Взаємна інформація
У теорії ймовірностей та теорії інформації взає́мна інформа́ція (англ. mutual information, MI) двох випадкових змінних — це міра взаємної залежності між цими двома змінними. Конкретніше, вона визначає «кількість інформації» (в таких одиницях, як шеннони, що зазвичай називають бітами), отримуваної про одну випадкову змінну через спостерігання іншої випадкової змінної. Поняття взаємної інформації нерозривно пов'язане з ентропією випадкової змінної, фундаментальним поняттям теорії інформації, яке кількісно оцінює очікувану «кількість інформації», що міститься у випадковій змінній.
| Теорія інформації |
|---|
 |
|
|
|








Не обмежуючись, як коефіцієнт кореляції, дійснозначними випадковими змінними, взаємна інформація є загальнішою, і визначає, наскільки подібним є спільний розподіл до добутків розкладених відособлених розподілів . Взаємна інформація — це математичне сподівання поточкової взаємної інформації (англ. pointwise mutual information, PMI).


Визначення
Формально взаємну інформацію двох дискретних випадкових змінних та може бути визначено як[1]

де є функцією спільного розподілу ймовірностей та , а та є функціями відособлених розподілів імовірності та відповідно.


У випадку неперервних випадкових змінних підсумовування замінюється визначеним подвійним інтегралом:[1]

де тепер є функцією густини спільної ймовірності та , а та є функціями густини відособлених імовірностей та відповідно.
Якщо застосовується логарифм за основою 2, то одиницею вимірювання взаємної інформації є біт.
Обґрунтування
Інтуїтивно, взаємна інформація вимірює інформацію, яку поділяють та : вона вимірює, наскільки знання однієї з цих змінних зменшує невизначеність щодо іншої. Наприклад, якщо та є незалежними, то знання не дає жодної інформації про , і навпаки, тому їхня взаємна інформація дорівнює нулеві. З іншого боку, якщо є детермінованою функцією від , і є детермінованою функцією від , то вся інформація, що передає змінна , є спільною з : знання визначає значення , і навпаки. В результаті, в цьому випадку взаємна інформація є тим же, що й невизначеність, яка міститься окремо в (або ), а саме ентропія (або ). Більше того, ця взаємна інформація і є такою ж, як і ентропія та як ентропія . (Дуже особливим випадком цього є такий, коли та є однією й тією ж випадковою змінною.)
Взаємна інформація є мірою притаманної залежності, вираженої в спільному розподілі та , по відношенню до спільного розподілу та за припущення незалежності. Взаємна інформація відтак вимірює залежність у наступному сенсі: , якщо і лише якщо та є незалежними випадковими змінними. Це легко побачити в одному напрямку: якщо та є незалежними, то , і тому



Крім того, взаємна інформація є невід'ємною (тобто, , див. нижче) і симетричною (тобто, , див. нижче).


Відношення до інших величин
Невід'ємність
Застосувавши нерівність Єнсена до визначення взаємної інформації, ми можемо показати, що є невід'ємною, тобто,[1]
Симетричність
Відношення до умовної та спільної ентропій
Взаємну інформацію може бути рівнозначно виражено як

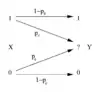
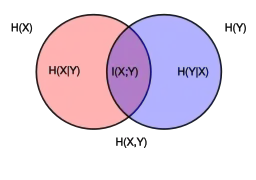
де та є відособленими ентропіями, та є умовними ентропіями, а є спільною ентропією та . Зверніть увагу на аналогію з об'єднанням, різницею та перетином двох множин, яку показано в діаграмі Венна. В термінах каналу зв'язку, в якому вихід є зашумленою версією входу , ці відношення узагальнено на малюнку нижче.

Оскільки є невід'ємною, як наслідок, . Тут ми наводимо докладне виведення :



Доведення інших наведених вище тотожностей є схожими на це.
Інтуїтивно, якщо ентропію розглядати як міру невизначеності випадкової змінної, то є мірою того, що не каже про . Це є «кількістю невизначеності , яка залишається після того, як стала відомою », і, отже, праву частину другого з цих рівнянь можливо читати як «кількість невизначеності за вирахуванням кількості невизначеності , яка залишається після того, як стала відомою », що рівнозначно «кількість невизначеності , яка усувається, коли стає відомою ». Це підтримує інтуїтивне значення взаємної інформації як кількості інформації (тобто, зниження невизначеності), яке знання однієї з змінних забезпечує стосовно іншої.
Зауважте, що в дискретному випадку і, отже, . Таким чином, , і можна сформулювати основний принцип, що змінна містить про себе щонайменше стільки ж інформації, скільки могла би забезпечити будь-яка інша змінна. Це відповідає подібним пов'язаним результатам.



Відношення до відстані Кульбака — Лейблера
Взаємну інформацію також може бути виражено як відстань Кульбака — Лейблера добутку відособлених розподілів двох випадкових змінних та від спільного розподілу цих випадкових змінних :

Крім того, нехай . Тоді


Зауважте, що тут відстань Кульбака — Лейблера передбачає інтегрування лише за випадковою змінною , і вираз тепер є випадковою змінною в . Таким чином, взаємну інформацію можна також розуміти як математичне сподівання відстані Кульбака — Лейблера одновимірного розподілу змінної від умовного розподілу змінної відносно : що більш відмінними в середньому є розподіли та , то більшим є приріст інформації.


Баєсове оцінювання взаємної інформації
Як робити баєсове оцінювання взаємної інформації спільного розподілу на основі зразків цього розподілу, є добре зрозумілим. Першою працею про те, як це робити, яка також показала, як робити баєсове оцінювання багато чого іншого в теорії інформації, понад взаємну інформацію, була праця Волперта 1995 року.[2] Наступні дослідники цей аналіз перевивели[3] та розширили.[4] Див. нещодавню працю[5] на основі апріорного, спеціально пристосованого для оцінювання взаємної інформації як такої.
Припущення про незалежність
Формулювання взаємної інформації в термінах відстані Кульбака — Лейблера ґрунтується на зацікавленні в порівнянні з повністю розкладеним діадним добутком . В багатьох задачах, таких як розклад невід'ємних матриць, цікавлять менш екстремальні розклади, а саме, хочуть порівнювати з низькоранговим матричним наближенням у якійсь невідомій змінній , тобто, до якої міри можна мати


Або ж може цікавити дізнатися, скільки інформації несе понад свій розклад. В такому випадку додаткова інформація, що несе повний розподіл відносно цього матричного розкладу, задається відстанню Кульбака — Лейблера:

Стандартне визначення взаємної інформації відтворюється в екстремальному випадку, коли процес має для лише одне значення.

Різновиди
Для задоволення різних потреб було запропоновано кілька варіацій взаємної інформації. Серед них є нормалізовані варіанти та узагальнення до понад двох змінних.
Метрика
Багато застосувань вимагають метрики, тобто міри відстань між парами точок. Величина

задовольняє властивості метрики (нерівність трикутника, невід'ємність, нерозрізнюваність та симетрію). Ця метрика відстані також відома як різновидність інформації.
Якщо є дискретними випадковими змінними, то всі члени ентропії є невід'ємними, тому і можливо визначити унормовану відстань



Метрика є універсальною метрикою, в тому сенсі, що якщо будь-яка інша міра відстані розмістить та поруч, то й також розглядатиме їх як близькі.[6]

Підключення визначень показує, що

У теоретико-множинній інтерпретації інформації (див. малюнок в умовній ентропії) це є фактично відстанню Жаккара між та .
Нарешті,

також є метрикою.
Умовна взаємна інформація
Детальніші відомості з цієї теми ви можете знайти в статті Умовна взаємна інформація.
Іноді корисно виражати взаємну інформацію двох випадкових змінних відносно третьої.

що може бути спрощено як

Обумовлювання третьою випадковою змінною може збільшувати або зменшувати взаємну інформацію, але для дискретних спільно розподілених випадкових змінних завжди залишається істинним


Цей результат застосовувався як основний будівельний блок для доведення інших нерівностей в теорії інформації.
Багатовимірна взаємна інформація
Детальніші відомості з цієї теми ви можете знайти в статті Багатовимірна взаємна інформація.
Було запропоновано декілька узагальнень взаємної інформації для понад двох випадкових змінних, такі як повна кореляція та інформація взаємодії. Якщо розглядати ентропію Шеннона як знакову міру в контексті інформаційних діаграм, як описано в статті «Теорія інформації та теорія міри», то єдиним визначенням багатовимірної взаємної інформації, яке має сенс,[джерело?] є наступне:

і для


де (як вище) ми визначаємо

(Це визначення багатовимірної взаємної інформації є ідентичним визначенню інформації взаємодії, за виключенням зміни знаку, коли число випадкових змінних є непарним.)
Застосування
Сліпе застосування інформаційних схем для виведення вищевказаного визначення[джерело?] зазнавало критики,[чиєї?] і дійсно, воно знайшло досить обмежене практичне застосування, оскільки важко уявити або зрозуміти значення цієї кількості для великого числа випадкових змінних. Вона може бути нульовою, додатною або від'ємною для будь-якого непарного числа змінних

Одна зі схем багатовимірного узагальнення, яка максимізує взаємну інформацію між спільним розподілом та іншими цільовими змінними, виявилася корисною в обиранні ознак.[7]
Взаємну інформацію також застосовують в галузі обробки сигналів як міру подібності двох сигналів. Наприклад, метрика взаємної інформації ознак (англ. FMI, feature mutual information)[8] — це міра продуктивності злиття зображень, яка застосовує взаємну інформацію для вимірювання кількості інформації, яку злите зображення містить про первинні зображення. Код MATLAB для цієї метрики можна знайти за адресою [9].
Спрямована інформація
Спрямована інформація, , вимірює кількість інформації, що протікає з процесу до , де позначує вектор , а позначує . Термін «спрямована інформація» (англ. directed information) було започатковано Джеймсом Мессі, й визначено як





- .

Зауважте, що якщо , то спрямована інформація стає взаємною інформацією. Спрямована інформація має багато застосувань у задачах, в яких важливу роль відіграє причинність, таких як пропускна здатність каналу зі зворотним зв'язком.[10][11]

Унормовані варіанти
Унормовані варіанти взаємної інформації забезпечуються коефіцієнтами обмеження,[12] коефіцієнтом невизначеності[13] або вправністю (англ. proficiency):[14]
- та


Ці два коефіцієнти не обов'язково дорівнюють один одному. В деяких випадках може бути бажаною симетрична міра, така як наступна міра надмірності (англ. redundancy):[джерело?]

яка досягає нульового мінімуму, коли змінні є незалежними, і максимального значення

коли одна зі змінних стає абсолютно надмірною при знанні іншої. Див. також надмірність інформації. Іншою симетричною мірою є симетрична невизначеність (Witten та Frank, 2005), яку задають як

що представляє середнє гармонійне двох коефіцієнтів невизначеності .[13]

Якщо розглядати взаємну інформацію як окремий випадок повної кореляції або двоїстої повної кореляції, то унормованими версіями відповідно є
- та


Ця унормована версія також відома як показник якості інформації (англ. Information Quality Ratio, IQR), що дає кількісну оцінку інформації змінної на основі іншої змінної відносно повної невизначеності:[15]

Існує унормування,[16] яке випливає з першого розгляду взаємної інформації як аналогу коваріації (таким чином, ентропія Шеннона є аналогом дисперсії). Потім унормована взаємна інформація розраховується подібно до коефіцієнту кореляції Пірсона,

Зважені варіанти
В традиційному формулюванні взаємної інформації

кожна подія чи об'єкт, вказані як , зважуються відповідною ймовірністю . Це передбачає, що всі об'єкти або події є рівнозначними без врахування ймовірностей їх настання. Проте в деяких застосуваннях може бути так, що певні об'єкти або події є більш значущими, ніж інші, або що деякі шаблони зв'язків є семантично важливішими за інші.

Наприклад, детерміноване відображення може розглядатися як сильніше за детерміноване відображення , хоча ці відношення видадуть однакову взаємну інформацію. Це відбувається тому, що взаємна інформація взагалі не чутлива до жодного природного впорядкування значень змінних (Cronbach, 1954, Coombs, Dawes & Tversky, 1970, Lockhead, 1970), і тому взагалі не чутлива до форми відносного відображення між зв'язаними змінними. Якщо бажано, щоби перше відношення — яке показує узгодженість за всіма значеннями змінних — оцінювалося вище, ніж друге відношення, то можна використовувати наступну зважену взаємну інформацію (Guiasu, 1977).



яка поміщає вагу на імовірність кожного збігу значень змінних, . Це дозволяє робити так, щоби деякі ймовірності могли нести більше або менше важливості за інші, тим самим дозволяючи кількісно виразити відповідні чинники цілісності (англ. holistic) або виразності (нім. Prägnanz). У наведеному вище прикладі застосування більших відносних ваг для , і матиме ефект вищої оцінки інформативності для відношення , ніж для відношення , що може бути бажаним в деяких випадках розпізнавання образів тощо. Ця зважена взаємна інформація є вираженням зваженої відстані Кульбака — Лейблера, яка, як відомо, може набувати від'ємних значень для деяких входів,[17] і є приклади, де зважена взаємна інформація також набуває від'ємних значень.[18]




Скоригована взаємна інформація
Детальніші відомості з цієї теми ви можете знайти в статті Скоригована взаємна інформація.
Розподіл імовірності можна розглядати як розбиття множини. Можна запитати: якщо множину було розбито випадковим чином, яким буде розподіл імовірностей? Яким буде математичне сподівання взаємної інформації? Скоригована взаємна інформація (англ. adjusted mutual information, AMI) віднімає математичне сподівання взаємної інформації таким чином, що вона дорівнює нулеві, коли два різних розподіли носять випадковий характер, і одиниці, коли два розподіли збігаються. Скоригована взаємна інформація визначається за аналогією зі скоригованим індексом Ренда двох різних розбиттів множини.
Абсолютна взаємна інформація
З допомогою ідей колмогоровської складності можна розглядати взаємну інформацію двох послідовностей незалежно від будь-якого розподілу ймовірностей:

Встановлення того, що ця величина є симетричною з точністю до логарифмічного множника (), потребує ланцюгового правила для колмогоровскої складності (Li та Vitányi, 1997). Наближення цієї величини через стиснення може може застосовуватися для визначення міри відстані для виконання ієрархічного кластерування послідовностей без жодного знання про предметну область цих послідовностей (Cilibrasi та Vitányi, 2005).

Лінійна кореляція
На відміну від коефіцієнтів кореляції, наприклад, коефіцієнту кореляції моменту добутку, взаємна інформація містить інформацію про всю залежність — лінійну й нелінійну, — а не просто про лінійну залежність, як міри коефіцієнтів кореляції. Тим не менш, у вузькому випадку, в якому спільний розподіл та є двовимірним нормальним розподілом (за припущення, зокрема, що обидва відособлені розподіли розподілені нормально), існує точний взаємозв'язок між та коефіцієнтом кореляції (Гельфанд та Яглом, 1957).



Наведене вище рівняння може бути виведено для двовимірного нормального розподілу наступним чином:

Отже,

Для дискретних даних
Коли та обмежено перебуванням у дискретному числі станів, то дані спостережень підсумовують до таблиці спряженості зі змінною рядків (або ) та змінною стовпців (або ). Взаємна інформація є однією з мір асоційовності або кореляції між змінними рядків і стовпців. До інших мір асоційовності належать статистики критерію хі-квадрат Пірсона, статистики G-критерію тощо. Фактично, взаємна інформація дорівнює статистиці G-критерію, поділеній на , де є розміром вибірки.




Застосування
В багатьох застосуваннях потрібно максимізувати взаємну інформацію (тим самим збільшуючи взаємозалежність), що часто рівнозначне мінімізації умовної ентропії. До прикладів належать:
- У технології пошукових рушіїв взаємну інформацію між фразами та контекстами використовують як ознаку для кластерування методом k-середніх для виявлення семантичних кластерів (понять).[19]
- У телекомунікаціях пропускна спроможність каналу дорівнює взаємній інформації, максимізованій над усіма вхідними розподілами.
- Було запропоновано процедури розрізнювального навчання для прихованих марковських моделей на основі критерію максимальної взаємної інформації (англ. maximum mutual information, MMI).
- Передбачування вторинної структури РНК з множинного вирівнювання послідовностей.
- Передбачування філогенетичного профілювання з попарної присутності або відсутності функціонально пов'язаних генів.
- Взаємну інформацію застосовували в машинному навчанні як критерій для обирання ознак та перетворень ознак. Її можливо застосовувати для характеризування як доречності, так і надлишковості змінних, як в обиранні ознак за мінімальною надлишковістю.
- Взаємну інформацію використовують у визначенні подібності двох різних кластерувань набору даних. Як така, вона пропонує деякі переваги над традиційним індексом Ренда.
- Взаємну інформацію слів часто використовують як функцію значущості для обчислення колокації в корпусній лінгвістиці. Це має додаткову складність в тому, що жоден випадок слова не є випадком для двох різних слів; швидше, рахують випадки, в яких 2 слова трапляються суміжно або в безпосередній близькості; це дещо ускладнює розрахунок, оскільки очікувана ймовірність трапляння одного слова в межах слів від іншого росте з .
- Взаємну інформацію застосовують у медичній візуалізації для зіставлення зображень. Для заданого еталонного зображення (наприклад, результату сканування мозку) та другого зображення, яке потрібно покласти до тієї ж системи координат, що й еталонне зображення, це зображення деформується доти, доки взаємну інформацію між ним та еталонним зображенням не буде максимізовано.
- Виявляння фазової синхронізації в аналізі часових рядів.
- Метод інфомакс для нейронних мереж та іншого машинного навчання, включно з алгоритмом методу незалежних компонент на основі інфомаксу.
- В теоремі про вкладення із затримками усереднену взаємну інформацію використовують для визначення параметру вкладальної затримки.
- Взаємну інформацію між генами в даних експресійних мікрочипів використовує алгоритм ARACNE для відбудови генних мереж.
- В термінах взаємної інформації може бути виражено парадокс Лошмідта у статистичній механіці.[20][21] Лошмідт зазначив, що може бути неможливим визначити фізичний закон, позбавлений зворотності (наприклад, другий закон термодинаміки), лише з таких фізичних законів, які цю зворотність мають. Він вказав, що в Η-теоремі Больцмана було зроблено припущення, що швидкості частинок в газі були постійно некорельованими, що усунуло природну зворотність в ній. Може бути показано, що якщо систему описано густиною ймовірності у фазовому просторі, то з теореми Ліувілля випливає, що спільна інформація (від'ємна спільна ентропія) розподілу залишається сталою в часі. Спільна інформація дорівнює взаємній інформації плюс сума всіх відособлених інформацій (від'ємних відособлених ентропій) для координат кожної з частинок. Припущення Больцмана рівнозначне ігноруванню взаємної інформації в обчисленні ентропії, що дає в результаті термодинамічну ентропію (ділену на сталу Больцмана).
- Взаємну інформацію використовують для навчання структури баєсових мереж/динамічних баєсових мереж, що, як вважають, пояснюють причинно-наслідковий зв'язок між випадковими змінними, прикладом чого може слугувати інструментарій GlobalMIT:[22] навчання глобально оптимальної динамічної баєсової мережі з критерієм взаємної інформації (англ. Mutual Information Test, MIT).
- Популярна функція витрат у навчанні дерев рішень.
- Взаємну інформацію використовують у космології, щоби перевіряти вплив великомасштабних середовищ на властивості галактик у Galaxy Zoo.
- Взаємну інформацію використовували в фізиці Сонця для виведення сонячного диференціального ротора, карти відхилень часу руху сонячних плям, часово-відстаннєвої діаграми з вимірювань спокійного Сонця[23]
Див. також
- Поточкова взаємна інформація
- Квантова взаємна інформація
Примітки
- Cover, T.M.; Thomas, J.A. (1991). Elements of Information Theory (вид. Wiley). ISBN 978-0-471-24195-9. (англ.)
- Wolpert, D.H.; Wolf, D.R. (1995). Estimating functions of probability distributions from a finite set of samples. Physical Review E. (англ.)
- Hutter, M. (2001). Distribution of Mutual Information. Advances in Neural Information Processing Systems 2001. (англ.)
- Archer, E.; Park, I.M.; Pillow, J. (2013). Bayesian and Quasi-Bayesian Estimators for Mutual Information from Discrete Data. Entropy. (англ.)
- Wolpert, D.H; DeDeo, S. (2013). Estimating Functions of Distributions Defined over Spaces of Unknown Size. Entropy. (англ.)
- Kraskov, Alexander; Stögbauer, Harald; Andrzejak, Ralph G.; Grassberger, Peter (2003). «Hierarchical Clustering Based on Mutual Information». arXiv:q-bio/0311039. (англ.)
- Christopher D. Manning; Prabhakar Raghavan; Hinrich Schütze (2008). An Introduction to Information Retrieval. Cambridge University Press. ISBN 0-521-86571-9. (англ.)
- Haghighat, M. B. A.; Aghagolzadeh, A.; Seyedarabi, H. (2011). A non-reference image fusion metric based on mutual information of image features. Computers & Electrical Engineering 37 (5): 744–756. doi:10.1016/j.compeleceng.2011.07.012. (англ.)
- Feature Mutual Information (FMI) metric for non-reference image fusion - File Exchange - MATLAB Central. www.mathworks.com. Процитовано 4 квітня 2018. (англ.)
- Massey, James (1990). Causality, Feedback And Directed Informatio (ISITA). (англ.)
- Permuter, Haim Henry; Weissman, Tsachy; Goldsmith, Andrea J. (February 2009). Finite State Channels With Time-Invariant Deterministic Feedback. IEEE Transactions on Information Theory 55 (2): 644–662. arXiv:cs/0608070. doi:10.1109/TIT.2008.2009849. (англ.)
- Coombs, Dawes та Tversky, 1970.
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007). Section 14.7.3. Conditional Entropy and Mutual Information. Numerical Recipes: The Art of Scientific Computing (вид. 3rd). New York: Cambridge University Press. ISBN 978-0-521-88068-8. (англ.)
- White, Jim; Steingold, Sam; Fournelle, Connie. Performance Metrics for Group-Detection Algorithms Interface 2004. (англ.)
- Wijaya, Dedy Rahman; Sarno, Riyanarto; Zulaika, Enny. Information Quality Ratio as a novel metric for mother wavelet selection. Chemometrics and Intelligent Laboratory Systems 160: 59–71. doi:10.1016/j.chemolab.2016.11.012. (англ.)
- Strehl, Alexander; Ghosh, Joydeep (2002). Cluster Ensembles – A Knowledge Reuse Framework for Combining Multiple Partitions. The Journal of Machine Learning Research 3 (Dec): 583–617. (англ.)
- Kvålseth, T. O. (1991). The relative useful information measure: some comments. Information sciences 56 (1): 35–38. doi:10.1016/0020-0255(91)90022-m. (англ.)
- Pocock, A. (2012). Feature Selection Via Joint Likelihood (PDF) (Thesis). (англ.)
- Parsing a Natural Language Using Mutual Information Statistics by David M. Magerman and Mitchell P. Marcus (англ.)
- Hugh Everett Theory of the Universal Wavefunction, Thesis, Princeton University, (1956, 1973), pp 1–140 (page 30) (англ.)
- Everett, Hugh (1957). Relative State Formulation of Quantum Mechanics. Reviews of Modern Physics 29: 454–462. Bibcode:1957RvMP...29..454E. doi:10.1103/revmodphys.29.454. Архів оригіналу за 27 жовтня 2011. Процитовано 28 червня 2016. (англ.)
- GlobalMIT на Google Code
- Keys, Dustin; Kholikov, Shukur; Pevtsov, Alexei A. (February 2015). Application of Mutual Information Methods in Time Distance Helioseismology. Solar Physics 290 (3): 659–671. Bibcode:2015SoPh..290..659K. arXiv:1501.05597. doi:10.1007/s11207-015-0650-y. (англ.)
Джерела
- Cilibrasi, R.; Vitányi, Paul (2005). Clustering by compression (PDF). IEEE Transactions on Information Theory 51 (4): 1523–1545. doi:10.1109/TIT.2005.844059. (англ.)
- Cronbach, L. J. (1954). On the non-rational application of information measures in psychology. У Quastler, Henry. Information Theory in Psychology: Problems and Methods. Glencoe, Illinois: Free Press. с. 14–30. (англ.)
- Coombs, C. H.; Dawes, R. M.; Tversky, A. (1970). Mathematical Psychology: An Elementary Introduction. Englewood Cliffs, New Jersey: Prentice-Hall. (англ.)
- Church, Kenneth Ward; Hanks, Patrick (1989). Word association norms, mutual information, and lexicography. Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics. (англ.)
- Гельфанд, И. М.; Яглом, А. М. (1957). О вычислении количества информации о случайной функции, содержащейся в другой такой функции. Успехи математических наук 12 (1(73)): 3–52. (рос.)
- Guiasu, Silviu (1977). Information Theory with Applications. McGraw-Hill, New York. ISBN 978-0-07-025109-0. (англ.)
- Li, Ming; Vitányi, Paul (February 1997). An introduction to Kolmogorov complexity and its applications. New York: Springer-Verlag. ISBN 0-387-94868-6. (англ.)
- Lockhead, G. R. (1970). Identification and the form of multidimensional discrimination space. Journal of Experimental Psychology 85 (1): 1–10. PMID 5458322. doi:10.1037/h0029508. (англ.)
- David J. C. MacKay. Information Theory, Inference, and Learning Algorithms Cambridge: Cambridge University Press, 2003. ISBN 0-521-64298-1 (available free online) (англ.)
- Haghighat, M. B. A.; Aghagolzadeh, A.; Seyedarabi, H. (2011). A non-reference image fusion metric based on mutual information of image features. Computers & Electrical Engineering 37 (5): 744–756. doi:10.1016/j.compeleceng.2011.07.012. (англ.)
- Athanasios Papoulis. Probability, Random Variables, and Stochastic Processes, second edition. New York: McGraw-Hill, 1984. (See Chapter 15.) (англ.)
- Witten, Ian H. & Frank, Eibe (2005). Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann, Amsterdam. ISBN 978-0-12-374856-0. (англ.)
- Peng, H.C., Long, F., and Ding, C. (2005). Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence 27 (8): 1226–1238. PMID 16119262. doi:10.1109/tpami.2005.159. CS1 maint: Multiple names: authors list (link) (англ.)
- Andre S. Ribeiro; Stuart A. Kauffman; Jason Lloyd-Price; Bjorn Samuelsson; Joshua Socolar (2008). Mutual Information in Random Boolean models of regulatory networks. Physical Review E 77 (1). Bibcode:2008PhRvE..77a1901R. arXiv:0707.3642. doi:10.1103/physreve.77.011901. (англ.)
- Wells, W.M. III; Viola, P.; Atsumi, H.; Nakajima, S.; Kikinis, R. (1996). Multi-modal volume registration by maximization of mutual information (PDF). Medical Image Analysis 1 (1): 35–51. PMID 9873920. doi:10.1016/S1361-8415(01)80004-9. Архів оригіналу за 6 вересня 2008. Процитовано 28 червня 2016. (англ.)
- Pandey, Biswajit; Sarkar, Suman (2017). How much a galaxy knows about its large-scale environment?: An information theoretic perspective. Monthly Notices of the Royal Astronomical Society Letters 467: L6. Bibcode:2017MNRAS.467L...6P. arXiv:1611.00283. doi:10.1093/mnrasl/slw250. (англ.)
Література
- Габидулин, Э. М., Пилипчук, Н. И. Лекции по теории информации. — М.: МФТИ, 2007. — 214 с. — ISBN 5-7417-0197-3 (рос.)
