Семантична мережа
Семантична мережа — інформаційна модель предметної області, що має вигляд орієнтованого графу, вершини якого відповідають об'єктам предметної області, а ребра задають відносини між ними. Об'єктами можуть бути поняття, події, властивості, процеси[1].
| Наука про мережі | ||||
|---|---|---|---|---|
|
||||
| Види мереж | ||||
|
||||
| Графи | ||||
|
||||
| ||||
|
||||
| Моделі | ||||
|
||||
| ||||
|
||||
Таким чином, семантична мережа є одним із способів представлення знань.
У назві сполучені терміни з двох наук: семантика у мовознавстві вивчає сенс одиниць мови, а мережа в математиці є різновидом графу — набору вершин, сполучених дугами (ребрами). У семантичній мережі роль вершин виконують поняття бази знань, а дуги (причому направлені) задають відношення між ними. Таким чином, семантична мережа відображає семантику предметної області у вигляді понять і відносин між ними.
У комп'ютері вершинам, або вузлам, графу відповідають групи комірок пам'яті, а зв'язкам — вказівки, що містять коди адрес пам'яті, завдяки чому програма знаходить потрібні комірки. Найважливіші зв'язки — типу «Це є»: вони дозволяють побудувати в мережі ієрархію понять, в якій вузли нижчих рівнів успадковують властивості вузлів вищих рівнів. Таким механізмом перенесення зумовлена ефективність семантичних мереж[2].
У жодному випадку не можна змішувати поняття «Семантична мережа» (англ. semantic Network) і «Семантична павутина» (англ. semantic Web). Ця невідповідність виникає якраз через неточний переклад. Хоча ці поняття не еквівалентні, проте, вони пов'язані (див. нижче).
Історія
Ідея систематизації на основі яких-небудь семантичних відносин пропонувалася ще ученими ранньої науки. Прикладом цього може служити біологічна систематика Карла Ліннея 1735 р. Якщо розглядати її як семантичну мережу, то в даній класифікації використовується відношення підмножини, сучасне AKO.
Пращурами сучасних семантичних мереж можна вважати екзистенціальні графи, запропоновані Чарльзом Пірсом в 1909 г. Вони використовувалися для представлення логічних висловів у вигляді особливих діаграм. Пірс назвав цей спосіб «логікою майбутнього».
Важливим почином в дослідженні мереж стали роботи німецького психолога Отто Сальтисона 1913 і 1922 рр. В них, для організації структур понять і асоціацій, а також вивчення методів спадкоємства властивостей було використано графи і семантичні відносини. Дослідники дж. Андерсон (1973), д. Норман (1975) та інші використовували ці роботи для моделювання пам'яті людини та її інтелектуальних можливостей.
Комп'ютерні семантичні мережі були детально розроблені Річардом Річенсом в 1956 році в рамках проекту кембріджського центру вивчення мови з машинного перекладу. Процес машинного перекладу підрозділяється на 2 частини: переклад початкового тексту в проміжну форму представлення, а потім ця проміжна форма перекладається на потрібну мову. Такою проміжною формою якраз і були семантичні мережі. У 1961 р. з'явилася робота Мастермана, в якій він, зокрема, визначав базовий словник для 15000 понять. Ці дослідження були продовжені Робертом Симмонсом (1966), Уїлксом (1972) та іншими вченими.
Великий інтерес представляє робота Куїлліана (1967 р.).
Структура
Математика дозволяє описати більшість явищ у навколишньому світі у вигляді логічних висловів. Семантичні мережі виникли як спроба візуалізації математичних формул. Основним способом представлення для семантичної мережі є граф. Проте не варто забувати, що за графічним зображенням неодмінно стоїть строгий математичний запис, і що обидві ці форми є такими, що не конкурують, а доповнюють одна одну.
Графічне представлення
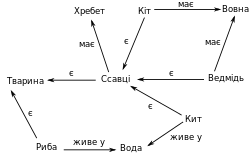
Основною формою представлення семантичної мережі є граф. Поняття семантичної мережі записуються в овалах або прямокутниках і з'єднуються стрілками з підписами — дугами (див. мал.). Це найзручніша форма, яка сприймається людиною.[джерело?] Її недоліки виявляються, коли ми починаємо будувати складніші мережі або намагаємося врахувати особливості природної мови.
Математичний запис
У математиці граф представляється множиною вершин V і множиною відносин між ними E. Використовуючи апарат математичної логіки, приходимо до висновку, що кожна вершина відповідає елементу предметної множини, а дуга — предикату.
Класифікація семантичних мереж
Для всіх семантичних мереж справедливе розділення за арністю і кількістю типів відносин.
За кількістю типів, мережі можуть бути однорідними і неоднорідними. Однорідні мережі мають тільки один тип відносин (стрілок), наприклад, такою є вищезазначена класифікація біологічних видів (з єдиним відношенням AKO). У неоднорідних мережах кількість типів відносин більше двох. Класичні ілюстрації даної моделі представлення знань представляють саме такі мережі. Неоднорідні мережі представляють більший інтерес для практичних цілей, але і більшу складність для досліджень.
За арністю, типовими є мережі з бінарними відносинами (що зв'язують рівно два поняття). Бінарні відносини, дійсно, є простими й зручно виглядають на графі у вигляді стрілки між двома поняттями. Крім того, вони відіграють виняткову роль у математиці. На практиці, проте, можуть знадобитися відносини, що зв'язують більше двох об'єктів, — N-арні. При цьому виникає складність — як відобразити подібний зв'язок на графі, щоб не заплутатися. Концептуальні графи (див. нижче) знімають це ускладнення, представляючи кожне відношення у вигляді окремого вузла.
Крім концептуальних графів існують інші модифікації семантичних мереж, це є ще однією основою для класифікації (за реалізацією). Див. детальніше у відповідному розділі нижче.
Семантичні відносини
Кількість типів відносин в семантичній мережі визначається її розробником, виходячи з конкретних цілей. В реальному світі їхня кількість прямує до нескінченності. Кожне відношення є, по суті, предикатом, простим або складним. Швидкість роботи з базою знань залежить від того, наскільки ефективно зроблені програми обробки потрібних відносин.
Ієрархічні
Найчастіше виникає потреба в описі відносин між елементами, множинами і частинами об'єктів. Відношення між об'єктом і множиною, що позначає, що об'єкт належить цій множині, називається відношенням класифікації (ISA). Говорять, що множина (клас) класифікує свої екземпляри.[3] Назва походить від англійського «IS A». Іноді це відношення іменують також MemberOf або якось подібно. Зв'язок ISA припускає, що властивості об'єкта успадковуються від множини. Зворотне до ISA відношення використовується для позначення прикладів, тому так і називається — «Example», або українською «Наприклад».
Відношення між надмножиною і підмножиною називається AKO — «A Kind Of» («різновид»). Елемент підмножини називається гипонімом, а надмножини — гиперонімом, а саме відношення називається відношенням гипонімії. Альтернативні назви — «SubsetOf» і «Підмножина». Це відношення визначає, що кожен елемент першої множини входить і в друге (виконується ISA для кожного елементу), а також логічний зв'язок між самими підмножинами: що перше не більше другого і властивості першої множини успадковуються другою.
Об'єкт, зазвичай, складається з декількох частин, або елементів. Наприклад, комп'ютер складається з системного блоку, монітора, клавіатури, миші і т. д. Важливим відношенням є HasPart, що описує частини/складові об'єкти (відношення меронімії). меронім — це об'єкт, що є частиною іншого. Двигун — це меронім для автомобіля. холонім — це об'єкт, який влючаєт в себе інше. Наприклад, біля будинку є дах. будинок — холонім для даху. Комп'ютер — холонім для монітора. Меронім і холонім — протилежні поняття.
Часто в семантичних мережах потрібно визначити відносини синонімії і антонімії. Ці зв'язки або дублюються явно в самій мережі, або в алгоритмічній складовій.
Допоміжні
У семантичних мережах часто використовуються також такі відношення [Гаврилова]:[джерело?]
- функціональні зв'язки (визначені, зазвичай, дієсловами «виготовляє», «впливає».);
- кількісні (більше менше, рівно.);
- просторові (далеко від, близько від, за, під, над…);
- тимчасові (раніше, пізніше, під час);
- атрибутивні (мати властивість, мати значення);
- логічні (ТАК, АБО, НІ);
- лінгвістичні.
Цей список може скільки завгодно продовжуватися: в дійсності кількість відносин величезна. Наприклад, між поняттями може використовуватися відношення «абсолютно різні речі» або подібне: не_мають_відношення_між_собою(Сонце, Кухонний_чайник) .
Використання семантичних мереж
Семантична павутина
Концепція організації гіпертексту нагадує однорідну бінарну семантичну мережу, проте тут є істотна відмінність:
- Зв'язок, здійснюваний гіперпосиланням, не має семантики, тобто, не описує сенсу цього зв'язку. Призначення семантичної мережі полягає в тому, щоб описати взаємозв'язки об'єктів, а не додаткову інформацію щодо предметної області. Людина може розібратися, навіщо потрібне те або інше гіперпосилання, але комп'ютеру цей зв'язок не зрозумілий.
- Сторінки, що зв'язуються гіперпосиланнями, є документами, що описують, як правило, проблемну ситуацію в цілому. У семантичній мережі вершини (ті, що зв'язують відносини) є поняття або об'єкти реального світу.
Спроба створення семантичної мережі на основі всесвітньої павутини отримала назву семантичної павутини. Ця концепція має на увазі використання мови RDF (мови розмітки на основі XML) і покликана додати посиланням якийсь сенс, зрозумілий комп'ютерним системам. Це дозволить перетворити Інтернет на розподілену базу знань глобального масштабу.
Майбутнє семантичних мереж
Починаючи з 50-х років минулого століття, семантичні мережі почали активно досліджувати все більше і більше. Першопочатковим призначенням та метою створення семантичних мереж була роль посередництва між людською мовою та системами машинного перекладу, але з плином часу задачі доповнювалися та ускладнювалися, чим викликають інтерес до себе в сьогоденні та викликатимуть його й надалі. Серед основних досліджуваних перспективних, але в той же час і проблемних напрямків розвитку у даній галузі можна виділити наступні:
- задача штучного інтелекту для морфологічного аналізу текстів — задача, що має на меті вирішення проблеми комп'ютерного аналізу текстів на основі аналогій та порівнянь;
- задача створення глобальної семантичної павутини — задача, що повинна вирішити проблему представлення всесвітньо-глобальної інформації у вигляді зрозумілому для машинної обробки та пошуку;
- задача створення онтологій для освіти та створення концепцій для навчальних Internet-систем.
Задача штучного інтелекту для морфологічного аналізу текстів
- В основі розв'язку даної задачі лежить представлення значення тексту у формі асоціативної семантичної мережі, у яку потрапляють найбільш вживані слова цього тексту, тобто несуть інформаційний зміст. Для кожного значення, що потрапляє у семантичну мережу будується асоціативні зв'язки — із іншими смисловими значеннями для котрих зустрічалося поточне значення, чим частіше значення потрапляють у семантичну мережу, тим більша ймовірність їхньої зв'язності по змісту.
У роботі[4] описано принципи побудови алгоритмів морфологічного аналізу текстів базуючись на основі принципу аналогій. Цей алгоритм ґрунтується на орфографічному контролі та автоматичному індексуванні документів. Основною проблемою, що змушує задумуватися науковців, є наявність нових, незрозумілих машині слів у тексті. Тобто у словнику системи відсутні множина деяких слів, в результаті чого система, що базується на принципі аналогій, не в змозі здійснити синтаксичний аналіз таких слів, а як наслідок робить неможливим знаходження розв'язку задачі пошуку граматичного значення слова. Описана вище проблема є досить актуальною на сьогоднішній день, вона унеможливлює знаходження повного вирішення задачі морфологічного аналізу текстів. Починаючи із 1978 року і по сьогоднішній день науковці намагаються знайти рішення цієї проблеми. Так у 1978 Перейрой (Pereira) та Уорренс(D. Uorren) запропонували для вирішення задачі граматичного розбору використати логічну мову PROLOG[5]. Було розроблено ряд систем, що мали на меті віднайти рішення цієї проблеми, але кожна система володіла рядом недоліків і, як наслідок, жодній із них так і не вдалося в повній мірі реалізувати вирішення проблеми.
Таким чином розвиток семантичних мереж у майбутньому дозволив би нам вирішити ці проблеми і допоміг би аналітикам знайти рішення для ряду задач, серед яких:
- пошук у документах прихованих зв'язків між об'єктами — темами, пошук споріднених документів, що відповідають певній тематиці;
- пошук нових інформаційних джерел, пов'язаних із конкретною об'єктною темою, виявлення асоціативних зв'язків, що зв'язують дану об'єктну тему;
- пошук певного конкретного тематичного змісту у цілій колекції документів, що дозволить фокусуватися лише на тих темах із множини, які є спорідненими із базовою тематикою.
- Задача створення всесвітньо глобальної семантичної павутини виникла у середині 90-х років минулого століття. Дана задача мала і має на меті перетворення глобальної гіпертекстової мережі у єдину та унікальну семантичну систему, що отримала б назву «Семантична павутина» або «Семантичний Web».
Ідея створення семантичної павутини
Основна ідея створення семантичної павутини полягає в тому, що, на відмінну від існуючої гіпертекстової мережі, яку обробляє людина, семантична глобальна мережа майбутнього повинна б була представити інформацію таким чином, щоб її можна було обробляти автоматично без втручання людини. Як відомо існуюча на сьогоднішній день глобальна павутина базується на інформації представленій гіпертекстовою мовою розмітки і представляється людині через спеціально розроблені для цього засоби, зокрема браузери. На зміну цьому старому підходу, семантична павутина покликана представити наявну на сьогоднішній день інформацію у формі семантичних мереж, використовуючи при цьому, як сказано у статті[6], формалізацію областей знань з допомогою концептуальних схем, що в свою чергу складається із структур даних (об'єктів, зв'язків між ними і правил), прийнятих у даній області.
- Першовідкривачем та засновником поняття семантичної павутини був Тім Бернерс-Лі (Berners-Lee T). Так у 2001 році була опублікована його стаття, що носила назву «Наступний крок у розвитку Всесвітньої павутини». Тім Бернерс-Лі запропонував створити надбудову до існуючої глобальної мережі, яка б перетворила існуючі дані у такий спосіб, щоб ці дані стали зрозумілими комп'ютерам. Як засіб вирішення даної задачі було запропоновано стандарт RDF (Resource Definition Framework) та RDFS (RDF Schema).
RDF специфікація передбачає створення деякої множини ресурсів, для яких визначаються зв'язки значення — властивість. Ці ресурси ідентифікуються у Web за допомогою спеціальних ідентифікаторів URI. По великому рахунку RDF семантика повинна визначати онтологію конкретної предметної області. Саме онтологія з кожним роком завойовує все ширше і ширше застосування у розв'язку задачі представлення знань, семантичної адаптації інформаційних ресурсів та їх пошуку. Дана віха у розвитку специфікації концептуалізації предметної області є досить перспективною, також з її допомогою здійснюються спроби представлення ієрархічних понять. Прикладом застосування онтології у глобальній мережі є групування Web-сайтів по категоріях пошуковою системою Yahoo!, групування товарів за фізичними характеристиками у Internet магазинах. Поряд із розвитком Web технологій стрімко розвивається нова концепція — концепція соціальної семантичної павутини. Згідно з[7] соціальна семантична павутина — це гілка розвитку семантично павутини, що передбачає створення та існування семантично багатих знань (semantically rich knowledge). Таким чином на сьогоднішній день розвиваються такі мови, за допомогою яких можна представити знання, серед них можна виділити: RDFS, OWL Lite, OWL DL, OWL Full. Стрімкий розвиток соціальних мереж привів до накопичення величезною кількості людей у одному місці, які в свою чергу посприяли накопиченню великої кількості структурованих даних, що в викликало спробу створення спеціально інтелектуального агента — робота, що буде оперувати цією масою інформації.
Проблематика
- Хоча на сьогоднішній день ця ідея існує лише в теорії та на папері, але ближнім часом вона може перетворитися в реальність, адже стимул для розробки такого агента є досить великим, потенціал також немалий, ще й до того існує безліч служб, які б хотіли оперувати такою інформацією. Таким чином соціальні семантичні павутини це є комплекс технологій, підходів, принципів і методологій поєднуючи семантичні павутини, соціальні мережі та технологію Web.
Але попри великі перспективи та зацікавленість сторін існує ряд факторів, що пригнічують стрімкий розвиток семантичних павутин. Одним із таких факторів є практична нереалізовуваність. П'ять років після народження перспективної концепції, у 2006 році сам же її засновник Тім Бернерс-Лі видав публікацію «Semantic Web Revisited», у котрій висунув гіпотезу про те, що ідея семантичних павутин може існувати як повноцінна концепція, скоріше, лише в теорії. Проблема надлишковості та дублювання даних також відіграє пригнічуючу роль. Семантичні павутини передбачають існування двох дублікатів однієї і тієї ж інформації — одна зрозуміла машині (метадані), а інша людині (XML та HTML), інакше втрачається сенс створення цієї концепції. І останній, але найбільш суттєвий фактор — це відсутність вигоди для інвесторів. Оскільки основним засобом, що приносить прибуток в Internet, є реклама, а із розвитком семантичних павутин, користувачеві буде представлятися лише та інформація, яку він шукає, то, як наслідок, прибутковість реклами знизиться.
Приклади семантичних мереж
Див. також
Посилання
- Roussopoulos N.D. A semantic network model of data bases. — TR No 104, Department of Computer Science, University of Toronto, 1976.
- Субботін С. О. Подання й обробка знань у системах штучного інтелекту та підтримки прийняття рішень : Навчальний посібник. — Запоріжжя : ЗНТУ, 2008. — 341 с. Архів оригіналу за 7 жовтня 2009. Процитовано 7 жовтня 2009.
- http://www.rsdn.ru/article/patterns/oomethods.xml
- Белоногов Г. Г., Зеленков Ю. Г., Кузнецов Б. А., Новоселов А. П., Хорошилов Александр, др А., Хорошилов Алексейсей А. Автоматизация составления и ведения словарей для систем фразеологического машинного перевода текстов с русского языка на английский и с английского на русский. Сб. «Научно-техническая информация», Серия 2, № 12, ВИНИТИ, 1993 г.
- Pereira F., Warren D. Definite Clause Grammars for Language Analysis — a Survey of Formalism and Comparison with Augment Transition Networks // Artificial Intelligence. 1980. Vol. 13. P. 231—278.
- Gruber T.R. A translation approach to portable ontologies. // Knowledge acquisition. — 1993. — № 5 (2). — P. 199—220
- Социальный Semantic Web — Semantic Future http://semanticfuture.net/index.php?title=Semantic_Web 12.11.2010