілами, показаними в таблиці й на малюнку. є розподілом з лівого боку малюнку, біноміальним розподілом з та . є розподілом з правого боку малюнку, дискретним рівномірним розподілом з трьома можливими результатами, , чи (тобто, ), кожен з імовірністю .








| x | 0 | 1 | 2 |
|---|---|---|---|
| Розподіл P(x) | 0.36 | 0.48 | 0.16 |
| Розподіл Q(x) | 0.333 | 0.333 | 0.333 |
КЛ-розходження та обчислюють із застосуванням означення (1) наступним чином. Цей приклад використовує натуральний логарифм з основою e, позначуваний , щоби отримати результати в натах (див. Одиниці вимірювання інформації).




Інтерпретації
Розходження Кульбака — Лейблера від до часто позначують через .
В контексті машинного навчання часто називають приростом інформації, отримуваним при застосовуванні замість . За аналогією з теорією інформації, його також називають відно́сною ентропі́єю (англ. relative entropy) щодо . В контексті теорії кодування можливо тлумачити як вимірювання математичного сподівання числа додаткових бітів, необхідних для кодування зразків з із застосуванням коду, оптимізованого для , замість коду, оптимізованого для .
Виражене мовою баєсового висновування, є мірою приросту інформації при перегляді переконань від апріорного розподілу ймовірності до апостеріорного розподілу ймовірності . Іншими словами, це величина інформації, що втрачається при застосуванні для наближення .[6] У застосуваннях зазвичай представляє «істинний» розподіл даних, спостережень, або точно обчислений теоретичний розподіл, тоді як зазвичай представляє теорію, модель, опис, або наближення . Щоби знаходити розподіл , який є найближчим до , ми можемо мінімізувати КЛ-розходження, обчислюючи інформаційну проекцію.
Розходження Кульбака — Лейблера є окремим випадком ширшого класу розходжень, що називають f-розходженнями, а також класу брегманових розходжень. Воно є єдиним таким розходженням над імовірностями, що належить до обох класів. І хоч його й часто інтуїтивно сприймають як спосіб вимірювання відстані між розподілами ймовірності, розходження Кульбака — Лейблера не є справжньою метрикою. З ним не дотримується нерівність трикутника, і в загальному випадку не дорівнює . Проте, його нескінченно малий вигляд, а саме його гессіан, дає метричний тензор, відомий як фішерова інформаційна метрика.
Характеризування
Артур Гобсон довів, що розходження Кульбака — Лейблера є єдиною мірою відмінності між розподілами ймовірності, яка задовольняє деякі бажані властивості, що є канонічним розширенням присутніх у широко вживаному характеризуванні ентропії.[7] Отже, взаємна інформація є єдиною мірою взаємної залежності, яка дотримується певних пов'язаних умов, оскільки її може бути визначено в термінах розходження Кульбака — Лейблера.
Існує також баєсове характеризування розходження Кульбака — Лейблера.[8]
Обґрунтування

В теорії інформації теорема Крафта — Макміллана встановлює, що будь-яку безпосередньо розкодовувану схему кодування для кодування повідомлення для виявляння одного значення з ряду можливостей можливо розглядати як представлення неявного розподілу ймовірності над , де є довжиною коду для в бітах. Отже, розходження Кульбака — Лейблера можливо інтерпретувати як математичне сподівання додаткової довжини повідомлення над рівнем, яка мусить передаватися, якщо застосовується код, що є оптимальним для заданого (неправильного) розподілу , в порівнянні з застосуванням коду, що ґрунтується на істинному розподілі .





де є перехресною ентропією та , а є ентропією .


Зауважте також, що існує зв'язок між розходженням Кульбака — Лейблера та «функцією відхилень» в теорії великих відхилень.[9][10]
Властивості
- Розходження Кульбака — Лейблера є завжди невід'ємним,
- результат, відомий як нерівність Гіббза, з нульовим якщо і лише якщо майже скрізь. Ентропія відтак встановлює мінімальне значення для перехресної ентропії , математичного сподівання числа бітів, необхідних при використанні коду на основі замість , і, відтак, розходження Кульбака — Лейблера представляє математичне сподівання числа додаткових бітів, що мусять передаватися, щоби ідентифікувати значення , вибране з , якщо застосовується код, що відповідає розподілові ймовірності , а не «істинному» розподілові .


- Розходження Кульбака — Лейблера залишається однозначно означеним і для неперервних розподілів, а до того ж ще й інваріантним відносно перетворень параметрів. Наприклад, якщо здійснюють перетворення змінної на змінну , то, оскільки та , розходження Кульбака — Лейблера може бути переписано:



- де та . І хоча й передбачалося, що перетворення було неперервним, але це не є обов'язковим. Це також показує, що розходження Кульбака — Лейблера дає розмірнісно стійку величину, оскільки якщо є змінною з розмірністю, то та також мають розмірності, бо, наприклад, розмірностей не має. Аргумент логарифмічного члену є й залишається безрозмірнісним, як він і мусить. Отже, це можливо розглядати як певним чином фундаментальнішу величину, ніж деякі інші властивості в теорії інформаціїї[11] (такі як власна інформація та шеннонова ентропія), що для не дискретних ймовірностей можуть ставати невизначеними або від'ємними.





- Розходження Кульбака — Лейблера є адитивним для незалежних розподілів практично так само, як і шеннонова ентропія. Якщо є незалежними розподілами, зі спільним розподілом , і аналогічно, то




- Розходження Кульбака — Лейблера є опуклим в парі функцій маси ймовірності , тобто, якщо та є двома парами функцій маси ймовірності, то




Приклади
Багатовимірні нормальні розподіли
Припустімо, що ми маємо два багатовимірні нормальні розподіли з середніми та з (невиродженими) коваріаційними матрицями Якщо ці два розподіли мають однакову розмірність, , то розходження Кульбака — Лейблера між ними є таким:[12]




Логарифм в крайньому члені мусить братися за основою e, оскільки всі члени, крім крайнього, є логарифмами за основою e виразів, що є або коефіцієнтами функції густини, або інакше виникають натурально. Тож це рівняння дає результат, вимірюваний в натах. Ділення всього наведеного вище виразу на дає розходження в бітах.

Особливим випадком, що є широко вживаною величиною у варіаційному висновуванні, є КЛ-розходження між діагональним багатовимірним нормальним, та стандартним нормальним розподілами:

Відношення до метрик
Можна було би спокуситися назвати розходження Кульбака — Лейблера «метрикою відстані» на просторі розподілів імовірності, але це не буде правильним, оскільки воно не є симетричним, тобто, , як і не задовольняє воно нерівність трикутника. Незважаючи на це, будучи дометрикою, воно породжує топологію на просторі розподілів імовірності. Конкретніше, якщо є послідовністю розподілів, такою, що



то кажуть, що

З нерівності Прінскера випливає, що

де крайнє відповідає звичайній збіжності в повній варіації.
Далі Реньї (1970, 1961)[13][14]
Інформаційна метрика Фішера
Розходження Кульбака — Лейблера є безпосередньо пов'язаним з інформаційною метрикою Фішера. Це можна зробити явним наступним чином. Припустімо, що обидва розподіли ймовірності та параметризовано деяким (можливо, багатовимірним) параметром . Розгляньмо тоді два близькі значення та , такі, що параметр відрізняється лише на невелику величину від значення параметру . Конкретно, до першого порядку матимемо (із застосуванням ейнштейнового запису підсумовування)





де є невеличкою зміною в напрямку , а є відповідним темпом зміни в розподілі ймовірності. Оскільки розходження Кульбака — Лейблера має нульовий абсолютний мінімум для , тобто, , воно змінюється в маленьких параметрах лише до другого порядку. Формальніше, як і для будь-якого мінімуму, перша похідна цього розходження зникає






і за розкладом Тейлора маємо до другого порядку

де матриця Гессе розходження

мусить бути додатно напівозначеною. Якщо дозволити змінюватися (й опустити підіндекс 0), то гессіан визначатиме (можливо, вироджену) ріманову метрику на просторі параметру θ, що називають інформаційною метрикою Фішера.

Теорема інформаційної метрики Фішера
Коли задовольняє наступні нормативні умови:

- існують,


де ξ є незалежною від ρ

тоді

Відношення до інших величин теорії інформації
Багато інших величин теорії інформації можливо інтерпретувати як застосування розходження Кульбака — Лейблера до особливих випадків.
Власна інформація
Власну інформацію, відому також як інформаційний вміст сигналу, випадкової змінної або події, означено як від'ємний логарифм імовірності трапляння заданого результату.
При застосуванні до дискретної випадкової змінної власну інформацію може бути представлено як[джерело?]

є розходженням Кульбака — Лейблера розподілу ймовірності від дельти Кронекера, що представляє впевненість, що — тобто, число додаткових біт, що мусить бути передано, щоби ідентифікувати , якби отримувачеві був доступним розподіл імовірності , а не той факт, що .



Взаємна інформація
Взаємна інформація[джерело?]

є розходженням Кульбака — Лейблера добутку двох розподілів відособлених ймовірностей від спільного розподілу ймовірності — тобто, математичним сподіванням числа бітів, яке мусить бути передано, щоби ідентифікувати та , якщо їх кодовано із застосуванням лише їхніх відособлених розподілів замість спільного розподілу. Рівнозначно, якщо спільна ймовірність є відомою, то це є математичним сподіванням числа додаткових бітів, які мусить бути в середньому надіслано, щоби ідентифікувати , якщо значення ще не є відомим отримувачеві.



Шеннонова ентропія
Шеннонова ентропія[джерело?]

є числом бітів, які мало би бути передано, щоби ідентифікувати з однаково ймовірних можливостей, меншим розходженням Кульбака — Лейблера рівномірного розподілу випадкових варіат , , від істинного розподілу — тобто, меншим за математичне сподівання числа заощаджених бітів, які мало би бути передано, якби значення було закодовано відповідно до рівномірного розподілу замість істинного розподілу .



Умовна ентропія
Умовна ентропія[джерело?]

є числом бітів, які мало би бути передано, щоби ідентифікувати з однаково ймовірних можливостей, меншим розходженням Кульбака — Лейблера добутку розподілів від істинного спільного розподілу — тобто, меншим за математичне сподівання числа заощаджених бітів, які мало би бути передано, якби значення було кодовано відповідно до рівномірного розподілу замість умовного розподілу змінної за заданого значення .


Перехресна ентропія
Перехресна ентропія між двома розподілами ймовірності вимірює усереднене числом бітів, необхідних, щоби ідентифікувати подію з набору можливостей, якщо застосовувана схема кодування ґрунтується на заданому розподілі ймовірності замість «істинного» розподілу . Відтак, перехресну ентропію двох розподілів та над одним і тим же ймовірнісним простором означено наступним чином:[джерело?]

Баєсове уточнювання
У баєсовій статистиці розходження Кульбака — Лейблера можливо застосовувати як міру приросту інформації при переході від апріорного розподілу до апостеріорного розподілу: . Якщо виявлено деякий новий факт , його може бути використано, щоби уточнити апостеріорний розподіл для з до нового апостеріорного розподілу із застосуванням теореми Баєса:





Цей розподіл має нову ентропію:

яка може бути меншою або більшою за первинну ентропію . Проте, з точки зору нового розподілу ймовірності, можливо оцінити, що застосування первинного коду на основі замість нового коду на основі додало би таке очікуване число бітів


до довжини повідомлення. Воно відтак представляє величину корисної інформації, або приріст інформації, про , що за нашою оцінкою ми дізналися, виявивши .
Якщо потім надходять подальші дані, , то розподіл імовірності для може бути уточнено далі, щоби дати нове найкраще припущення . Якщо повторно дослідити приріст інформації для застосування замість , то виявиться, що він може бути як більшим, так і меншим за оцінений минулого разу:



- може бути ≤ або > за


і, таким чином, об'єднаний приріст інформації не підкоряється нерівності трикутника:
- може бути <, = або > за


Все, що можливо сказати, це що в середньому при усереднюванні із застосуванням ці дві сторони будуть приблизно рівними.

Баєсове планування експериментів
Поширеною метою в баєсовім плануванні експериментів є максимізувати математичне сподівання розходження Кульбака — Лейблера між апріорним та апостеріорним.[15] Коли апостеріорні наближено вважають нормальними розподілами, то план, що максимізує математичне сподівання розходження Кульбака — Лейблера, називають баєсовим d-оптимальним.
Розрізнювальна інформація
Розходження Кульбака — Лейблера можливо також розглядати як очікувану розрі́знювальну інформа́цію (англ. discrimination information) для над : середню інформацію на зразок для розрізнення на користь гіпотези проти гіпотези , коли гіпотеза є істинною.[16] Іншою назвою цієї величини, даною їй І. Дж. Ґудом, є очікувана вага свідчення для над , якої варто чекати від кожного зразка.



Очікувана вага свідчення для над не є тим же, що й приріст інформації про розподіл імовірності цих гіпотез, очікуваний на зразок,


Як функцію корисності в баєсовім плануванні експерименту, щоби обирати оптимальне наступне питання для дослідження, можливо використовувати будь-яку з цих двох величин, але вони загалом вестимуть до дещо різних стратегій експериментування.
На ентропійній шкалі приросту інформації різниця між майже впевненістю та абсолютною впевненістю є дуже маленькою — кодування відповідно до майже впевненості вимагає заледве більше бітів, ніж кодування відповідно до впевненості абсолютної. З іншого боку, на логіт-шкалі, що випливає з ваги свідчення, різниця між цими двома є величезною — можливо, нескінченною; це може віддзеркалювати різницю між тим, щоби бути майже впевненими (на ймовірнісному рівні), що, скажімо, гіпотеза Рімана є правильною, в порівнянні з тим, щоби бути впевненими в її правильності, оскільки вона має математичне доведення. Ці дві різні шкали функції втрат для невизначеності є корисними обидві, відповідно до того, наскільки добре кожна з них віддзеркалює певні обставини задачі, що розглядають.
Принцип мінімальної розрізнювальної інформації
Ідея розходження Кульбака — Лейблера як розрізнювальної інформації привела Кульбака до пропозиції принципу мініма́льної розрі́знювальної інформа́ції (МРІ, англ. Minimum Discrimination Information, MDI): за наявності нових фактів повинно бути обрано новий розподіл , що є якомога важче розрізнити від первинного розподілу ; так що нові дані продукують якомога менший приріст інформації .



Наприклад, якщо був апріорний розподіл над та , і згодом дізналися, що істинним розподілом був , то розходженням Кульбака — Лейблера між новим спільним розподілом для та , , та ранішим апріорним розподілом, буде





тобто, сума розходження Кульбака — Лейблера , апріорного розподілу , від уточненого розподілу , та математичного сподівання (із застосуванням розподілу ймовірності ) розходження Кульбака — Лейблера апріорного умовного розподілу від нового умовного розподілу . (Зауважте, що крайнє математичне сподівання часто називають умовним розходженням Кульбака — Лейблера, англ. conditional Kullback–Leibler divergence, (або умовною відносною ентропією, англ. conditional relative entropy), і позначують [17]) Вона мінімізується, якщо над усім носієм ; і зауважмо, що цей результат включає теорему Баєса, якщо новий розподіл є фактично δ-функцією, що представляє впевненість у тім, що має одне певне значення.





МРІ можливо розглядати як розширення принципу недостатнього обґрунтування Лапласа, та принципу максимальної ентропії Е. Т. Джейнса. Зокрема, вона є природним розширенням принципу максимальної ентропії з дискретних на неперервні розподіли, для яких шеннонова ентропія перестає бути настільки корисною (див. диференціальну ентропію), але розходження Кульбака — Лейблера залишається настільки ж відповідним.
В інженерній літературі МРІ іноді називають принципом мінімальної перехресної ентропії (МПЕ, англ. Principle of Minimum Cross-Entropy, MCE), або, для скорочення, англ. Minxent. Мінімізування розходження Кульбака — Лейблера від до по відношенню до є рівнозначним мінімізуванню перехресної ентропії та , оскільки


що є доречним, якщо намагатися обрати адекватне наближення . Проте так же часто це й не є завданням, якого намагаються досягти. Натомість, так же часто це є деякою незмінною апріорною орієнтирною мірою, а є тим, що намагаються оптимізувати, мінімізуючи за деякого обмеження. Це призвело до деякої неоднозначності в літературі, і деякі автори намагаються розв'язати цю невідповідність, переозначуючи перехресну ентропію як замість .


Відношення до доступної роботи

Коли ймовірності перемножуються, несподіваності додаються.[18] Несподіваність для події з імовірністю означено як . Якщо є , то несподіваність є в натах, бітах, або , так що, наприклад, у випадінні всіх аверсів при підкиданні монет є бітів несподіваності.




Найкращі припущення про стан (наприклад, для атомів у газі) виводять максимізуванням усередненої несподіваності (англ. average surprisal) (ентропії) для заданого набору контрольних параметрів (таких як тиск чи об'єм ). Це обмежене максимізування ентропії, як класично,[19] так і квантово-механічно,[20] мінімізує ґіббзову доступність в одиницях ентропії[21] , де є обмеженою вкладеністю або статистичною сумою.




Коли температура є фіксованою, вільна енергія () також мінімізується. Таким чином, якщо та число молекул є сталими, то вільна енергія Гельмгольца (де є енергією) мінімізується, коли система «врівноважується». Якщо та утримуються сталими (скажімо, під час процесів у вашому тілі), то натомість мінімізується вільна енергія Ґіббза . Зміна у вільній енергії за цих умов є мірою доступної роботи, яку могло би бути виконано в цьому процесі. Таким чином, доступною роботою для ідеального газу за сталої температури та тиску є , де та (див. також нерівність Ґіббза).










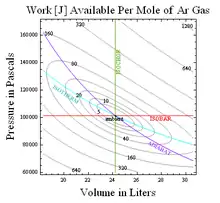
Загальніше,[22] доступну роботу відносно деяких нормальних умов отримують множенням нормальної температури на розходження Кульбака — Лейблера або чисту несподіваність (англ. net surprisal) означену як усереднене значення , де є ймовірністю заданого стану за нормальних умов. Наприклад, доступною роботою у врівноважуванні одноатомного ідеального газу до нормальних значень та відтак є , де розходження Кульбака — Лейблера






Отримані в результаті контури сталого розходження Кульбака — Лейблера для одного молю аргону за стандартної температури та тиску, показані праворуч, наприклад, встановлюють межі для перетворення гарячого на холодне, як у кондиціюванні повітря із застосуванням полум'я, або в пристрої без живлення для перетворення окропу на крижану воду, обговорених тут.[23] Таким чином розходження Кульбака — Лейблера вимірює термодинамічну доступність в бітах.
Квантова теорія інформації
Для матриць густини та на гільбертовім просторі КЛ-розходження (або квантову відносну ентропію, як його часто називають у цьому випадку) від до означено як

У квантовій інформатиці мінімум над усіма окремими станами можливо також використовувати як міру заплутаності в стані .
Відношення між моделями та дійсністю
Подібно до того, як розходження Кульбака — Лейблера «чинного від нормального» вимірює термодинамічну доступність, розходження Кульбака — Лейблера «дійсності від моделі» є також корисним, навіть якщо єдиними підказками про дійсність, що ми маємо, є деякі експериментальні вимірювання. В першому випадку розходження Кульбака — Лейблера описує відстань до рівноіваги, або (будучи домноженим на нормальну температуру) величину доступної роботи, тоді як у другому випадку воно каже про несподіванки, що заховала дійсність у своєму рукаві, або, іншим словами, скільки модель ще має вчитися.
Хоча цей інструмент для оцінювання моделей відносно систем, що є доступними експериментально, можна застосовувати в будь-якій галузі, його застосування для обирання статистичної моделі через інформаційний критерій Акаіке описано особливо добре в працях[24] та книзі[25] Бернема та Андерсона. У двох словах, розходження Кульбака — Лейблера дійсності від моделі можна оцінювати з точністю до сталого адитивного члену функцією (такою як підсумовані квадрати) відхилень, що спостерігаються між даними та прогнозами моделі. Оцінки таких розходжень для моделей, що поділяють спільний адитивний член, можливо своєю чергою використовувати для здійснення вибору серед моделей.
Існують різноманітні оцінювачі, які намагаються мінімізувати розходження Кульбака — Лейблера при намаганні пристосовувати параметризовані моделі, такі як максимально-правдоподібнісні та максимально-інтервальні оцінювачі.
Усиметрене розходження
Самі Кульбак та Лейблер насправді означили це розходження як:

що є симетричним та невід'ємним. Цю величину іноді використовували для обирання ознак у задачах класифікації, де та є умовними ФГІ ознаки за двох різних випадків.
Альтернатива дається через -розходження,


яке можливо інтерпретувати як очікуваний приріст інформації про від виявлення того, з якого розподілу вибирається , з чи з , якщо вони поточно мають імовірності та відповідно.[прояснити] [джерело?]

Значення дає розходження Єнсена — Шеннона, означене як


де є усередненням цих двох розподілів,


також можливо інтерпретувати як ємність зашумленого інформаційного каналу з двома входами, що дають виходові розподіли та . Розходження Єнсена — Шеннона, як і всі f-розходження, є локально пропорційним до фішерової інформаційної метрики. Воно є подібним до хелінґерової метрики (в тому сенсі, що воно зумовлює такий самий афінний зв'язок на статистичному многовиді).

Відношення до інших мір імовірнісної відстані
Існує багато інших важливих мір ймовірнісної відстані. Деякі з них є особливо пов'язаними з розходженням Кульбака — Лейблера. Наприклад:
- Повно-варіаційна відстань, . Вона є пов'язаною з цим розходженням через нерівність Прінскера:
- Сімейство розходжень Реньї забезпечує узагальнення розходження Кульбака — Лейблера. Залежно від значення певного параметру, , може бути виведено різноманітні нерівності.



До інших примітних мір відстані належать хелінґерова відстань, перетин гістограм (англ. histogram intersection), хі-квадратова статистика, відстань квадратичного вигляду (англ. quadratic form distance), збігова відстань, відстань Колмогорова — Смирнова та бульдозерна відстань.[26]
Віднімання даних
Детальніші відомості з цієї теми ви можете знайти в статті Віднімання даних.
Так само, як абсолютна ентропія слугує теоретичною основою для стискання даних, відносна ентрпоія слугує теоретичною основою для віднімання даних — де абсолютна ентропія набору даних в цьому сенсі є даними, необхідними для його відтворення (мінімальний стиснений розмір), в той час як відносна ентропія цільового набору даних за заданого первинного набору даних є даними, необхідними для відтворення цільового за заданого первинного (мінімальний розмір латки).
Див. також
- Баєсів інформаційний критерій
- Брегманове розходження
- Ентропійна ризикована вартість
- Інформаційний критерій Акаіке
- Інформаційний критерій відхилення
- Квантова відносна ентропія
- Коефіцієнт приросту інформації
- Нерівність ентропійної потужності
- Перехресна ентропія
- Приріст інформації в деревах рішень
- Розходження Єнсена — Шеннона
- Соломон Кульбак та Річард Лейблер
- Теорія інформації та теорія міри
- Ентропія Реньї
Примітки
- Kullback, S.; Leibler, R.A. (1951). On information and sufficiency. Annals of Mathematical Statistics 22 (1): 79–86. MR 39968. doi:10.1214/aoms/1177729694. (англ.)
- Kullback, S. (1959). Information Theory and Statistics. John Wiley & Sons.. Republished by Dover Publications in 1968; reprinted in 1978: ISBN 0-8446-5625-9. (англ.)
- Kullback, S. (1987). Letter to the Editor: The Kullback–Leibler distance. The American Statistician 41 (4): 340–341. JSTOR 2684769. doi:10.1080/00031305.1987.10475510. (англ.)
- MacKay, David J.C. (2003). Information Theory, Inference, and Learning Algorithms (вид. First). Cambridge University Press. с. 34. (англ.)
- Bishop C. (2006). Pattern Recognition and Machine Learning (англ.)
- Burnham, K. P.; Anderson, D. R. (2002). Model Selection and Multi-Model Inference (вид. 2nd). Springer. с. 51. (англ.)
- Hobson, Arthur (1971). Concepts in statistical mechanics. New York: Gordon and Breach. ISBN 0677032404. (англ.)
- Baez, John; Fritz, Tobias (2014). A Bayesian characterization of relative entropy. Theory and Application of Categories 29: 421–456. Проігноровано невідомий параметр
|eprint=(довідка) (англ.) - Sanov, I.N. (1957). On the probability of large deviations of random magnitudes. Matem. Sbornik 42 (84): 11–44. (англ.)
- Novak S.Y. (2011), Extreme Value Methods with Applications to Finance ch. 14.5 (Chapman & Hall). ISBN 978-1-4398-3574-6. (англ.)
- Див. розділ «differential entropy – 4» у відео-лекції Серхіо Верду «Relative Entropy» з NIPS 2009 (англ.)
- Duchi J., "Derivations for Linear Algebra and Optimization", (англ.)
- Rényi A. (1970). Probability Theory. Elsevier. Appendix, Sec.4. ISBN 0-486-45867-9. (англ.)
- Rényi, A. (1961). On measures of entropy and information. Proceedings of the 4th Berkeley Symposium on Mathematics, Statistics and Probability 1960. с. 547–561. (англ.)
- Chaloner, K.; Verdinelli, I. (1995). Bayesian experimental design: a review. Statistical Science 10 (3): 273–304. doi:10.1214/ss/1177009939. (англ.)
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. (2007). Section 14.7.2. Kullback–Leibler Distance. Numerical Recipes: The Art of Scientific Computing (вид. 3rd). Cambridge University Press. ISBN 978-0-521-88068-8. (англ.)
- Thomas M. Cover, Joy A. Thomas (1991) Elements of Information Theory (John Wiley & Sons) (англ.)
- Myron Tribus (1961), Thermodynamics and Thermostatics (D. Van Nostrand, New York) (англ.)
- Jaynes, E. T. (1957). Information theory and statistical mechanics. Physical Review 106: 620–630. Bibcode:1957PhRv..106..620J. doi:10.1103/physrev.106.620. (англ.)
- Jaynes, E. T. (1957). Information theory and statistical mechanics II. Physical Review 108: 171–190. Bibcode:1957PhRv..108..171J. doi:10.1103/physrev.108.171. (англ.)
- J.W. Gibbs (1873), "A method of geometrical representation of thermodynamic properties of substances by means of surfaces", reprinted in The Collected Works of J. W. Gibbs, Volume I Thermodynamics, ed. W. R. Longley and R. G. Van Name (New York: Longmans, Green, 1931) footnote page 52. (англ.)
- Tribus, M.; McIrvine, E. C. (1971). Energy and information. Scientific American 224: 179–186. Bibcode:1971SciAm.225c.179T. doi:10.1038/scientificamerican0971-179. (англ.)
- Fraundorf, P. (2007). Thermal roots of correlation-based complexity. Complexity 13 (3): 18–26. Bibcode:2008Cmplx..13c..18F. arXiv:1103.2481. doi:10.1002/cplx.20195.[недоступне посилання з квітня 2019] (англ.)
- Burnham, K.P.; Anderson, D.R. (2001). Kullback–Leibler information as a basis for strong inference in ecological studies. Wildlife Research 28: 111–119. doi:10.1071/WR99107. (англ.)
- Burnham, K. P. and Anderson D. R. (2002), Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach, Second Edition (Springer Science) ISBN 978-0-387-95364-9. (англ.)
- Rubner, Y.; Tomasi, C.; Guibas, L. J. (2000). The earth mover's distance as a metric for image retrieval. International Journal of Computer Vision 40 (2): 99–121. (англ.)
Посилання
- Information Theoretical Estimators Toolbox
- «Камінчик» Ruby для обчислення розходження Кульбака — Лейблера
- Посібник Йона Шленза з розходження Кульбака — Лейблера та теорії правдоподібності (англ.)
- Код Matlab для обчислення розходження Кульбака — Лейблера для дискретних розподілів
- Серхіо Верду, Відносна ентропія, NIPS 2009. Одногодинна відеолекція. (англ.)
- Сучасне резюме теоретико-інформаційних мір розходження (англ.)