Функція правдоподібності
У статистиці фу́нкція правдоподі́бності (англ. likelihood function, часто звана просто правдоподі́бністю, англ. likelihood) вимірює допасованість статистичної моделі до вибірки даних для заданих значень невідомих параметрів. Її утворюють зі спільного розподілу ймовірності цієї вибірки, але розглядають та використовують як функцію лише від цих параметрів, відтак розглядаючи випадкові змінні як зафіксовані в спостережуваних значеннях.[lower-alpha 1]
Функція правдоподібності описує гіперповерхню, чий пік, якщо він існує, представляє поєднання значень параметрів моделі, які максимізують імовірність витягування отриманої вибірки.[1] Процедура отримання цих аргументів максимізації функції правдоподібності є відомою як оцінювання максимальною правдоподібністю, яке, заради обчислювальної зручності, зазвичай застосовують з використанням натурального логарифму правдоподібності, відомого як фу́нкція логарифмі́чної правдоподі́бності (англ. log-likelihood function). Крім того, форма та кривина поверхні правдоподібності несуть інформацію про стійкість цих оцінок, через що як частину статистичного аналізу часто здійснюють побудову графіку функції правдоподібності.[2]
Варіант використання правдоподібності першим зробив Рональд Фішер,[3] який мав переконання, що він є самодостатньою системою для статистичного моделювання та висновування. Згодом Барнард та Бірнбаум очолили наукову школу, яка виступила за принцип правдоподібності, постулюючи, що вся доречна інформація для висновування міститься у функції правдоподібності.[4][5] Але навіть і в частотницькій та баєсовій статистиці функція правдоподібності відіграє́ фундаментальну роль.[6]
Означення
Функцію правдоподібності зазвичай означують по-різному для дискретних та неперервних розподілів імовірності. Загальне означення також є можливим, як обговорено нижче.
Дискретний розподіл імовірності
Нехай буде дискретною випадковою змінною з функцією маси ймовірності , залежною від параметра . Тоді функція




що розглядають як функцію від , є функцією правдоподібності для заданого результату випадкової змінної . Іноді ймовірність «значення випадкової змінної для значення параметра » записують як P(X = x | θ) або P(X = x; θ). не слід плутати з : правдоподібність дорівнює ймовірності спостерігання певного результату , коли справжнім значенням параметра є , і відтак дорівнює густині ймовірності над результатом , а не над параметром .



Приклад
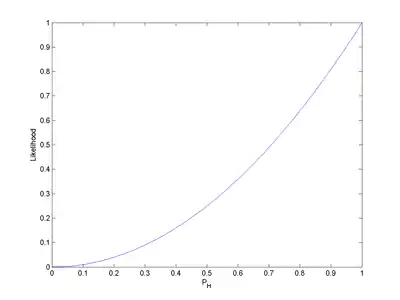

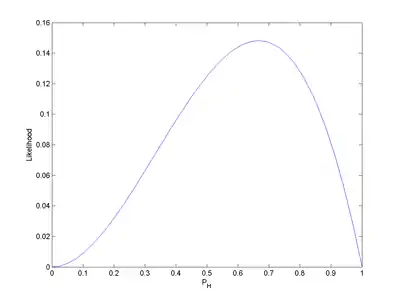

Розгляньмо просту статистичну модель підкидання монети: єдиний параметр , що виражає «справедливість» цієї монети. Цей параметр є ймовірністю того, що монета після підкидання впаде аверсом (англ. heads, H) догори. може набувати будь-якого значення в проміжку з 0.0 по 1.0. Для ідеально справедливої монети .


Уявімо підкидання справедливої монети двічі, й спостерігання наступних даних: два аверси за два підкидання (HH). Якщо виходити з припущення, що кожне наступне підкидання монети є н. о. р., то ймовірністю спостерігання HH є

Отже, за заданих даних спостережень HH, правдоподібністю того, що параметр моделі дорівнює 0.5, є 0.25. Математично це записують як

Це не те ж саме, що й сказати, що ймовірністю того, що , за заданого спостереження HH є 0.25. (Для цього ми можемо застосувати теорему Баєса, яка означає, що апостеріорна ймовірність є пропорційною до правдоподібності, помноженої на апріорну ймовірність.)
Припустімо, що ця монета не є справедливою, але натомість має . Тоді ймовірністю отримання двох аверсів є


Отже,

Загальніше, для кожного значення ми можемо обчислити відповідну правдоподібність. Результати таких обчислень показано на Рис. 1.
На Рис. 1. інтегралом правдоподібності над проміжком [0, 1] є 1/3. Це висвітлює важливий аспект правдоподібностей: правдоподібності не мають інтегруватися (чи підсумовуватися) до 1, на відміну від імовірностей.
Неперервний розподіл імовірності
Нехай буде випадковою змінною, що слідує абсолютно неперервному розподілові ймовірності з функцією густини , залежною від параметра . Тоді функція


що розглядають як функцію від , є функцією правдоподібності (параметра для заданого результату змінної ). Іноді функцію густини для «значення змінної для значення параметра » записують як . не слід плутати з : правдоподібність дорівнює густині ймовірності на певному результаті , коли справжнім значенням параметра є , і відтак вона дорівнює густині ймовірності над результатом , а не над параметром .

Загальний випадок
В теорії ймовірностей на основі теорії мір функцію густини означують як похідну Радона — Нікодима розподілу ймовірності відносно спільної домінантної міри.[7] Функція правдоподібності є цією густиною, інтерпретованою як функція від параметра (можливо, векторного), а не від можливих результатів.[8] Це забезпечує функцію правдоподібності для будь-якої статистичної моделі з усіма розподілами, чи то дискретними, абсолютно неперервними, сумішшю, чи чимось ще. (Правдоподібності буде можливо порівнювати, наприклад, для оцінювання параметрів, лише якщо вони є похідними Радона — Нікодима по відношенню до однієї й тієї ж домінантної міри.)
Наведене вище обговорення правдоподібності з дискретними ймовірностями є окремим випадком цього із застосуванням лічильної міри, яка робить імовірність будь-якого одиничного результату рівною густині ймовірності для цього результату.
Якщо не задано жодної події (немає даних), то ймовірністю, і відтак правдоподібністю, є 1.[джерело?] Будь-яка нетривіальна подія матиме нижчу правдоподібність.
Функція правдоподібності параметризованої моделі
Із багатьох застосувань ми розглянемо тут одне, що має широку теоретичну та практичну важливість. Для заданого параметризованого сімейства функцій густини ймовірності (або функцій маси ймовірності у випадку дискретних розподілів)

де є параметром, фу́нкцією правдоподі́бності (англ. likelihood function) є

що записують як

де є спостережуваним результатом експерименту. Іншими словами, коли розглядають як функцію від за незмінного , вона є функцією густини ймовірності, а коли її розглядають як функцію від за незмінного , вона є функцією правдоподібності.

Це не є тим же, що й імовірність того, що ці параметри є правильними за заданої спостережуваної вибірки. Намагання інтерпретувати правдоподібність гіпотези за заданого спостережуваного свідчення як її імовірність є поширеною помилкою з потенційно катастрофічними наслідками. Як приклад цього див. хибу обвинувача.
З геометричної точки зору, якщо ми розглядаємо як функцію від двох змінних, то сімейство розподілів імовірності можливо розглядати як сімейство кривих, паралельних до осі , тоді як сімейство функцій правдоподібності є перпендикулярними кривими, паралельними до осі .
Правдоподібності для неперервних розподілів
Застосування густини ймовірності у визначенні функції правдоподібності вище може бути пояснено наступним чином. Для заданих спостережень правдоподібність для проміжку , де є сталою, задають як . Зверніть увагу, що




- ,

оскільки є додатною та сталою. Оскільки


де є функцією густини ймовірності, з цього випливає, що
- .

Перша фундаментальна теорема інтегрального числення та правило Лопіталя разом забезпечують, що

Тоді

Отже,

і відтак максимізування густини ймовірності в є рівносильним максимізуванню правдоподібності конкретного спостереження .
Правдоподібності для змішаних неперервно-дискретних розподілів
Наведене вище може бути в простий спосіб розширено так, щоби дозволяти розгляд розподілів, що містять як дискретні, так і неперервні складові. Припустімо, що такий розподіл складається з якоїсь кількості дискретних мас імовірності та з густини , де сума всіх , додана до інтегралу , завжди є одиницею. За припущення, що можливо розрізняти спостереження, що відповідає одній з цих дискретних мас імовірності, від того, що відповідає складовій густини, функцію правдоподібності для спостереження з неперервної складової можливо розглядати наведеним вище чином. Для спостереження з дискретної складової функцією правдоподібності для спостереження з цієї дискретної складової є просто


де є індексом маси дискретної ймовірності, що відповідає спостереженню , оскільки максимізування маси ймовірності (або ймовірності) в є рівносильним максимізуванню правдоподібності цього конкретного спостереження.

Той факт, що функцію правдоподібності може бути визначено в спосіб, що включає не порівнянні внески (густина та маса ймовірності), випливає зі способу її визначення, в якому функцію правдоподібності визначено з точністю до сталої пропорційності, де ця «стала» може змінюватися зі спостереженням , але не з параметром .
Умови регулярності
В контексті оцінювання параметрів зазвичай виходять з того, що функція правдоподібності задовольняє певні умови, відомі як умови регулярності (англ. regularity conditions). З цих умов виходять у багатьох доведеннях, що включають функції правдоподібності, і їх потрібно перевіряти в кожному конкретному застосуванні. Для методу максимальної правдоподібності надзвичайно важливим є існування глобального максимуму функції правдоподібності. Згідно другої теореми Веєрштраса, неперервна функція правдоподібності на компактному просторі параметрів є достатньою для існування оцінювача максимальною правдоподібністю.[9] В той час як припущення про неперервність зазвичай виконується, припущення про компактність простору параметрів часто не виконується, оскільки межі справжніх значень параметрів є невідомими. В такому випадку ключову роль відіграє угнутість функції правдоподібності.
Конкретніше, якщо функція правдоподібності є двічі неперервно диференційовною на k-вимірному просторі параметрів , що вважають відкритою зв'язаною підмножиною , то унікальний максимум існує, якщо



- є від'ємно визначеною для кожного , для якого градієнт зникає, та
- , тобто функція правдоподібності наближується до сталої на межі простору параметрів, яка може включати точки на нескінченності, якщо є необмеженим.




Макелайнен та ін. доводять цей результат, застосовуючи теорію Морса, неформально звертаючись до властивості гірського перевалу.[10] Машкареньяш підтверджує їхнє доведення, застосовуючи теорему про гірський перевал.[11]
В доведенні слушності та асимптотичної нормальності оцінювача максимальною правдоподібністю роблять додаткові припущення про густи́ни ймовірностей, які складають основу певної функції правдоподібності. Ці умови було вперше встановлено Чандою.[12] Зокрема, для майже всіх , та для всіх

існують для всіх , щоби забезпечити існування розкладу Тейлора. По-друге, для майже всіх та для кожного мусить бути


де є такою, що . Ця обмеженість похідних є потрібною, щоби уможливити диференціювання під знаком інтегралу. І, нарешті, передбачається, що інформаційна матриця



є додатно визначеною, а є скінченною. Це забезпечує скінченність дисперсії внеску.[13]

Наведені вище умови є достатніми, але не необхідними. Тобто, модель, що не задовольняє ці умови регулярності, може мати, а може й не мати оцінювача максимальною правдоподібністю згаданих вище властивостей. Крім того, у випадку не незалежно або не однаково розподілених спостережень може бути потрібно очікувати додаткових властивостей.
Відношення правдоподібностей та відносна правдоподібність
Відношення правдоподібностей
Відно́шення правдоподі́бностей (англ. likelihood ratio) — це відношення будь-яких двох вказаних правдоподібностей, що часто записують як

Відношення правдоподібностей є центральним для правдоподібницької статистики: закон правдоподібності встановлює, що ступінь, до якого дані (що розглядають як свідчення) підтримують один параметр проти іншого, вимірюється відношенням правдоподібностей.
В частотницькому висновуванні відношення правдоподібності є основою для статистичного критерію, так званої перевірки відношенням правдоподібностей. Згідно леми Неймана — Пірсона, вона є найпотужнішою перевіркою для порівнювання двох простих гіпотез на заданому рівні значущості. Численні інші критерії можливо розглядати як перевірки відношенням правдоподібностей, або його наближеннями.[14] Асимптотичний розподіл логарифмічного відношення правдоподібностей, що розглядають як статистичний критерій, задано теоремою Уілкса.
Відношення правдоподібностей також має центральне значення в баєсовім висновуванні, де воно є відомим як коефіцієнт Баєса, і застосовується в правилі Баєса. Викладене в термінах шансів (англ. odds), правило Баєса полягає в тім, що апостеріорні шанси двох альтернатив, та , за умови події , є апріорними шансами, помноженими на відношення правдоподібностей. У вигляді рівняння:




Відношення правдоподібності не використовують в статистиці на основі ІКА напряму. Натомість використовують відносну правдоподібність моделей (див. нижче).
Відмінність від відношення шансів
Відношення правдоподібностей двох моделей, коли задано одну й ту ж подію, може бути протиставлено з шансами двох подій, коли задано одну й ту ж модель. В термінах параметризованої функції маси ймовірності , відношенням правдоподібностей двох параметрів та за заданого результату є




тоді як шансами двох результатів, та , за заданого значення параметра , є



Це підкреслює різницю між правдоподібностями та шансами: в правдоподібностях порівнюють моделі (параметри), тримаючи дані незмінними, тоді як в шансах порівнюють події (результати, дані), тримаючи незмінною модель.
Відношення шансів є відношенням двох умовних шансів (події, за заданої присутності або відсутності іншої події). Проте відношення шансів також можливо інтерпретувати як відношення двох відношень правдоподібностей, якщо розглядати одну з подій як спостережувану легше за іншу. Див. діагностичне відношення шансів, де результат перевірки для встановлення діагнозу спостерігати легше, ніж наявність або відсутність медичного стану, що лежить в його основі.
Функція відносної правдоподібності
Оскільки фактичне значення функції правдоподібності залежить від вибірки, часто зручно працювати зі стандартизованою мірою. Припустімо, що оцінкою максимальною правдоподібністю для параметра θ є . Відносні вірогідності (англ. plausibilities) інших значень θ може бути знайдено порівнюванням правдоподібностей цих інших значень з правдоподібністю . Відно́сну правдоподі́бність (англ. relative likelihood) θ означують як[15][16][17][18][19]


Таким чином, відносна правдоподібність є відношенням правдоподібностей (обговореним вище) з незмінним знаменником . Це відповідає унормуванню цієї правдоподібності, щоби вона мала за максимум 1.

Область правдоподібності
О́бласть правдоподі́бності (англ. likelihood region) — це множина всіх значень θ, чиї відносні правдоподібності є більшими або рівними заданому порогові. В термінах відсотків, p%-ву область правдоподібності для θ означують як[15][17][20]

Якщо θ є єдиним дійснозначним параметром, то p%-ва область правдоподібності зазвичай становить проміжок дійсних значень. Якщо ця область дійсно становить проміжок, то її називають про́міжком правдоподі́бності (англ. likelihood interval).[15][17][21]
Проміжки правдоподібності, та, загальніше, області правдоподібності використовують для проміжкового оцінювання в правдоподібницькій статистиці: вони є подібними до довірчих проміжків у частотницькій статистиці та ймовірних проміжків у баєсовій статистиці. Проміжки правдоподібності тлумачать безпосередньо в термінах відносної правдоподібності, а не в термінах ймовірності накриття (частотництво) чи апостеріорної ймовірності (баєсівство).
Для заданої моделі проміжки правдоподібності можливо порівнювати з довірчими проміжками. Якщо θ є єдиним дійснозначним параметром, то, за певних умов 14.65%-й проміжок правдоподібності (правдоподібність близько 1:7) для θ буде таким же, як і 95%-й довірчий проміжок (ймовірність накриття 19/20).[15][20] У дещо відмінному формулюванні, пристосованому для використання логарифмічних правдоподібностей (див. теорему Уілкса), перевірна статистика є подвоєною різницею логарифмічних правдоподібностей, а розподіл імовірності цієї перевірної статистики приблизно є розподілом хі-квадрат зі ступенями вільності, що дорівнюють різниці в ступенях вільності між цими двома моделями (тому проміжок правдоподібності e−2 є таким же, як і довірчий проміжок 0.954, за припущення, що різницею в ступенях вільності є 1).[20][21]
Правдоподібності, що усувають завадні параметри
В багатьох випадках правдоподібність є функцією більш ніж одного параметра, але інтерес зосереджується на оцінюванні лише одного, або щонайбільше декількох з них, з розглядом інших як завадних параметрів. Було розроблено декілька альтернативних підходів для усування таких завадних параметрів таким чином, щоби функцію правдоподібності могло бути записано як функцію лише параметра (або параметрів), що становлять інтерес: головними підходами є профільна (англ. profile), умовна (англ. conditional) та відособлена (англ. marginal) правдоподібності.[22][23] Ці підходи є також корисними, коли потрібно звужувати поверхні правдоподібності високої вимірності до одного чи двох параметрів, що становлять інтерес, щоби уможливити побудову графіку.
Профільна правдоподібність
Можливо знижувати розмірності, зосереджуючи функцію правдоподібності на підмножині параметрів шляхом виражання завадних параметрів як функцій від параметрів, що становлять інтерес, і заміни їх у функції правдоподібності.[24][25] Загалом, для функції правдоподібності, що залежить від вектору параметрів , який можливо розбити на , і де відповідність можливо визначити явно, зосереджування знижує обчислювальне навантаження первинної задачі максимізації.[26]



Наприклад, в лінійній регресії з нормально розподіленими похибками, , вектор коефіцієнтів може бути розбито на (а матрицю плану, відповідно, на ). Максимізування відносно видає функцію оптимального значення . Із застосуванням цього результату оцінювач максимальною правдоподібністю для може бути виведено як







де є проєктивною матрицею . Цей результат є відомим як теорема Фріша — Во — Ловелла.


Оскільки графічно процедура зосереджування є рівнозначною нарізанню поверхні правдоподібності по хребту значень завадного параметра , яке максимізує функцію правдоподібності, створюючи ізометричний профіль функції правдоподібності для заданого , результат цієї процедури є також відомим як про́фільна правдоподі́бність (англ. profile likelihood).[27][28] На додачу до графічного зображування, профільну правдоподібність також можливо використовувати для обчислювання довірчих проміжків, які часто мають кращі властивості на малих вибірках, ніж основані на асимптотичних стандартних похибках, обчислюваних із повної правдоподібності.[29][30]
Умовна правдоподібність
Іноді для завадних параметрів можливо знайти достатню статистику, і обумовлювання цією статистикою дає в результаті правдоподібність, що не залежить від завадних параметрів.[31]
Один із прикладів трапляється в таблицях 2×2, де обумовлювання усіма чотирма відособленими підсумками веде до умовної правдоподібності на основі нецентрального гіпергеометричного розподілу. Цей вид обумовлювання є також основою точного тесту Фішера.
Відособлена правдоподібність
Іноді ми можемо усувати завадні параметри, розглядаючи правдоподібність на основі лише частини інформації з даних, наприклад, застосуванням набору порядків замість числових значень. Інший приклад трапляється в лінійних змішаних моделях, де розгляд правдоподібності лише для залишків після допасовування фіксованих впливів веде до оцінювання залишковою максимальною правдоподібністю складових відхилення.
Часткова правдоподібність
Часткова правдоподібність (англ. partial likelihood) — це таке пристосування повної правдоподібності, що в ньому має місце лише частина параметрів (параметри, що становлять інтерес).[32] Вона є ключовою складовою моделі пропорційних ризиків: з використанням обмеження на функцію ризиків, правдоподібність не містить фігури ризику в часі.
Добуток правдоподібностей
Правдоподібність за заданих двох або більше незалежних подіях є добутком правдоподібностей кожної з цих окремих подій:

Це випливає з означення незалежності в теорії ймовірностей: імовірністю трапляння двох незалежних подій за заданої моделі є добуток цих імовірностей.
Це є особливо важливим, коли події походять від незалежних однаково розподілених випадкових змінних, таких як незалежні спостереження або вибирання з повертанням. В такій ситуації функція правдоподібності розкладається на добуток окремих функцій правдоподібностей.
Порожній добуток має значення 1, яке відповідає правдоподібності за відсутності події, що становить 1: перед будь-якими даними правдоподібністю завжди є 1. Це є подібним до рівномірного апріорного в баєсовій статистиці, але в правдоподібницькій статистиці це не є некоректним апріорним, оскільки правдоподібності не інтегруються.
Логарифмічна правдоподібність
Детальніші відомості з цієї теми ви можете знайти в статті Логарифмічна ймовірність.
Фу́нкція логарифмі́чної правдоподі́бності (англ. log-likelihood function) — це логарифмічне перетворення функції правдоподібності, яке часто позначують маленькою l або , на противагу до великої L або для самої правдоподібності. Оскільки угнутість відіграє́ в максимізації ключову роль, а більшість поширених розподілів імовірності, зокрема, експоненційного сімейства, є лише логарифмічно угнутими,[33][34] зазвичай набагато зручніше працювати з функціями логарифмічних правдоподібностей. Також, логарифмічна правдоподібність є особливо зручною в оцінюванні максимальною правдоподібністю. Оскільки логарифми є строго висхідними функціями, максимізування правдоподібності є рівнозначним максимізуванню логарифмічної правдоподібності.


За умови незалежності кожної з подій, загальна логарифмічна правдоподібність перетину дорівнює сумі логарифмічних правдоподібностей окремих подій. Це є аналогічним тому фактові, що загальна логарифмічна ймовірність є сумою логарифмічних імовірностей цих окремих подій. На додачу до математичної зручності, яку це дає, процес додавання логарифмічних правдоподібностей має інтуїтивну інтерпретацію, яку часто виражають як «підтримку» даними. Коли параметри оцінюють, застосовуючи логарифмічну правдоподібність для оцінювання максимальною правдоподібністю, кожну точку даних використовують додаванням до підсумкової логарифмічної правдоподібності. Оскільки ці дані можливо розглядати як свідчення, що підтримують оцінювані параметри, цей процес можливо інтерпретувати як «підтримка від незалежних свідчень додається», а логарифмічна правдоподібність є «вагою свідчення». Якщо інтерпретувати від'ємну логарифмічну правдоподібність як власну інформацію, або несподіваність, то підтримка (логарифмічна правдоподібність) моделі, за заданої події, є від'ємною несподіваністю цієї події за заданої моделі: модель підтримувано подією в тій мірі, в якій ця подія не є несподіваною за заданої моделі.
Вибір основи b для логарифму відповідає виборові масштабу.[lower-alpha 2] Зазвичай використовують натуральний логарифм, й основу залишають незмінною, але іноді основу роблять змінною, в разі чого записуючи основу як , коефіцієнт β можливо інтерпретувати як холодність.[lower-alpha 3]

Логарифм відношення правдоподібностей дорівнює різниці логарифмічних правдоподібностей:

Точно як і правдоподібність, що за відсутності події є 1, логарифмічною правдоподібністю за відсутності події є 0, що відповідає значенню нульової суми: без бодай якихось даних не існує підтримки для жодної моделі.
Рівняння правдоподібності
Якщо функція логарифмічної правдоподібності є гладкою, то її градієнт відносно параметра, відомий як внесок і записуваний як , існує й дозволяє застосовувати диференціальне числення. Базовим способом максимізувати диференційовну функцію є знаходити стаціонарні точки (такі, де її похідна є нульовою). Оскільки похідна суми є просто сумою похідних, а похідна добутку вимагає правила добутку, простіше обчислювати стаціонарні точки логарифмічної правдоподібності окремих подій, ніж правдоподібності окремих подій.

Рівняння, що визначає стаціонарна точка функції внеску, слугують оцінними рівняннями для оцінювача максимальною правдоподібністю.

В цьому сенсі оцінювач максимальною правдоподібністю неявно визначається значенням в оберненої функції , де є d-вимірним евклідовим простором. Шляхом застосування теореми про обернену функцію можливо показати, що є однозначно означеною у відкритому околі навколо з імовірністю, що прямує до одиниці, а є слушною оцінкою . Як наслідок, існує така послідовність , що асимптотично майже напевно, і .[35] Аналогічний результат можливо встановити, застосувавши теорему Ролля.[36][37]








Друга похідна, обчислювана в , відома як інформація за Фішером, визначає кривину поверхні правдоподібності,[38] і відтак показуючи прецизійність оцінки.[39]
Експоненційні сімейства
Детальніші відомості з цієї теми ви можете знайти в статті Експоненційне сімейство.
Логарифмічна правдоподібність є також надзвичайно корисною для експоненційних сімейств розподілів, до яких можуть входити багато поширених параметричних розподілів імовірностей. Функція розподілу ймовірності (й відтак функція правдоподібності) для експоненційних сімейств містить добутки множників, що містять піднесення до степеня. Логарифм такої функції є сумою добутків, знов-таки простішою для диференціювання за первинну функцію.
Експоненційне сімейство — це таке, чия функція густини ймовірності має вигляд (для деяких функцій, із позначенням через внутрішнього добутку):


Кожен із цих членів має інтерпретацію,[lower-alpha 4] але простий перехід від імовірності до правдоподібності та взяття логарифмів дає суму

та відповідають зміні координат, тож у цих координатах логарифмічна правдоподібність експоненційного сімейства задається простою формулою



Словами, логарифмічна правдоподібність експоненційного сімейства є внутрішнім добутком природного параметра та достатньої статистики , мінус коефіцієнт унормування (логарифмічна статистична сума) . Таким чином, наприклад, оцінку максимальною правдоподібністю може бути обчислено взяттям похідних достатньої статистики T та логарифмічної статистичної суми A.



Приклад: гамма-розподіл
Гамма-розподіл — це експоненційне сімейство з двома параметрами, та . Його функцією правдоподібності є



Знаходження оцінки максимальної правдоподібності для єдиного спостережуваного значення виглядає дещо складним. З його логарифмом працювати набагато простіше:

Щоби максимізувати логарифмічну правдоподібність, ми спершу беремо часткову похідну за :

Якщо є ряд незалежних спостережень , то спільною логарифмічною правдоподібністю буде сума окремих логарифмічних правдоподібностей, а похідною цієї суми буде сума похідних всіх окремих логарифмічних правдоподібностей:


Щоби завершити процедуру максимізування для спільної логарифмічної правдоподібності, це рівняння встановлюють в нуль, і розв'язують для :

Тут позначує оцінку максимальною правдоподібністю, а є вибірковим середнім спостережень.


Походження та інтерпретація
Історичні зауваження
Детальніші відомості з цієї теми ви можете знайти в статті Історія статистики та Історія теорії ймовірності.
Термін англ. likelihood (правдоподібність) був у вжитку в англійській щонайменше з середньоанглійської.[40] Його формальне застосування для позначення конкретної функції в математичній статистиці було запропоновано Рональдом Фішером[41] у двох дослідницьких працях, опублікованих 1921[42] та 1922[43] року. Праця 1921 року запровадила те, що тепер називають «проміжком правдоподібності». Праця 1922 року запровадила термін «метод максимальної правдоподібності». Цитуючи Фішера,
| 1922 року я запропонував термін «правдоподібність», з огляду на той факт, що по відношенню до [параметра], вона не є ймовірністю, й не підкоряється законам імовірності, в той же час привносячи до задачі раціонального обирання серед можливих значень [параметра] відношення, подібне до того, що ймовірність привносить до задачі передбачування подій в іграх випадку... Проте, в той час як по відношенню до психологічного судження правдоподібність має певну схожість з імовірністю, ці два поняття є цілком різними... Оригінальний текст (англ.) [I]n 1922, I proposed the term ‘likelihood,’ in view of the fact that, with respect to [the parameter], it is not a probability, and does not obey the laws of probability, while at the same time it bears to the problem of rational choice among the possible values of [the parameter] a relation similar to that which probability bears to the problem of predicting events in games of chance....Whereas, however, in relation to psychological judgment, likelihood has some resemblance to probability, the two concepts are wholly distinct....” |
Поняття правдоподібності не слід плутати з імовірністю, як зазначено сером Рональдом Фішером,
| Я наголошую на цьому, оскільки, незважаючи на наголос, який я завжди робив на відмінності між імовірністю та правдоподібністю, все ще існує тенденція ставитися до правдоподібності так, ніби вона є чимось на кшталт імовірності. Першим результатом відтак є те, що існує дві різні міри раціонального переконання, що відповідають різним випадкам. Знаючи сукупність, ми можемо виражати наше неповне знання або наші неповні очікування про вибірку в термінах імовірності; знаючи вибірку, ми можемо виражати наші неповні знання про сукупність у термінах правдоподібності. Оригінальний текст (англ.) I stress this because in spite of the emphasis that I have always laid upon the difference between probability and likelihood there is still a tendency to treat likelihood as though it were a sort of probability. The first result is thus that there are two different measures of rational belief appropriate to different cases. Knowing the population we can express our incomplete knowledge of, or expectation of, the sample in terms of probability; knowing the sample we can express our incomplete knowledge of the population in terms of likelihood. |
Фішерове винайдення статистичної правдоподібності було реакцією на раніший вид міркування, званий оберненою ймовірністю.[46] Його застосування терміну «правдоподібність» зафіксувало значення цього терміну в межах математичної статистики.
Е. В. Ф. Едвардс (1972) заклав аксіоматичну основу для застосування логарифмічного відношення правдоподібностей як міри відносної підтри́мки (англ. support) однієї гіпотези проти іншої. Фу́нкцією підтри́мки (англ. support function) в такому разі є натуральний логарифм функції правдоподібності. Обидва терміни застосовують у філогенетиці, але їх не були прийнято в загальному трактуванні теми статистичних даних.[47]
Інтерпретації за різних засад
Серед статистиків нема єдиної думки про те, якими повинні бути засади статистики. Існує чотири головні парадигми, які було запропоновано як засади: частотництво, баєсівство, правдоподібництво, та на основі ІКА.[6] Для кожних із цих запропонованих засад інтерпретація правдоподібності є різною. Ці чотири інтерпретації описано в підрозділах нижче.
Баєсова інтерпретація
У баєсовім висновуванні, хоча й можливо говорити про правдоподібність будь-якого висловлення чи випадкової змінної за заданої іншої випадкової змінної, наприклад, про правдоподібність значення параметра чи статистичної моделі (див. відособлену правдоподібність) за заданих даних або іншого свідчення,[48][49][50][51] функція правдоподібності залишається тією ж сутністю з додатковими інтерпретаціями (i) умовної густини ймовірності даних за заданого параметра (оскільки параметр тоді є випадковою змінною), та (ii) міри кількості інформації, що несуть дані про значення параметра або навіть про модель.[48][49][50][51][52] Внаслідок введення ймовірнісної структури на просторі параметрів або сукупності моделей є можливим, щоби значення параметра або статистична модель мали велике значення правдоподібності для заданих даних, але в той же час низьку ймовірність, і навпаки.[50][52] Таке часто трапляється в контексті медицини.[53] Згідно правила Баєса, правдоподібність, коли розглядати її як умовну густину, можливо множини на густину апріорної ймовірності параметра й потім унормовувати, щоби отримувати густину апостеріорної ймовірності.[48][49][50][51][52] Загальніше, правдоподібність невідомої величини за заданої іншої невідомої величини є пропорційною до ймовірності за заданої .[48][49][50][51][52]

Правдоподібницька інтерпретація
У частотницькій статистиці функція правдоподібності сама по собі є статистикою, яка узагальнює окремий зразок із сукупності, й чиє обчислюване значення залежить від вибору декількох параметрів θ1... θp, де p є кількістю параметрів у якійсь вже обраній статистичній моделі. Значення правдоподібності слугує критерієм якості для вибору, зробленого для параметрів, і набір параметрів з максимальною правдоподібністю є найкращим вибором за доступних даних.
Конкретним розрахунком правдоподібності є ймовірність того, що буде призначено саме спостережуваний зразок, за припущення, що обрана модель та значення цих декількох параметрів θ дають точне наближення частотного розподілу сукупності, з якої було витягнуто цей спостережуваний зразок. Евристично має сенс, що добрим вибором параметрів є той, який видає для фактично спостережуваного зразка максимально можливу апостеріорну (лат. post-hoc) ймовірність трапляння. Теорема Уілкса визначає це евристичне правило кількісно, показуючи, що різниця між логарифмом правдоподібності, породженим значеннями параметрів оцінки, та логарифмом правдоподібності, породженим «істинними» (але невідомими) значеннями параметрів сукупності, має розподіл χ².
Оцінка максимальною правдоподібністю кожного незалежного зразка є окремою оцінкою «істинного» набору параметрів, що описує сукупність, з якої роблять вибірку. Послідовні оцінки від багатьох незалежних зразків гуртуватимуться разом з «істинним» набором значень параметрів сукупності, прихованим десь поміж них. Різницю між логарифмами максимальної правдоподібності та правдоподібностей суміжних наборів параметрів можна використовувати для малювання довірчої області на графіку, чиїми координатами є параметри θ1... θp. Ця область оточує оцінку максимальною правдоподібністю, і всі точки (набори параметрів) всередині цієї області відрізняються в логарифмічній правдоподібності щонайбільше на якесь встановлене значення. Розподіл χ², заданий теоремою Уілкса, перетворює різниці логарифмічних правдоподібностей цієї області у «рівень довіри» до того, що «істинний» набір параметрів сукупності лежить всередині. Мистецтво обирання цієї встановленої різниці логарифмічних правдоподібностей полягає в тім, щоби робити рівень довіри прийнятно високим, в той же час тримаючи область прийнятно малою (вузька область оцінок).
В процесі спостерігання додаткових даних, замість використовувати їх для здійснення незалежних оцінок, їх можливо поєднувати з попередніми зразками в єдину об'єднану вибірку, і цю велику вибірку можливо використовувати для нової оцінки максимальною правдоподібністю. Зі збільшенням розміру цієї об'єднаної вибірки розмір області правдоподібності з таким же рівнем довіри скорочується. Врешті-решт, або розмір довірчої області стане майже єдиною точкою, або буде вибрано всю сукупність. В обох випадках, оцінений набір параметрів буде по суті таким же, як і набір параметрів сукупності.
Інтерпретація на основі ІКА
У парадигмі ІКА правдоподібність інтерпретують у контексті теорії інформації.[54][55][56]
Див. також
- Коефіцієнт Баєса
- Умовна ентропія
- Умовна ймовірність
- Емпірична правдоподібність
- Принцип правдоподібності
- Перевірка відношенням правдоподібностей
- Правдоподібницька статистика
- Максимальна правдоподібність
- Принцип максимальної ентропії
- Псевдоправдоподібність
- Функція внеску
Зауваження
- Хоча їх і використовують часто як синоніми у неформальному контексті, у статистиці терміни «правдоподібність» та «імовірність» мають відмінні значення. Імовірність є властивістю зразка, а саме, наскільки імовірним є отримати певний зразок для заданого значення параметрів розподілу. Правдоподібність є властивістю значень параметрів. Див. Valavanis, Stefan (1959). Probability and Likelihood. Econometrics : An Introduction to Maximum Likelihood Methods. New York: McGraw-Hill. с. 24–28. OCLC 6257066. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Масштабним коефіцієнтом є ; див. Логарифм § Зміна основи
- «Холодність» є також відомою як термодинамічна бета, або обернена температура. Приклади варіювання холодності див. в інформаційному критерієві Ватанабе — Акаіке та функції softmax у статистичній механіці.
- Див. Експоненційне сімейство § Інтерпретація

Примітки
- Myung, In Jae (2003). Tutorial on Maximum Likelihood Estimation. Journal of Mathematical Psychology 47 (1): 90–100. doi:10.1016/S0022-2496(02)00028-7. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Box, George E. P.; Jenkins, Gwilym M. (1976). Time Series Analysis : Forecasting and Control. San Francisco: Holden-Day. с. 224. ISBN 0-8162-1104-3. (англ.)
- Fisher, R. A. Statistical Methods for Research Workers. §1.2. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Edwards, A. W. F. (1992). Likelihood. Johns Hopkins University Press. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Berger, James O.; Wolpert, Robert L. (1988). The Likelihood Principle. Hayward: Institute of Mathematical Statistics. с. 19. ISBN 0-940600-13-7. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Bandyopadhyay, P. S.; Forster, M. R., ред. (2011). Philosophy of Statistics. North-Holland Publishing. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Billingsley, Patrick (1995). Probability and Measure (вид. Third). John Wiley & Sons. с. 422–423. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Shao, Jun (2003). Mathematical Statistics (вид. 2nd). Springer. §4.4.1. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Gouriéroux, Christian; Monfort, Alain (1995). Statistics and Econometric Models. New York: Cambridge University Press. с. 161. ISBN 0-521-40551-3. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Mäkeläinen, Timo; Schmidt, Klaus; Styan, George P. H. (1981). On the Existence and Uniqueness of the Maximum Likelihood Estimate of a Vector-Valued Parameter in Fixed-Size Samples. Annals of Statistics 9 (4): 758–767. JSTOR 2240844. (англ.)
- Mascarenhas, W. F. (2011). A Mountain Pass Lemma and its implications regarding the uniqueness of constrained minimizers. Optimization 60 (8–9): 1121–1159. doi:10.1080/02331934.2010.527973. (англ.)
- Chanda, K. C. (1954). A Note on the Consistency and Maxima of the Roots of Likelihood Equations. Biometrika 41 (1–2): 56–61. doi:10.2307/2333005. (англ.)
- Greenberg, Edward; Webster, Charles E. Jr. (1983). Advanced Econometrics: A Bridge to the Literature. New York: John Wiley & Sons. с. 24–25. ISBN 0-471-09077-8. (англ.)
- Buse, A. (1982). The Likelihood Ratio, Wald, and Lagrange Multiplier Tests: An Expository Note. The American Statistician 36 (3a): 153–157. doi:10.1080/00031305.1982.10482817. (англ.)
- Kalbfleisch, J. G. (1985). Probability and Statistical Inference. Springer. (§9.3). (англ.)
- Azzalini, A. (1996). Statistical Inference—Based on the likelihood. Chapman & Hall. ISBN 9780412606502. (§1.4.2). (англ.)
- Sprott, D. A. (2000), Statistical Inference in Science, Springer (chap. 2). (англ.)
- Davison, A. C. (2008), Statistical Models, Cambridge University Press (§4.1.2). (англ.)
- Held, L.; Sabanés Bové, D. S. (2014). Applied Statistical Inference—Likelihood and Bayes. Springer. (§2.1). (англ.)
- Rossi, R. J. (2018). Mathematical Statistics. Wiley. с. 267. (англ.)
- Hudson, D. J. (1971). Interval estimation from the likelihood function. Journal of the Royal Statistical Society, Series B 33 (2): 256–262. (англ.)
- Pawitan, Yudi (2001). In All Likelihood: Statistical Modelling and Inference Using Likelihood. Oxford University Press. (англ.)
- Wen Hsiang Wei. Generalized Linear Model - course notes. Taichung, Taiwan: Tunghai University. с. Chapter 5. Процитовано 1 жовтня 2017. (англ.)
- Amemiya, Takeshi (1985). Concentrated Likelihood Function. Advanced Econometrics. Cambridge: Harvard University Press. с. 125–127. ISBN 978-0-674-00560-0. (англ.)
- Davidson, Russell; MacKinnon, James G. (1993). Concentrating the Loglikelihood Function. Estimation and Inference in Econometrics. New York: Oxford University Press. с. 267–269. ISBN 978-0-19-506011-9. (англ.)
- Gourieroux, Christian; Monfort, Alain (1995). Concentrated Likelihood Function. Statistics and Econometric Models. New York: Cambridge University Press. с. 170–175. ISBN 978-0-521-40551-5. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Pickles, Andrew (1985). An Introduction to Likelihood Analysis. Norwich: W. H. Hutchins & Sons. с. 21–24. ISBN 0-86094-190-6. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Bolker, Benjamin M. (2008). Ecological Models and Data in R. Princeton University Press. с. 187–189. ISBN 978-0-691-12522-0. (англ.)
- Aitkin, Murray (1982). Direct Likelihood Inference. GLIM 82: Proceedings of the International Conference on Generalised Linear Models. Springer. с. 76–86. ISBN 0-387-90777-7. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Venzon, D. J.; Moolgavkar, S. H. (1988). A Method for Computing Profile-Likelihood-Based Confidence Intervals. Journal of the Royal Statistical Society. Series C (Applied Statistics) 37 (1): 87–94. doi:10.2307/2347496. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Kalbfleisch, J. D.; Sprott, D. A. (1973). Marginal and Conditional Likelihoods. Sankhyā: The Indian Journal of Statistics. Series A 35 (3): 311–328. JSTOR 25049882. (англ.)
-
Cox, D. R. (1975). Partial likelihood. Biometrika 62 (2): 269–276. MR 0400509. doi:10.1093/biomet/62.2.269. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Kass, Robert E.; Vos, Paul W. (1997). Geometrical Foundations of Asymptotic Inference. New York: John Wiley & Sons. с. 14. ISBN 0-471-82668-5. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Papadopoulos, Alecos (25 вересня 2013). Why we always put log() before the joint pdf when we use MLE (Maximum likelihood Estimation)?. Stack Exchange. (англ.)
- Foutz, Robert V. (1977). On the Unique Consistent Solution to the Likelihood Equations. Journal of the American Statistical Association 72 (357): 147–148. doi:10.1080/01621459.1977.10479926. (англ.)
- Tarone, Robert E.; Gruenhage, Gary (1975). A Note on the Uniqueness of Roots of the Likelihood Equations for Vector-Valued Parameters. Journal of the American Statistical Association 70 (352): 903–904. doi:10.1080/01621459.1975.10480321. (англ.)
- Rai, Kamta; Van Ryzin, John (1982). A Note on a Multivariate Version of Rolle's Theorem and Uniqueness of Maximum Likelihood Roots. Communications in Statistics. Theory and Methods 11 (13): 1505–1510. doi:10.1080/03610928208828325. (англ.)
- Rao, B. Raja (1960). A formula for the curvature of the likelihood surface of a sample drawn from a distribution admitting sufficient statistics. Biometrika 47 (1–2): 203–207. doi:10.1093/biomet/47.1-2.203. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Ward, Michael D.; Ahlquist, John S. (2018). Maximum Likelihood for Social Science : Strategies for Analysis. Cambridge University Press. с. 25–27. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - "likelihood", Shorter Oxford English Dictionary (2007). (англ.)
- Hald, A. (1999). On the history of maximum likelihood in relation to inverse probability and least squares. Statistical Science 14 (2): 214–222. JSTOR 2676741. doi:10.1214/ss/1009212248. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Fisher, R.A. (1921). On the "probable error" of a coefficient of correlation deduced from a small sample. Metron 1: 3–32. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Fisher, R.A. (1922). On the mathematical foundations of theoretical statistics. Philosophical Transactions of the Royal Society A 222 (594–604): 309–368. JFM 48.1280.02. JSTOR 91208. doi:10.1098/rsta.1922.0009. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Klemens, Ben (2008). Modeling with Data: Tools and Techniques for Scientific Computing. Princeton University Press. с. 329. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Fisher, Ronald (1930). Inverse Probability. Mathematical Proceedings of the Cambridge Philosophical Society 26 (4): 528–535. doi:10.1017/S0305004100016297. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Fienberg, Stephen E (1997). Introduction to R.A. Fisher on inverse probability and likelihood. Statistical Science 12 (3): 161. doi:10.1214/ss/1030037905. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Royall, R. (1997). Statistical Evidence. Chapman & Hall. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - I. J. Good: Probability and the Weighing of Evidence (Griffin 1950), §6.1 (англ.)
- H. Jeffreys: Theory of Probability (3rd ed., Oxford University Press 1983), §1.22 (англ.)
- E. T. Jaynes: Probability Theory: The Logic of Science (Cambridge University Press 2003), §4.1 (англ.)
- D. V. Lindley: Introduction to Probability and Statistics from a Bayesian Viewpoint. Part 1: Probability (Cambridge University Press 1980), §1.6 (англ.)
- A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, D. B. Rubin: Bayesian Data Analysis (3rd ed., Chapman & Hall/CRC 2014), §1.3 (англ.)
- Sox, H. C.; Higgins, M. C.; Owens, D. K. (2013). Medical Decision Making (вид. 2nd). Wiley. chapters 3–4. doi:10.1002/9781118341544. (англ.)
- Akaike, H. (1985). Prediction and entropy. У Atkinson, A. C.; Fienberg, S. E.. A Celebration of Statistics. Springer. с. 1–24. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Sakamoto, Y.; Ishiguro, M.; Kitagawa, G. (1986). Akaike Information Criterion Statistics. D. Reidel. Part I. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Burnham, K. P.; Anderson, D. R. (2002). Model Selection and Multimodel Inference: A practical information-theoretic approach (вид. 2nd). Springer-Verlag. chap. 7. Проігноровано невідомий параметр
|mode=(довідка) (англ.)
Література
- Azzalini, Adelchi (1996). Likelihood. Statistical Inference Based on the Likelihood. Chapman and Hall. с. 17–50. ISBN 0-412-60650-X. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Boos, Dennis D.; Stefanski, L. A. (2013). Likelihood Construction and Estimation. Essential Statistical Inference : Theory and Methods. New York: Springer. с. 27–124. ISBN 978-1-4614-4817-4. doi:10.1007/978-1-4614-4818-1_2. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Edwards, A. W. F. (1992). Likelihood (вид. Expanded). Johns Hopkins University Press. ISBN 0-8018-4443-6. Проігноровано невідомий параметр
|orig-year=(довідка); Проігноровано невідомий параметр|mode=(довідка) (англ.) - King, Gary (1989). The Likelihood Model of Inference. Unifying Political Methodology : the Likehood Theory of Statistical Inference. Cambridge University Press. с. 59–94. ISBN 0-521-36697-6. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Lindsey, J. K. (1996). Likelihood. Parametric Statistical Inference. Oxford University Press. с. 69–139. ISBN 0-19-852359-9. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Rohde, Charles A. (2014). Introductory Statistical Inference with the Likelihood Function. Berlin: Springer. ISBN 978-3-319-10460-7. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Royall, Richard (1997). Statistical Evidence : A Likelihood Paradigm. London: Chapman & Hall. ISBN 0-412-04411-0. Проігноровано невідомий параметр
|mode=(довідка) (англ.) - Ward, Michael D.; Ahlquist, John S. (2018). The Likelihood Function: A Deeper Dive. Maximum Likelihood for Social Science : Strategies for Analysis. Cambridge University Press. с. 21–28. ISBN 978-1-316-63682-4. Проігноровано невідомий параметр
|mode=(довідка) (англ.)