Біноміальний розподіл
Дискретна випадкова величина ξ називається такою, що має біноміальний розподіл, якщо ймовірність набуття нею конкретних значень має вигляд: , де — параметри, що визначають розподіл, .



| Біноміальний розподіл | |
|---|---|
|
Функція ймовірностей 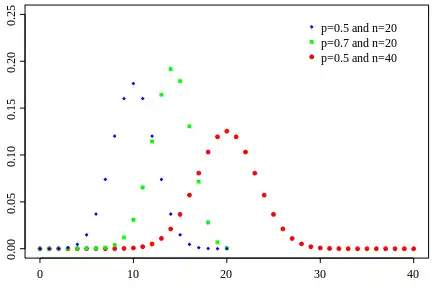 | |
|
Функція розподілу ймовірностей 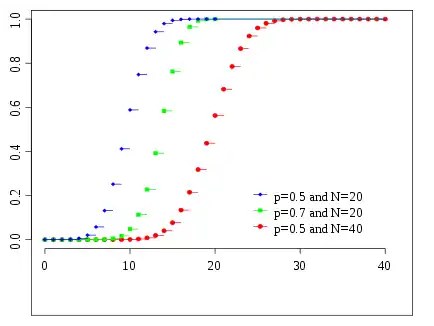 Кольори збігаються з попереднім малюнком | |
| Параметри |
кількість випробувань (ціле) ймовірність успіху (дійсне) |
| Носій функції | |
| Розподіл імовірностей | |
| Функція розподілу ймовірностей (cdf) | |
| Середнє | |
| Медіана | одне із [1] |
| Мода | |
| Дисперсія | |
| Коефіцієнт асиметрії | |
| Коефіцієнт ексцесу | |
| Ентропія | |
| Твірна функція моментів (mgf) | |
| Характеристична функція | |














Позначається .

Біноміальний розподіл є дискретним розподілом імовірностей із параметрами n і p для кількості успішних результатів, що мають двійкове значення у послідовності із n незалежних експериментів, для кожного з яких ставиться питання "так або ні". Імовірність виникнення успішного результату для кожного випробування задається параметром p, а імовірність виникнення не успішного результату відповідно дорівнюватиме q = 1 − p.
Єдиний успішний чи не успішний експеримент також називають випробуванням Бернуллі або експериментом Бернуллі, а послідовність результатів таких експериментів називаються процесом Бернуллі; для однократного випробування, тобто, при n = 1, біноміальний розподіл є розподілом Бернуллі. Біноміальний розподіл є основою загальновживаної біноміальної перевірки статистичної значущості.
Біноміальний розподіл часто використовують для моделювання кількості успішних експериментів у вибірці розміром в n, де експерименти виконуються із поповненням із сукупності розміром N. Якщо відбір вибірки відбуватиметься без поповнення, тоді такі експерименти не будуть незалежними і їх результатний розподіл буде гіпергеометричним, а не біноміальним. Однак, для випадку, коли N набагато більше за n, біноміальний розподіл використовують, оскільки він залишається добрим наближенням.
Пояснення
В теорії ймовірностей та математичній статистиці, біноміальний розподіл є дискретним ймовірнісним розподілом, що характеризує кількість успіхів в послідовності експериментів, значення яких змінюється за принципом так/ні, кожен з яких набуває успіху з ймовірністю p. Такі так/ні експерименти також називаються експериментами Бернуллі, або схемою Бернуллі, зокрема, якщо n=1 (кількість випробувань), то отримаємо Розподіл Бернуллі.
Означення
Функція імовірностей
У загальному випадку, якщо випадкова величина X відповідає біноміальному розподілу із параметрами n ∈ ℕ і p ∈ [0,1], записують X ~ B(n, p). Імовірність випадання точно k успішних випадків при n випробуваннях задається наступною функцією масової імовірності:

для k = 0, 1, 2, ..., n, де

це біноміальний коефіцієнт, названий так само як і сам розподіл. Цю формулу можна розуміти наступним чином. k успішних випадків виникають із імовірністю pk і n − k не успішних результатів випадають із імовірністю (1 − p)n − k. Однак, k успішних результатів можуть виникнути в будь-який момент серед даних n випробувань, тому існує різних способів розподілення k успішних випадків у послідовності з n спроб.

При створенні довідникових таблиць для біноміального розподілу, як правило таблицю заповнюють значеннями до n/2. Це тому що для k > n/2, можна розрахувати як імовірність для її доповнення, наступним чином

Якщо розглядати вираз f(k, n, p) як функцію від k, повинно існувати таке значення k, яке максимізує її. Це значення k можна знайти, якщо розрахувати:

і прирівняти до 1. Завжди існуватиме ціле число M яке задовольняє умові

f(k, n, p) є монотонно зростаючою при k < M і монотонно спадною для k > M, за винятком випадку де (n + 1)p є цілим. В даному випадку, існує два значення в яких f є максимальною: (n + 1)p і (n + 1)p − 1. M є найбільш імовірним результатом із усіх випробувань Бернуллі і називається модою.
Функція розподілу
Кумулятивна функція розподілу можна задати наступним чином:

де — найбільше ціле число, яке менше або дорівнює k.

Її також можна задати за допомогою регуляризованої неповної бета-функції, наступним чином:[2]

Числові характеристики
Зважаючи на співвідношення між біноміальним розподілом і розподілом Бернуллі, наведені нижче, а також на властивості математичного сподівання і дисперсії, можна отримати числові характеристики для біноміального розподілу без громіздких обчислень.
Математичне сподівання
Якщо X ~ B(n, p), така що, X є біноміально-розподіленою випадковою величиною для якої, n - загальна кількість експериментів, а p це імовірність що кожен експеримент призведе до успішного результату, тоді математичне сподівання для X дорівнюватиме:[3]

Наприклад, якщо n = 100, а p = 1/4, тоді середньою кількістю успішних випробувань буде 25.
Доведення: Розрахуємо середнє, μ, прямим способом виходячи із його визначення

і з теореми про біном Ньютона:

Середнє також можна вивести із рівняння де всі є випадковими величинами із розподілом Бернуллі із ( якщо i-ий експеримент є успішним і навпаки). Отримаємо:






Дисперсія
дисперсія біноміально-розподіленої випадкової величини:

Доведення: Нехай де всі є незалежними випадковими величинами із розподілом Бернуллі. Оскільки , отримаємо:


Мода
Як правило мода біноміального розподілу B(n, p) дорівнює , де позначає функцію округлення до найбільшого цілого числа, яке менше або дорівнює (тобто найближчого цілого числа, яке менше або дорівнює заданому числу. Однак, коли (n + 1)p є цілим, а p не є не 0 ні 1, тоді розподіл має дві моди: (n + 1)p і (n + 1)p − 1. Коли p дорівнює 0 або 1, тоді мода дорівнюватиме 0 і n відповідно. Ці випадки можна узагальнити наступним чином:



Доведення: Нехай

Для лише матиме не нульове значення . Для маємо, що і для . Це доводить, що мода дорівнює 0 для і для .








Нехай . Знайдемо, що

- .

З цього випливає

Тож коли є цілим, тоді і є модою. У випадку, коли , тоді модою буде лише .[4]




Медіана
Загалом, не існує єдиної формули для знаходження медіани біноміального розподілу, крім того вона може бути не унікальною. Однак існує декілька результатів для особливих випадків:
- Якщо np ціле число, тоді середнє, медіана і мода збігаються між собою і дорівнюють np.[5][6]
- Будь-яка медіана m обов'язково знаходиться в середині інтервалу ⌊np⌋ ≤ m ≤ ⌈np⌉.[7]
- Медіана m не може знаходитися далеко від середнього: |m − np| ≤ min{ ln 2, max{p, 1 − p} }.[8]
- Медіана буде єдиною і дорівнюватиме m = округлене(np) якщо |m − np| ≤ min{p, 1 − p} (крім випадку, коли p = 12 та n є непарними).[7]
- Якщо p = 1/2 та n непарні, будь-яке число m у інтервалі 12(n − 1) ≤ m ≤ 12(n + 1) є медіаною біноміального розподілу. Якщо p = 1/2 і n парні, тоді m = n/2 є єдиною медіаною.
Коваріація між двома біноміальними розподілами
Якщо одночасно спостерігалися дві біноміально розподілені випадкові величини X і Y, може бути корисним визначити їх коваріацію. Коваріація це

У випадку коли n = 1 (у випадку із схемою випробувань Бернуллі) XY не нульове лише коли обидві X і Y є одиницею, а μX і μY дорівнюють двом імовірностям. Якщо визначити pB як імовірність виникнення обох подій одночасно, отримаємо

і для n незалежних попарних випробувань

Якщо X і Y є однією і тією ж випадковою величиною, цей вираз спрощується до виразу визначення дисперсії, який наведено вище в цій статті.
Зв'язок з іншими розподілами
Нехай незалежні випадкові величини мають розподіл Бернуллі з параметром p, тобто , тоді випадкова величина має біноміальний розподіл з параметрами p, n, тобто .



Сума біноміально-розподілених величин
Якщо X ~ B(n, p) і Y ~ B(m, p) є незалежними випадковими величинами із біноміальним розподілом із однаковою ймовірністю p, тоді X + Y також буде біноміально-розподіленою величиною, і її розподілом буде Z=X+Y ~ B(n+m, p):

Однак, якщо X і Y не мають однакової імовірності p, тоді дисперсія суми величин буде меншою за дисперсію випадкової величини із біноміальним розподілом вигляду

Відношення двох біноміальних розподілів
Нехай p1 і p2 це імовірності успішного випробування у біноміальних розподілах B(X,n) і B(Y,m) відповідно. Нехай T = (X/n)/(Y/m).
Тоді log(T) є наближено нормально розподіленою величиною із середнім log(p1/p2) і дисперсією ((1/p1) - 1)/n + ((1/p2) - 1)/m.[9]
Умовні біноміальні величини
Якщо є X ~ B(n, p) і, при X існує деяка умовна величина Y ~ B(X, q), тоді Y є простою біноміальною величиною із розподілом Y ~ B(n, pq).
Наприклад, уявімо, що хтось кидає n м'ячів у кошик UX і виймає ті м'ячі, які успішно потрапили у кошик та кладе їх у інший кошик UY. Якщо p означає імовірність влучити в UX тоді X ~ B(n, p) це кількість м'ячів, які влучили у UX. Якщо q це імовірність потрапити у UY тоді кількістю м'ячів, які потраплять у UY буде Y ~ B(X, q) і таким чином Y ~ B(n, pq).
Оскільки і , за формулою повної імовірності,



Оскільки , то вищенаведене рівняння можна записати в наступній формі


Розбивши на множники і виділивши всі множники, які не залежать від суму можна звести до наступного:



Замінивши у вищенаведеному виразі, отримаємо


Помітимо, що вищенаведена сума (у дужках) дорівнює відповідно до теореми про біном Ньютона. Підставивши це у вираз, зрештою отримаємо


і таким чином , що і треба було довести.

Розподіл Бернуллі
Розподіл Бернуллі є особливим випадком біноміального розподілу, де n = 1. Символічно, X ~ B(1, p) має однакове середнє як і X ~ B(p). І навпаки, будь-який біноміальний розподіл, B(n, p), є розподілом суми із n випробувань Бернуллі, B(p), кожне з яких має однакову імовірність p.[10]
Нормальне наближення
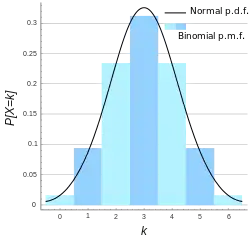
Якщо n є досить великим, тоді зсув біноміального розподілу не буде дуже великим. В такому випадку нормальний розподіл може бути виправданим наближенням для B(n, p).

а це базове наближення можна покращити використавши вдалу поправку для неперервності. Базове наближення значно стає кращим при збільшенні n (принаймні більше ніж 20) і буде кращим, коли p не є близькою до 0 або 1.[11] Можуть використовуватися різні емпіричні правила, які визначають чи є n достатньо великою, а значення p є досить далеким від крайніх значень нуля або одиниці:
- Одне із правил[11] говорить, що для n > 5 нормальне наближення буде адекватним, якщо абсолютне значення зсуву є строго меншим ніж 1/3; тобто, якщо

- Більш посилене правило говорить, що нормальна апроксимація буде прийнятною лише якщо всі можливі значення знаходяться в межах 3 стандартних відхилень від середнього значення; тобто, лише якщо
- Це правило про 3-стандартні відхилення буде еквівалентне наступним наведеним умовам, які також зумовлюють виконання і першого правила, описаного вище.


Правило є повністю еквівалентним вимозі, що


Якщо переставити множники отримаємо:

Оскільки , ми можемо піднести вирази у квадрат і поділити на відповідні множники та , і отримаємо бажані умови:


Зауважимо, що ці умови автоматично означають, що . З іншого боку, знову застосувавши квадратний корінь до нерівностей і поділивши на 3,


Віднявши другий набір нерівностей із першого, отримаємо:

тож, необхідне перше правило буде виконуватися,

- Іншим загальновживаним правилом є те, що обидва значення і мають бути більшими або дорівнювати 5. Однак, конкретне значення цього числа зустрічається різним в різних джерелах, і залежить від того наскільки хорошим має бути наближення. Зокрема, якщо використати значення 9 замість наведеного 5, правило призводить до результатів, що отримані в попередній частині розділу.


Припустимо, що обидва значення і є більшими за число 9. Оскільки , ми можемо стверджувати, що

Тепер необхідно лише поділити це на відповідні множники і , аби вивести альтернативну форму правила про 3-стандартні відхилення:


Наведемо приклад застосування поправку неперервності. Припустимо, що необхідно розрахувати Pr(X ≤ 8) для біноміально-розподіленої випадкової величини X. Якщо Y має розподіл заданий у вигляді нормального наближення, тоді Pr(X ≤ 8) можна наблизити за допомогою Pr(Y ≤ 8.5). Додавання 0.5 є поправкою неперервності; нормальне наближення без поправки дає менш точний результат.
Це наближення відоме як Локальна теорема Муавра — Лапласа, вона дозволяє значно зекономити час, якщо розрахунки виконуються вручну (точний розрахунок при великих n є дуже обтяжливим); історично, це було першим застосуванням нормального розподілу, яке було представлено у книзі Абрахама де Муавра Доктрина шансів в 1738. Сьогодні, її можна розглядати як наслідок із центральної граничної теореми оскільки B(n, p) є сумою із n незалежних, однаково розподілених випадкових величин із розподілом Бернуллі із параметром p. Цей факт є основою для перевірки статистичних гіпотез, "пропорційного z-тесту", для значення p використовуючи розрахунок x/n, що є пропорцією вибірки і оцінкою для p у загальних статистичних перевірках.[12]
Наприклад, припустимо, що хтось зробив вибірку по n людям із усієї популяції людей і запитав їх чи погоджуються вони з певним твердженням. Частка людей, яка погодиться з висловлюванням очевидно буде залежати від вибірки. Якщо групи із n людей були обрані повторно і дійсно випадковим чином, ця пропорція буде відповідати наближеному нормальному розподілу із середнім, що дорівнює істинному співвідношенню p того що люди погоджуються із твердженням в цій сукупності і матиме стандартне відхилення

Наближення Пуассона
Біноміальний розподіл наближається до Розподілу Пуассона якщо кількість спроб зростає до нескінченності в той час як добуток np залишається незмінним або p прямує до нуля. Тому, розподіл Пуассона із параметром λ = np може використовуватися для наближення біноміального розподілу B(n, p) якщо n має досить велике значення і p значно мала. Відповідно до двох правил, це наближення є добрим, якщо n ≥ 20 і p ≤ 0.05, або якщо n ≥ 100 і np ≤ 10.[13][14]
Граничні розподіли
- Теорема Пуассона: З тим як n наближається до ∞ і p наближається до 0 при сталому добутку np, Біноміальний розподіл B(n, p) наближається до розподілу Пуассона із математичним сподіванням λ = np.[13]
- Локальна теорема Муавра — Лапласа: З тим як n наближається до ∞ поки p залишається сталим, розподіл величини

- наближається до нормального розподілу із математичним сподіванням 0 і дисперсією 1. Цей результат в не суворій формі іноді формулюють як те, що розподіл величини X буде асимптотично нормальним із математичним сподіванням np і дисперсією np(1 − p). Цей результат є особливим випадком центральної граничної теореми.
Бета-розподіл
Бета-розподіли дозволяють мати сімейство апріорних розподілів імовірностей для біноміальних розподілів при Баєсовому виведенні:[15]
- .

Примітки
- Hamza, K. (1995). The smallest uniform upper bound on the distance between the mean and the median of the binomial and Poisson distributions. Statist. Probab. Lett. 23 21–25.
- Wadsworth, G. P. (1960). Introduction to Probability and Random Variables. New York: McGraw-Hill. с. 52.
- See Proof Wiki
- See also the answer to the question "finding mode in Binomial distribution"
- Neumann, P. (1966). Über den Median der Binomial- and Poissonverteilung. Wissenschaftliche Zeitschrift der Technischen Universität Dresden (German) 19: 29–33.
- Lord, Nick. (July 2010). "Binomial averages when the mean is an integer", The Mathematical Gazette 94, 331-332.
- Kaas, R.; Buhrman, J.M. (1980). Mean, Median and Mode in Binomial Distributions. Statistica Neerlandica 34 (1): 13–18. doi:10.1111/j.1467-9574.1980.tb00681.x.
- Hamza, K. (1995). The smallest uniform upper bound on the distance between the mean and the median of the binomial and Poisson distributions. Statistics & Probability Letters 23: 21–25. doi:10.1016/0167-7152(94)00090-U.
- Katz D. et al.(1978) Obtaining confidence intervals for the risk ratio in cohort studies. Biometrics 34:469–474
- Taboga, Marco. Lectures on Probability Theory and Mathematical Statistics. statlect.com. Процитовано 18 грудня 2017.
- Box, Hunter and Hunter (1978). Statistics for experimenters. Wiley. с. 130.
- NIST/SEMATECH, "7.2.4. Does the proportion of defectives meet requirements?" e-Handbook of Statistical Methods.
- NIST/SEMATECH, "6.3.3.1. Counts Control Charts", e-Handbook of Statistical Methods.
- Що стосується точності наближення Пуассона, див Novak S.Y. (2011) Extreme value methods with applications to finance. London: CRC/ Chapman & Hall/Taylor & Francis. ISBN 9781-43983-5746 ch. 4, and references therein.
- MacKay, David (2003). Information Theory, Inference and Learning Algorithms. Cambridge University Press; First Edition. ISBN 978-0521642989.
